 | |||||||||
|  | ||||||||
| |||||||||
| | ||||||||
| kategória | ||||||||||
|
|
||||||||||
|
|
||
Az adatbázisok fejlõdési trendjei
A kezdetek
Az elsõ DBMS termékek a '60-as évek végén jelentek meg. Ezek a file-kezelõkbõl alakultak ki, azok szerves folytatásaként.
Az elsõ rendszerek sajátosságai:
sok kis adatelemmel dolgoztak
nagy számú, de egyedenként kevés adatot érintõ mûvelettel dolgoztak.
Pl.: repülõjárat-helyfoglalás,
banki rendszerek, számlázás,
vállalati nyilvántartások.
Az elsõ adatmodellek
Hierarchikus modell: kiszorulóban van, ami részint fogalmi gyengeségének következménye.
Hálós modell: szorosan kötõdik a COBOL nyelvhez. A modell kezelésére a CODASYL szabvány tartalmaz ajánlásokat. A hálós modell elõfordul magyar banki rendszerekben is.
2. A közelmúlt és jelen
Relációs adatmodell: E. F. Codd 1970-es dolgozata - melyben a relációs adatmodellezés alapjait dolgozta ki - forradalmi elveket fektetett le a DBMS-ekkel kapcsolatban. (Az IBM árult elõször relációs rendszereket.)
A modellben
az adatokat relációk (síkbeli táblák) formájában képzeljük el;
a lekérdezés magas szintû nyelven zajlik (Ma fõleg az SQL-en).
Pl TERMELÕ tábla
|
NÉV |
CÍM |
TERMÉK |
MENNYISÉG |
|
Napsugár Kft. |
Fõ u. 33. |
cibere |
|
|
Napsugár Kft. |
Fõ u. 33. |
padlizsán |
|
|
|
Ó u. 12.
bivalytej
Az összetartozó adatnégyeseket táblázatban tároljuk. A sorok rekordoknak, az oszlopok névvel és típussal rendelkezõ attribútumoknak felelnek meg.
Egy SQL kérdést a következõképpen lehet megfogalmazni:
SELECT termék Mi jelenjen meg a végeredményben (melyik oszlop)?
FROM termelõ Honnan vegyük az adatokat (melyik táblából)?
WHERE mennyiség > 100 Mi a feltétel (melyik sorok kellenek)?
A szelektor kérdés eredménye a "bivalytej" lesz, vagyis az SQL jelen esetben olyan sorhalmazt (strukturált adathalmazt) ad vissza, amely egy elembõl áll (feltéve, hogy a tábla elsõ 3 sorát nézzük csak).
Egyre kisebb rendszerek: ez az irányzat a PC-knek, a munkaállomásoknak és a relációs megközelítésnek az ötvözete. A rendszerek ugyan "kicsik", de egyre nagyobb mennyiségû adatot kezelnek. Fontos tényezõ bennük a relációs adatbázis "felszíni", kezelõi egyszerûsége.
Egyre nagyobb rendszerek: ezek a tipikusan terra byte-os (1012 byte) alkalmazások, melyek nagy szervezetek adatait kezelik. Bonyolultabb adatformákat használnak (például digitalizált filmek tárolhatók egy-egy rekordban).
A DBMS-ek fizikai eszközei:
elsõdleges tárolás: belsõ memória;
másodlagos tárolás: lemez (-köteg), elérési ideje 10-20 msec;
harmadlagos tárolás: távoli tárak, CD, elérési idejük pár sec.
Megemlítendõ még az adatbázis-kezelésben a párhuzamos feldolgozás is, mely
cél-architektúrákon, -gépeken, ill.
elosztott rendszereken, bonyolult algoritmusok segítségével valósul meg.
3. Adatbázisok közeljövõje
Típusok, osztályok, objektumok megjelenése DB környezetben
Kialakulásának oka az objektumos módszerek és nyelvek térhódítása a programozásban. (Pl. SmallTalk, C++, Java.)
Objektumorientált (OO) terminológia, fontosabb alapfogalmak:
gazdag típusrendszer
elemi típusok: (egészek, lebegõpontos számok, mutatók, stringek, stb.)
rekordstruktúrák
kollekció-típusok
T lista, a tömb, egyszerû típusú elemek kollekciója, vagy
T halmaz (pl.: =) - az elemek sorrendje közömbös,
T multihalmaz (pl.: =) - megengedett az elemek ismétlõdése is.
osztályok, objektumok
Egy osztályt így írhatunk le:

Az objektumok az osztályok konkrét elõfordulásai, melyeket az OID - az objektum-azonosító - különböztet meg egymástól, így rendkívül fontos tényezõ. Az OID egy hagyományos rendszerben egy mutató a memóriabeli elõfordulásra, de a mai DBMS-ekben lehet összetettebb szerkezetû is, hiszen meg kell mutatnia, hogy az objektum mely elosztott site-on helyezkedik el, azon belül hol található, stb.
