| |||||||||
|  | ||||||||
| |||||||||
| | ||||||||
| kategória | ||||||||||
|
|
||||||||||
|
|
||
TUDOMÁNYOS DIÁKKÖRI DOLGOZAT
nUSTAT SEJTMAGDETEKTÁLÓ ÉS ELEMZÕ RENDSZER
A TDK dolgozat fõ témája a gyógyszerkutató cégek által végzett állatkísérletek számítógépes elemzése. A kísérletek során a kísérleti állatokat bizonyos anyagokkal kezelik, majd egy meghatározott idõ után "feláldozzák". A boncolt állati szervbõl (pl.: vesébõl) mintát vesznek (szövetminta), melybõl 3-4 mm vastag szeletet üveglapra helyeznek. Így lehetõség van a szövetmintákat tárgylemezenként különbözõ festékkel megfesteni. Az ily módon készült mintákat egy speciális digitális mikroszkóppal digitalizálják.
A dolgozat részletesen ismerteti az általunk kifejlesztett NuStat programban alkalmazott algoritmusok mûködési elvét. A program segítségével hasznos funkciókkal segíthetjük a toxikopatológusok munkáját. A program automatikusan detektálja a digitalizált szövetmintákon a megfestett sejtmagokat, majd azokon morfometriai méréseket végez, végül pedig statisztikailag elemzi a mért eredményeket, s dokumentálja is azokat.
A statisztikai elemzés által tized másodperc alatt eldõl, hogy az aktuális képen található sejtmagok szignifikánsan eltérnek-e az adatbázisban tárolt normál (nem kezelt állatokból vett minta) sejtmagok mintáitól, vagy sem.
A sejt a földi élet legkisebb szerkezeti egysége, amely önálló mûködésre képes valamint életjelenségeket mutat, anyagcserét folytat és szaporodik. Vannak olyan organizmusok, mint a baktériumok és egysejtûek, amelyek csak egy sejtbõl állnak, az ember illetve a többsejtû állatok viszont akár 100 000 milliárd (1014) sejtbõl is állhatnak. A sejtet egy külsõ membrán vagy más néven sejthártya határolja, melyen belül egy folyékony szerves anyag található.
A legegyszerûbb sejtes felépítésû élõlények a prokarióták. Ezeknek nincs belsõ membránnal határolt sejtmagjuk. A sejtmagvas élõlények az eukarióták. Fénymikroszkóppal vizsgálva az eukariót 222j99c a sejtek két fõ részbõl állnak:
- a magból (latinul: nucleus)
- és a magot körülvevõ citoplazmából
A sejtmagot két lemezbõl álló maghártya veszi körül, melyen pórusok helyezkednek el. Ezen keresztül történik a citoplazma és a mag közötti anyagáramlás. A mag belsejében jól elkülöníthetõ a magvacska (latinul: nucleolus) és a fonalas szerkezetû DNS-t és fehérjéket tartalmazó kromatin állomány.
![]()
A sejtmag mérete különbözõ lehet, és alakja is meglehetõsen változó, attól függõen, hogy milyen környezetben (pl. a test melyik szervében) található. A leggyakoribb a gömb forma. Minél aktívabb egy sejtmag, annál nagyobb a felülete és a térfogata közötti arány.
A vesében lévõ sejtmagok jellemzõen kör alakúak. Ezt a tulajdonságot vettük alapul a feladat megoldása során. A program kódját Delphi környezetben fejlesztettük.
A dolgozat alapját egy régebben kiírt bioinformatikai verseny adta, melynek feladatkiírása lényegében a felvetett probléma számítógépes alkalmazásának megírását jelentette. A rendelkezésre álló szövetminták 8-8 képbõl álltak, melyek kezelt illetve normál állat veséjébõl vett minta alapján készültek.
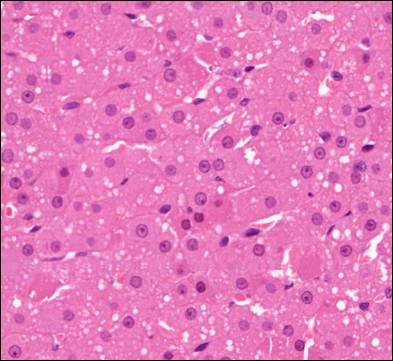
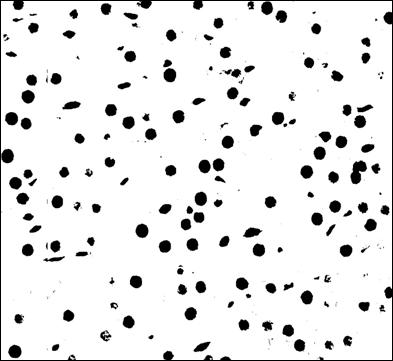
. kép: Egy kezelt állati vesébõl vett szövetminta
A szövetmintán (1. kép) a sejtmagok elég jól elhatárolódnak a háttértõl. Vannak olyan szennyezõdésbõl eredõ foltok, amelyek nem sejtmagok, ezek nehezítik a probléma megoldást. Olyan sejtmagok is vannak a mintában, amelyek éppen az osztódás valamelyik fázisában vannak, és még nem vált külön a két sejtmag.
Az elsõ lépés szinte minden képfeldolgozási probléma esetében, hogy leszûkítsük az információk tömegét, és csak azzal a résszel foglalkozzunk részletesebben, ami a feladat megoldása szempontjából szükséges. Ez a felesleges területek elhagyását jelenti, ami általában több lépésben történik, és feladat specifikus.
Az elõ-feldolgozás lényege tulajdonképpen az, hogy a sejtmagok valamint a háttér - valamilyen módszer alkalmazása után - egyértelmûen elkülönüljenek egymástól, és különválasztásuk egy automatizált módszerrel információvesztés nélkül mûködjön.
A szövetmintákat egy úgynevezett Hematoxilin-Eozin nevû festékkel színezik. Egészen pontosan ez két festési folyamatot jelent egymás után. A Hematoxilin-t a sejtmagok megfestésére használjak, melynek következtében kék színnel válik láthatóvá. Ezután következik az Eozin-festés, melynek eredménye, hogy a színtelen sejtplazma rózsaszínné válik. Az Eozin hatással van a már kék színû sejtmagokra is, és ezért lesz sötét lilás színû, ahogyan az 1. képen látható.
Az információk tehát a vörös színtartományban vannak, ezért a kép R színcsatornáját használhatjuk a további feldolgozáshoz. Az R csatornás képen (2. kép) a sejtmagok jobban elkülönülnek a sejtplazmától, valamint ezáltal a három csatornás (RGB) képbõl már csak eggyel kell tovább dolgozni, ami gyorsítja a feldolgozást.
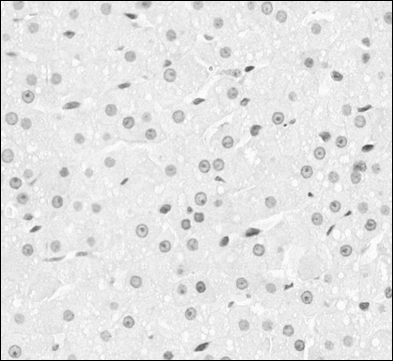
. kép: az eredeti kép R színcsatornája
A háttér kiszûrésére számos technika és algoritmus létezik, de természetesen itt sem találunk olyan algoritmust, amely minden problémára ugyanolyan jól mûködne, tehát mindig az adott specifikáció határozza meg, hogy a problémánál mi a legmegfelelõbb és leghatékonyabb megoldás. Ez az elõszûréstõl is függ, ami tulajdonképpen elõkészíti és segíti a hatékony háttérszûrést. A legegyszerûbb megoldás a küszöbölés, ami sok esetben hatékony és gyors. Egyetlen problémája, hogy alapfeltételként kell teljesülni, hogy az objektumnak és a háttérnek eltérõ intenzitásúnak (nagy kontraszt) kell lennie, valamint homogénnek (pl. sötét objektum világos háttéren).
A küszöbölés lényegében egy feltételvizsgálat, mely a képen található összes pixelt egyenként vizsgálja és eldönti az adott pixelrõl, hogy az objektum vagy háttér. A feltételvizsgálathoz meg kell adni egy küszöbértéket, ami alapján a feltételvizsgálat kiértékelõdik.
A küszöbölés az alábbi képlettel írható le:
ha f(x,y)<=K à t(x,y)=1 (objektum)
ha f(x,y)>K à t(x,y)=0 (háttér)
ahol az f(x,y) az inputkép, t(x,y) az eredménykép és K a küszöbérték.
A küszöbérték meghatározása lehet a képtõl független, rögzített érték, vagy kontrolált, azaz a kép tulajdonságai alapján meghatározott érték. A rögzített érték viszont csak olyan esetekre alkalmazható, ahol az input képek tulajdonságai csak minimális mértékben különböznek. Az adaptív eljárások viszont az input képhez automatikusan választják ki az optimális küszöbértéket:
- Globális hisztogramból klaszterezéssel számított érték
- Lokálisan változó érték
Egy kép különbözõ árnyalatú képpontokból, pixelekbõl áll. Világosságértékei a feketétõl a fehérig terjednek (szürkeárnyalatos kép esetében). A hisztogram vízszintes tengelye a világossági értékeket mutatja a nullától a maximumig, melyek között 256 osztás van. A képen látható (1. ábra) grafikon megadja minden egyes színárnyalathoz a képen, az adott árnyalatú pixelek számát.