Az adatbázis szemlélettel - mely szerint az egyforma rekordok egyszer tárolódnak - szemben az objektumos szemlélet legfontosabb különbsége az, hogy létezhetnek egyforma objektum-példányok.
metódusok: az egyes osztályok objektumain ható függvények.
Pl.: egy személy életkorát a mai napon megadó metódus:
C osztály := Személy
mai_Életkor (a: Személy);
Az osztály objektumait csak metódusokon keresztül érhetjük el, ezzel rendeztük a hozzáférések rendszerét. Ez a mód a "tokba foglalás" (encapsulation); a fenti példában azt jelenti, hogy a C osztály objektumait csak a C metódusain keresztül használ(hat)juk.
osztályhierarchiák, öröklõdés: egy C osztály lehet a D osztály alosztálya, "specializációja", vagyis C örökli D tulajdonságait és metódusait.
D = Személy
A fenti példában látott öröklõdés csak akkor hasznos, ha adatbázisunkban nem minden személy ügyfél (mert ekkor nem kéne a kettõt megkülönböztetni és elég lenne csak az Ügyfél osztályt megtartani).
Megszorítások és triggerek
Ezek egy DBMS aktív elemei, melyek mindig elérhetõek és ha kell, végre is hajtódnak. A modern DBMS-ekben igen sok aktív elem található.
a.) megszorítás (kényszer, constraint): olyan, a DB-re vonatkozó állítás, amelynek igazságát a rendszer megköveteli, kikényszeríti. Ilyen megszorítások a rendszerben deklarálhatók.
Pl.1.: a Személynél a személyi szám a kulcs, amivel az emberek megkülönböztethetõk egymástól. Megszorítás: két személynek nem lehet azonos személyi száma. Az azonos személyi szám ellenõrzése minden új rekord felvételénél megtörténik, és egyezés esetén a rendszer hibajelzéssel válaszol, a rekord ekkor nem felvehetõ (fel kell kínálni a javítás lehetõségét).
Pl.2.: megszorítás az is, ha a banki egyenleg nem mehet 0 alá.
Ezek a megszorítások a DB konzisztenciájában fontos szerepet játszanak.
b.) trigger: kódrészlet, amely bizonyos feltétel(ek) bekövetkezésekor automatikusan végrehajtódik. Triggerekkel az alkalmazásokhoz kapcsolódó teendõk könnyen elvégezhetõk. (A triggerek hasonlítanak az operációs rendszerek - pl. a UNIX - démonjaihoz.)
Pl járat törlésekor automatikusan figyelmeztetni kell az operátort;
havi zárás adatgyûjtését trigger váltja ki a nap végén vagy a hónap utolsó napján.
Multimédia-adatok kezelése
A multimédia tárgykörébe sokféle adatforma - pl. video, audio, radarkép, szöveg - esik. Jellemzõen
sokkal nagyobb és összetettebb adatokat,
nehezebb elemi mûveleteket kell kezelni (pl. két egész szám összehasonlítása egyszerû, de két (bit)képé már jóval nehezebb),
esetenként pedig óriási rekordokat kell feldolgozni.
Mindez szemléletváltáshoz vezet, így például egy teljes könyv is tekinthetõ egyedi rekordnak.
Adathalmazok egységesítése
A törekvés alapja az, hogy szeretnénk sokféle, sok helyen lévõ adatot egységesen látni, ami nagyon nagy munkát jelent. Tipikusan ez az elv vezeti a WorldWideWeb-et, melynek böngészõi egységes látásmód kialakítására törekszenek.
Másik jó példa egy nemzetközi nagyvállalat, melynek különbözõ részlegei vannak (pl. az amerikai Sears cég). Gondot okozhat az, hogy az egyes részlegek eltérõen kezelnek adatokat - így például már mértékegységeket használnak. Egyetlen közös adatbázissal többnyire nem lehet megoldani a problémát, ehelyett egy egységes felületet kell tenni a részlegek fölé: ezáltal több DB tartalmát kezelik egy nézetbõl.
Az egységesítés ötlete az adattárház (repository):
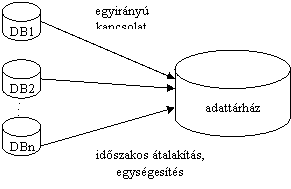
Például az éjszaka folyamán a nagyvállalat egységeinek különbözõ mértékegységekben nyilvántartott árukészletét közös egységbe számolják át. Ezt a tájékoztató adatmennyiséget az adattárház bizonyos ideig - pl. egy hétig - tárolja. Erre a rendszerre jellemzõ tehát a batch-jellegû feldolgozás.
Mivel az adattárházban óriási adathalmazt kezelnek egy felület alatt, ezért nagyon fontos a körültekintõ elemzés és tervezés - hogy az adatokat hatékonyan kezelhessék.
Ehhez a témakörhöz kapcsolható az adatbányászat (data mining), ami különbözõ statisztikai, és mesterséges intelligencia által adott eszközökkel és módszerekkel igyekszik összefüggéseket (dependencies) találni a nagy adathalmazokban. Például egy áruházi adatbázis sokat elárul a fogyasztói szokásokról.
Találat: 1685