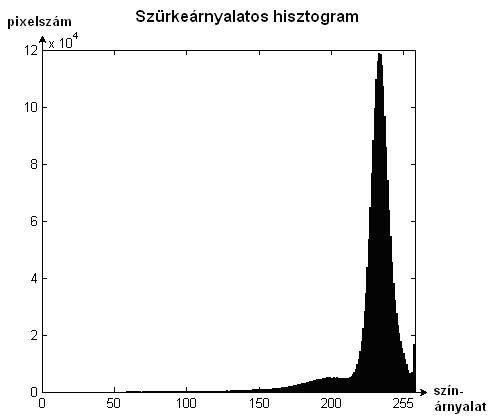
. ábra: Az eredeti kép R színcsatornája alapján készített hisztogram
A globális threshold számítási módszerek alapja a bemeneti kép alapján készített hisztogram. Az elemzés ez alapján történik.
Lényege, hogy megkeressük azt a T küszöbszámot, amely maximalizálja az objektum-háttér közötti varianciát, vagyis a szórás négyzetet. A homogén régiónak ugyanis kicsi a varianciája. Elsõ lépésként a normalizált hisztogramnál minden szürkeárnyalathoz (i-hez) meg kell határozni az elõfordulás gyakoriságát. A továbbiakban a hisztogram minden egyes pontjában ki kell számolni azoknak a pixelcsoportok gyakoriságát, középértékét és varianciáját, amelyek az adott pont elõtt illetve mögött vannak. A T küszöbszámot úgy kell beállítani, hogy a két osztály közötti variancia a legnagyobb legyen és az osztályon belüli variancia pedig a legkisebb. A számolás idõigényes a bonyolult számítási folyamatok miatt.
Az algoritmus lényege, hogy a kép alapján kapott
hisztogramot két részre osztjuk, ez lesz a kezdõ küszöbérték T0 (célszerûen
a hisztogram felezõpontján). Ezután kiszámítjuk az egyik, illetve másik oldal
intenzitásának középértékét (KJi, KBi). Ezt követõen a
küszöbérték az alábbi képlet alapján módosul:![]() . Ez a ciklus addig tart, míg Ti+1 nem lesz
egyenlõ Ti-vel, vagyis a küszöbérték már nem módosul.
. Ez a ciklus addig tart, míg Ti+1 nem lesz
egyenlõ Ti-vel, vagyis a küszöbérték már nem módosul.
Lényege, hogy a háttér és az objektum közötti variancia a legnagyobb, és a két osztályon belüli pedig a legkisebb legyen.
A módszer az Otsu algoritmus pontosságát és az ISODATA algoritmus hatékonyságát ötvözi. Elsõ lépésként szintén meg kell határozni egy vagy több kiinduló küszöbértéket, attól függõen, hogy mennyi osztályra kívánjuk felosztani a képet. Hasonlít az Isodata módszerhez, abban tér el, hogy nem a variancia értékét adja eredményül, hanem egy küszöb értéket. Tehát itt sem kell a képletet kiszámolni a hisztogram összes értékére, hanem össze lehet hasonlítani a kapott küszöbértéket a kiinduló küszöbértékkel. Ezért ez a módszer is csak addig fut, amíg eltérés van a két osztály között.
A lokálisan változó küszöbölés akkor alkalmazzák, ha az objektum vagy a háttér nem homogén, illetve ha a különbözõ megvilágítás miatt az objektum és a háttér szétválasztásához egy küszöbérték nem elegendõ. Ilyen a Niblack algoritmus, mely változó küszöbértékeket használ, azaz követi az intenzitásváltozásokat.
A legfontosabb szempont esetünkben az volt, hogy a szûrés ne legyen veszteséges, azaz a sejtmagok ne vesszenek el, illetve a sejtmagokból ne vesszenek el darabok - legfõképpen a méretük ne változzon. Viszont az is szempont volt, hogy minél több olyan területet zárjunk ki a további feldolgozásból, amire nincs szükségünk.
A megfelelõ algoritmus megválasztásához sorra kipróbáltuk az irodalomkutatás alapján talált technikákat. Az elõ-feldolgozást követõen tulajdonképpen egy szürkeárnyalatos képet kaptunk, amire az imént leírt algoritmusok mindegyike alkalmazható.
Elsõként a rögzített küszöbérték meghatározását próbáltuk ki egy segédprogram segítségével. Ez egy egyszerû és gyors eljárás, melyben manuálisan tudjuk állítani a küszöbértéket. A küszöbölést mindegyik képre elvégeztük és elmentettük az adott képre vonatkozó értéket. Mivel az értékek nagyon eltérõek voltak (nagy volt a szórásuk), ezért ezt az eljárást elvetettük.
A globális threshold számítástól vártuk a megfelelõ eredményt, mivel ezek az algoritmusok automatikusan választják ki az adott kép tulajdonságai alapján az optimális küszöbértéket.
Mindhárom
eljárás közel azonos eredményt adott, amint az az alábbi táblázatból
(1. táblázat) is kiolvashatunk.
|
Kép neve |
Otsu's method |
Var. diff. between classes |
Isodata |
|
kezelt01.jpg |
|
|
|
|
kezelt02.jpg |
|
|
|
|
kezelt03.jpg |
|
|
|
|
kezelt04.jpg |
|
|
|
|
kezelt05.jpg |
|
|
|
|
kezelt06.jpg |
|
|
|
|
kezelt07.jpg |
|
|
|
|
kezelt08.jpg |
|
|
|
|
normál01.jpg |
|
|
|
|
normál02.jpg |
|
|
|
|
normál03.jpg |
|
|
|
|
normál04.jpg |
|
|
|
|
normál05.jpg |
|
|
|
|
normál06.jpg |
|
|
|
|
normál07.jpg |
|
|
|
|
normál08.jpg |
|
|
|
1. táblázat: a globális threshold algoritmusok alapján kapott küszöbértékek
Mivel az Otsu metódus 3 képre nem mûködött - hiba generálódott -, ezért ezt az algoritmust elvetettük. A lokálisan változó küszöbölést azért nem próbáltuk ki, mert semmi nem indokolta alkalmazását.
A legalkalmasabb módszernek az Isodata algoritmust találtuk, mivel amellett, hogy megfelelt a kritériumoknak, a küszöbérték meghatározása is kevesebb idõt vett igénybe, mint a többi algoritmus esetében.
Az eredményképen (3. kép) látható, hogy a sejtmagok tökéletesen elkülönültek a háttértõl. Viszont nem minden sejtmag lett teljesen lefedve, vannak olyanok, amelyeknek a belseje lyukas maradt. Ez csak akkor jelentene problémát, ha sejtmag szélének egy része is lefedetlenné válna a küszöbölést követõen. De mivel a sejtmagot körbe vevõ burok színintenzitása magasabb, ezért szinte kizárható, hogy ez bekövetkezzen. A magok belsejét viszont ki kell tölteni a terület meghatározása, illetve a további feldolgozás miatt.

. kép: Isodata algoritmus eredményképe
Az algoritmus lényege, hogy a kiválasztott színnel - feketével - képes kitölteni a megadott színû pixelek összefüggõ csoportját. Így ez az algoritmus addig fut, amíg talál olyan szomszédos pixelt, amit még át kell színezni. Az eljárást esetünkben arra használtuk, hogy a sejtmagok közötti hátteret kitöltsük. Ezt követõen egy olyan képet kapunk, amelyben a fehér pixelek a kitöltendõ lyukakat mutatják. Az eredeti kép (3. kép) és a floodfill eredménykép NAND kapcsolatából kapjuk a 4. képet.
. kép: Az objektumok belsejének kitöltése után kapott kép
NAND kapcsolat jelen esetben három feltételbõl áll:
|
Eredeti kép |
Floodfill kép |
Eredménykép |
|
Fekete |
Fekete |
Fekete (objektum) |
|
Fehér |
Fehér |
Fekete (lyuk) |
|
Fehér |
Fekete |
Fehér (háttér) |
A statisztikai elemzésünk egyik meghatározó tényezõje a sejtmagok mérete, és a formája. Cél, hogy minden egyes sejtmag morfometriai adatát meghatározzuk, hogy az elemzéshez megfelelõ adat álljon rendelkezésünkre. Ezért elsõ körben minden egyes objektum adatait eltároltuk (befoglaló keret méretét és pozícióját, kerületi és területi pontjait).
A gyorsítás érdekében egy olyan eljárást alkalmaztunk, ami minden egyes objektumhoz különbözõ értéket - színt rendelt (5. kép).

. kép: Minden objektumhoz más-más színt rendelve
Egyszerûbb és gyorsabb lesz az eljárás, mivel a területi illetve kerületi pontok tárolását és a befoglaló téglalapok adatait is dinamikusan tudtuk meghatározni. Ez utóbbi a vizuális megjelenítés céljából, valamint a képen látható kisebb-nagyobb pixelcsoportok szûrésénél lesz fontos.
A további feldolgozás abból áll, hogy a sejtmag tulajdonságainak nem megfelelõ objektumokat kizárjuk. Nulladik szûrésként azokat a befoglaló kereteket zártuk ki, melyek kisebbek egy 10*10-es négyzetnél. Ezáltal azokat a pixelcsoportokat vetjük el, amelyek lassítanák a további feldolgozást.
Az elsõ szûrés a befoglaló keret oldalaránya alapján történik. Mivel a sejtmagok jellemzõen kör alakúak. Ha a befoglaló keret magasságát illetve szélességét elosztjuk egymással, akkor egy kör esetében 1-et kell kapnunk. Ha ez az érték nagymértékben eltér ettõl, akkor az az objektum nagy valószínûséggel nem egy sejtmagot takar. Az elsõ szûrés lényegében egy két küszöbértékes Isodata algoritmus alkalmazása.
|
|
|
|
|
|
. kép: A szûrés alapján az egyes kategóriákba sorolt objektumokra egy-egy példa
A szûrést követõen három csoport alakul ki. Az elsõ csoportba kerülnek azok az objektumok, amelyek a két küszöbérték közé esnek (6. kép középen). A másodikba azok, amelyek az elsõ küszöb alattiak, de méretük miatt azt feltételezzük, hogy két vagy több összeragadt sejtet takarnak (6. kép jobbra). A harmadik csoportba tartoznak azok, amelyeket kizártunk, és ezekkel a késõbbiekben már nem foglalkozunk (6. kép balra).
Második szûrésként alkalmazzuk. Feladat az, hogy minden kerek sejtmagot megtaláljon. A statisztikai kiértékelés alapját ugyanis az képezi, hogy hány darab egészséges (kerek) és mekkora méretû sejtmag található a szövetmintában. Természetesen az, hogy "kerek" az egy relatív dolog, ezért úgy gondoltuk, hogy bevezetünk egy mérõszámot, amivel ezt le tudjuk írni. Az eljárás a kör tulajdonságát veszi alapul. Ha a kör középpontjától minden egyes kerületi pontjáig mért távolságot rendre felmérjük egy számegyenesre (7. kép), akkor egy konstans egyenest kapunk (A).
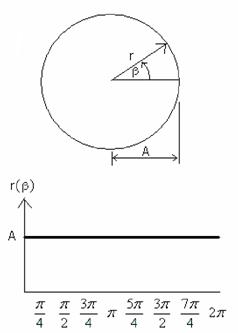
. kép: Alaksajátosság
Minél kevésbé tér el az adott objektum a körtõl, annál jobban közelíti a konstans egyenest. Tehát még azt is meg kell határozni, hogy mennyire közelíti a kapott eredmény az egyenest.
Mi ezt úgy oldottuk meg, hogy meghatároztuk az adott objektum súlypontját, ezt a pontot "neveztük ki" a kör középpontjának.
Ezután végighaladva az objektum kerületi pontjain felvettük egy számegyenesre a súlypont és a kerületi pontok távolságát (8. kép). A kapott távolságértékeknek vettük a maximum és minimum értékének különbségét (M). Mivel ez a távolság kis objektumok esetében értelemszerûen kisebb, mint egy nagy objektumnál, ezért az objektummérettõl tettük függõvé a kerekség mértékét:
kerekség = (M / objektumterület) * 10000
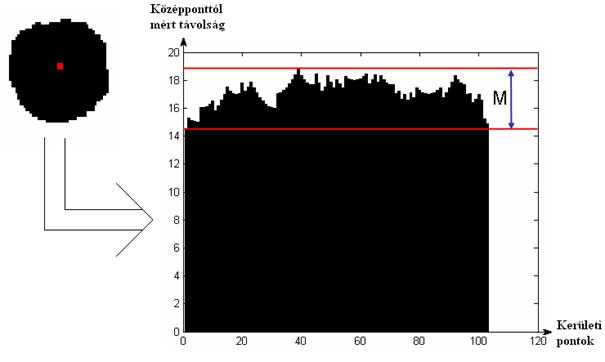
. kép: Egy objektum alaksajátosság alapján való elemzése
Ez az érték minél kisebb, annál jobban közelíti az adott objektum a kört, ha értéke 0, akkor egy szabályos körrõl van szó. A szûrés lényege, hogy egy a megadott küszöbértéknél nagyobb értékû objektumokat elvetjük. Ezt a threshold értéket 85-re állítottuk alaphelyzetben (de ezt manuálisan is lehet szabályozni).
Az összeragadt sejtmagokat úgy gondoltuk, hogy érdemes valamilyen eljárással szétválasztani egymástól. Ha ezt nem tesszük meg, akkor olyan sejtmagokat zárunk ki a vizsgálatból, amelyek külön-külön megfelelnének a feltételeknek. Ez, ha nem is nagymértékben, de befolyásolná a kapott eredményt.
Ez nem bizonyult egyszerû feladatnak, mivel a sejtmagok számtalan módon kapcsolódhatnak egymáshoz, akár láncban is (9. kép).
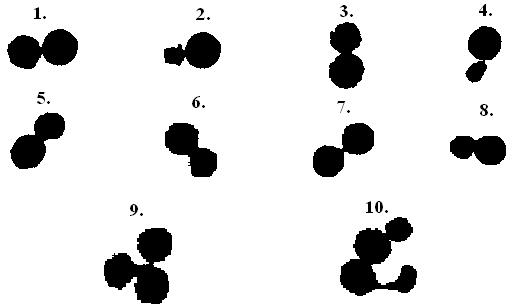
. kép: Egy-egy példa a különbözõ objektum összeragadásokból
Megpróbáltuk leegyszerûsíteni a problémát azzal, hogy elõször azokat az eseteket vettük, ahol csak két objektum van összeragadva. Ez az eset abból a szempontból egyszerûbb, hogy csak azt kell meghatároznunk, hogy hol a legvékonyabb a kapcsolódási felület a két alakzat között. Ez speciális esetekben nagyon könnyen meghatározható, például, ha a két alakzat vízszintesen helyezkedik el (9. kép/1.) vagy ha függõleges helyzetben vannak (9. kép/3.). Ezekben az esetekben elég összeszámolni az egyes sorokban illetve oszlopokban az objektum pixelek számát, és ott, ahol ez az érték a legkisebb, ott lesz a legvékonyabb a kapcsolódási felület.

. kép
Az elõzõ megfogalmazás nem teljesen precíz, mert nem a minimum érték lesz minden esetben a jó megoldás, mint ahogy az a 10. képen is látható. Azt a lokális minimumot keresünk, amely a két alakzat kapcsolódásánál található.
A
problémát az jelenti, hogy a legtöbb esetben nem ilyen speciális az eset, hanem
az objektumok átlósan (9. kép/7.) illetve különbözõ szögekben érintkeznek
(9. kép/5.). Ekkor ez az eljárás ebben a formában nem is alkalmazható.
Viszont ha tudnánk az alakzatok elfordulási szögét, akkor vissza lehetne vezetni a problémát az elõzõ esetre. Ehhez meg kell határozni mindkét objektum súlypontját, amihez egy távolság-transzformációt (distance transformation használtunk. Ez a transzformáció az objektum kerületi pontjait minimum értékre módosítja, és az objektum belseje felé haladva rétegenként egyre nagyobb pixelértékeket rendel a szintekhez.
Az így kapott eredményképen attól függõen, hogy milyen az alakzat formája egy vagy több lokális maximum alakul ki az objektumon belül (11. kép).

. kép: Borgefors távolság-transzformáció (súlypontok meghatározása)
A transzformációt többféleképpen is elõ lehet állítani. Irodalomkutatásunk alapján a leggyorsabb eljárásnak a Borgefors algoritmus bizonyult, ezért ezt az eljárást építettük bele programunkba.
A Borgefors algoritmus lényege, hogy egy bináris képen egy távolságtérképet kapjunk az egyszerûbb modellezés kedvéért. Esetünkben nem ezt a tulajdonságát használjuk ki, hanem a lokális maximum helyek gyors meghatározását. Lokális maximum helynek azokat a pontokat nevezzük, melyek közvetlen környezetében kisebb értékû pontok helyezkednek el (8-as szomszédság) mint az adott pont.
Az algoritmus három lépésbõl áll. Az elsõ egy inicializálás, melyben az objektum pontjait nem 1-esek jelzik, hanem végtelen nagy érték. Második lépésben a kép bal felsõ sarkából indítunk egy 3x3-as maszkot, melynek értékei a következõk:
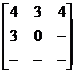
Ezeket az értékeket hozzáadva az inicializálás után kapott értékekkel, kapunk egy 9 elemû tömböt. Ebbõl a tömbbõl kell kiválasztani a legkisebb értékû elemet, és ezt kell visszaírni a középsõ helyre. Miután végigvittük ezt a maszkot a képen, harmadik lépésként egy hasonló maszkot indítunk, de most a kép jobb alsó sarkából. Ennek a maszknak az értékei a következõk:
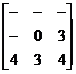
Ezután meghatároztuk a lokális maximumo(ka)t és egy feltételvizsgálattal csoportosítottuk az egyes alakzatokat a talált maximumok számától függõen. A további feldolgozásból kihagytuk azokat az objektumokat, amelyek 3 vagy annál több lokális maximmal rendelkeznek, mert nem tudtunk gyors eljárást írni a feladatra. Az egy súlypontú objektumokat alaksajátossági szûrésnek vetettük alá (biztonsági okból), mivel elképzelhetõ, hogy még ezek között is található megfelelõ sejtmag. A két lokális maximummal rendelkezõ alakzatokat, az alábbi eljárással választottuk szét. A két súlypont által meghatározott egyenesnek vettük a szakaszfelezõ merõlegesét (m). A két súlypont között felvettük az összes m-mel párhuzamos egyenest, majd eltároltuk az egyenesek által lefedett objektumpixelek számát. Ott vágtuk el az egyenessel az objektumot, ahol ez az érték minimális volt (12. kép).
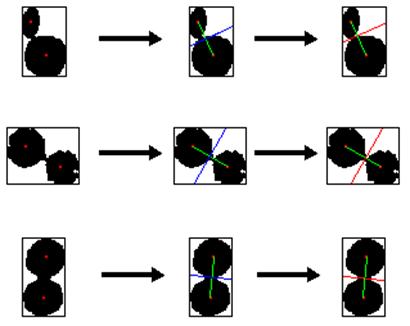
. kép: Összeragadt objektumok szétvágása
A szétvágást követõen a darabokat már külön kezeltük, és mindkettõt alaksajátosság szempontjából szûrtük.
Végül a második szûrõn átment objektumokat denzitás alapján is szûrtük. Erre azért volt szükség, mert nem kizárt hogy olyan kerek objektumok is maradtak, amelyek az eddigi szûrések ellenére sem sejtmagok. Viszont a sejtmagok illetve az egyes szennyezõdések denzitása élesen eltér egymástól. Az egyes objektumok denzitását úgy számoltuk ki, hogy pixelértékeit (RGB) összeadtuk és normalizáltuk. Az átlagtól való eltérés alapján történik a szûrés, amit százalékosan megadhat a felhasználó, alapértelmezésként 10 %.
Az objektumokon elvégzett szûrési folyamatok elvi megvalósítását az alábbi folyamatábra szemlélteti:
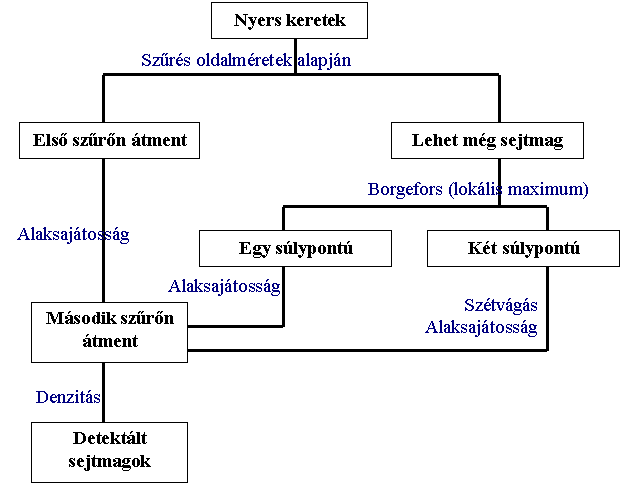
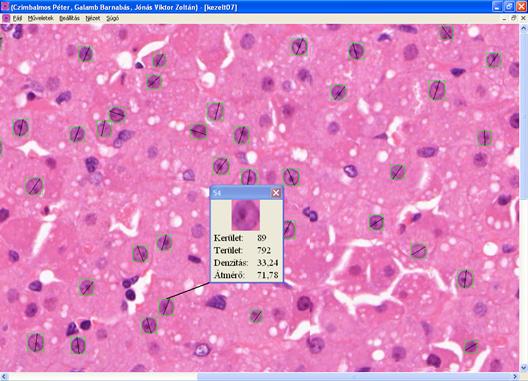
A szûrést követõen a sejtmagok adatait egy a beállított paramétereket tartalmazó (köralak mértéke, denzitás) fájlba mentjük, melyben az összesített adatok is szerepelnek (a képen található sejtmagok száma, sejtmagok kerületének, területének és átmérõjének átlaga és szórása). Ezen kívül a felhasználót egy elõugró ablak tájékoztatja az összesített adatokról, és elõáll egy eredménykép, melyen ellenõrizni lehet a detektálás helyességét, a detektált sejtmagok zöld befoglaló kerettel jelennek meg.
. kép: Eredménykép
Az egyes detektált sejtmagokra kattintva a felhasználó az adott sejtmagra vonatkozó információkat is le tudja kérdezni.
A statisztikai elemzés tulajdonképpen a normál és a kezelt állatokból vett szövetminták közötti különbséget vizsgálja. Vagyis, hogy a kezelés hatására a sejtmagok tulajdonságai szignifikánsan változtak e vagy sem. Az elemzéshez, a felhasználó által bekért (csoportok szerint) a szövetminták alapján készült adatfájlokat használjuk, melyek minden egyes sejtmagra vonatkozó adatot tartalmaznak. A kiértékelést t-próbával végezzük p=0,05 szignifikancia szinten.
A program gyorsan és hatékonya képes detektálni a sejtmagokat (egy kép elemzése átlagosan 0,5s), ez rengeteg idõt és energiát spórol meg a szövettan elváltozásokat vizsgáló patológusoknak, illetve toxikopatológusoknak. A statisztikai elemzés pedig fényt derít arra, hogy történtek-e szignifikáns változások a sejtmagok méretében illetve formájában. Ezáltal a program teljesítette az élõkövetelményekben leírtakat.
Fontosnak tartjuk viszont a program továbbfejlesztését, illetve kibõvítését. Amint azt a 7.2 fejezetben leírtuk, azokat a sejtösszeragadásokat, ahol kettõnél több sejtmag vagy objektum volt összeragadva, kizártuk a további elemzésbõl, mert nem tudtunk rá megfelelõen hatékony eljárást írni. Irodalomkutatásunk során viszont találtunk megfelelõ algoritmust (Watershead) a probléma megoldására, szeretnénk ezt a késõbbiekben beépíteni a programba.
A statisztikai kiértékelésre használt t-próba nem veszi figyelembe azt, hogy az adott sejtmag melyik állat szövetmintájából lett véve (a csoporton belül), ezáltal összemosódnak az egyedre vonatkozó - egyes esetekben - jellegzetes tulajdonságok. További fejlesztésként olyan lineáris modell integrálását tervezzük, amiben a fix faktorok (pl. kezelés, stádium) mellett random faktorokat is kezelni tudunk (pl. egyed, metszet), erre lineáris kevert modellek (Generalized Linear Models) alkalmazása tûnik kézenfekvõnek
A
sejtmagok morfometriai vizsgálata mellett egy másik megközelítésnek is
jelentõsége lehet a szövettani metszetek kvantitatív feldolgozása során.
Lehetséges, ugyanis, hogy a kezelést követõen a sejtmagok morfometriája nem
változik meg nagymértékben, viszont a vegyszerek hatására az aktív sejtmagok
térbeli struktúrája nagymértékben átalakul. Ez a megközelítés nem az egyes
sejtmagokat jellemzõ paramétereken alapszik, hanem a sejtek, szöveti elemek
térbeli (spatial) mintázatának összehasonlítható számszerûsítésével írja le a
vizsgálat tárgyát. A szöveti elemek
(pl. sejtmagok) térbeli elhelyezkedése mutathat szabályos, véletlenszerû vagy
aggregált mintázatot, ezek kvantifikálására a térbeli epidemiológiában is
használatos módszereket ajánlják egyes szerzõk.
[1] - Sejt, Wikipédia, szabadlexikon
URL: https://hu.wikipedia.org/wiki/Sejt
[2] - Eötvös Loránd Tudományegyetem (ELTE) Természettudományi Kar (TTK) Biológiai Intézet - mikrotechnikai alapismeretek: a biológiai anyag elõkészítése fény -és elektronmikroszkópos morfológiai vizsgálatokhoz.
URL: https://cerberus.elte.hu/Modszerek/Modszerek_jegyzet.rtf
[3] - OTSU, N. 1979: A thresholding selection method for grey-level
histograms. IEEE Trans Systems, Man and Cybernetics SMC-9(1): 62-66.
[4] - Ball, G. and D. Hall, 1965, "ISODATA: a novel method of data analysis and classification", Technical Report AD-699616, SRI, Stanford, CA.
[5] - Varriancia differencia between classes
URL: https://www.stat.psu.edu/~jiali/pub/it00.pdf
https://esds.mcc.ac.uk/VisualInterface/CommonGIS/doc/english/Maps.htm
[6] - Niblack, Wayne, 1986. "An Introduction to Digital Image Processing", Prentice-Hall, Englewood Cliffs, NJ.
[7] - Gonzales, Woods: "Digital Image Processing", Prentice Hall, 2002
[8] - G. Borgefors, "An improved version of the chamfer matching algorithm," in7th Int. Conf. Pattern Recognition, Montreal, P.Q., Canada, 1984, pp. 1175-1177.
[9] - Watershead Transform
URL: fcl.uncc.edu/mcshin/dip/lecture/13.watershed-transform.ppt
[10] - Modern Applied Statistics with S. Fourth Edition. by W. N. Venables and B. D. Ripley. Springer. ISBN 0-387-95457-0, 2002. (272-279, 292)
[11] - Mattfeldt, T., Clarke, A. & Archenhold, G. (1994) Estimation of the directional
distribution of spatial fibre processes using stereology and confocal
scanning laser microscopy. J. Microsc. 173, 87-101.
[12] - Rudolf Karch, Friederike Neumann, Robert Ullrich etc. (2005 March) The spatial pattern of coronary capillaries in patients with dilated, ischemic, or inf lammatory cardiomyopathy
Találat: 5410