| |||||||||
|  | ||||||||
| |||||||||
| | ||||||||
| kategória | ||||||||||
|
|
||||||||||
|
|
||
Hashelés és ritka indexes szervezési módszerek
1. Adatbázisok alapvetõ fizikai szervezési elvei
Ezek a következõk:
1. Kupac (heap) (errõl az elõzõ rételben már volt szó)
2. Hash
3. Indexelt szervezés.
2. Hash-szervezés
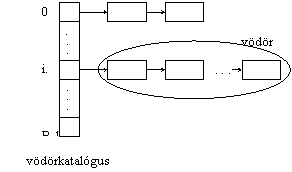
Elsõsorban a vödrös (bucket) hash-elés és változatai használatosak. Az alapmódszerben adott:
· B db vödör (egy vödör egy kis - kevés lapból álló - lap-láncot jelent);
· egy vödörkatalógus (0-tól (B-1)-ig indexelt tömb)
· és a h: -> [0,B-1] hash-függvény, mely legyen gyorsan számítható és ne okozzon túl sok ütközést (ütközés: két kulcshoz h ugyanazt a tömb-cellát rendeli)
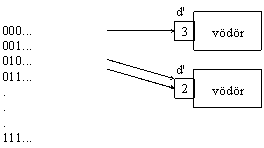
Ábrázolva
A hash-függvény a K kulcsú rekordh 929j91j oz az i. vödröt sorsolja: h(K) = i.
A keresés a sorsoláshoz egész hasonlóan zajlik: a K' rekordot keresve ki kell számítani a h(K') értékét és a megfelelõ vödörhöz kell fordulni. Ez a módszer átlagos értelemben igen jó (a vödrök nem lesznek túl kicsik / túl nagyok); átlagban konstans lapelérés elég.
Tipikusan B-t prímnek választják, és a hash-függvényt így határozzák meg:
h(K) := K (mod p).
Az alapmódszer hibája, hogy statikus: rögzítve a vödörkatalógus méretét elõfordulhat, hogy túl hosszú lap-láncok alakulnak ki a vödrökben, vagyis a szervezés nem követi dinamikusan az állomány méretváltozásait.
Javaslatok a statikusság kiküszöbölésére:
Dinamikus hash-elés
Ötlete: a szófa és a vödrös hash-elés ötvözete segít. h(k)-t fogjuk fel úgy, mint egy bitsorozatot.
A szerkezet így épül fel
 |
A vödrök itt is lap-láncok, de méretük fix (bár rendszerenként más és más lehet).
Keresés: h(K) bitjeit olvasva lehet megtalálni a kívánt vödröt és benne a megfelelõ lapot.
Kezdõállapot

Ha egy vödör megtelik, akkor szét kell vágni. Például a 01... kezdetû, 2-es számú vödör telt meg. Ebbõl csinálunk két vödröt a 010... és 011... -gyel kezdõdõ lapok számára.
 |
Van értelme a testvér-vödrök összevonásának is. Ha törlünk egy vödörbõl, akkor megnézzük a testvérét: ha együtt jobban ki vannak töltve, akkor érdemes összevonni õket.
Természetesen a dinamikus hash-elés az alapmódszernél nehézkesebb és költségesebb. Ez részint attól is függ, hogy mi kerülhet be a belsõ memóriába (esetleg az egész szerkezet vagy csak a gyökérhez közeli csúcsok, stb.). A költséget ezért nehéz pontosan megbecsülni.
Növelhetõ (extendable) szervezés
A módszer paramétere: d pozitív egész szám, ez a katalógus globális mélysége. A katalógusnak ekkor 2d számú bejegyzése lesz. h(K) továbbra is egy bitsorozatnak tekinthetõ.
A szerkezet így épül fel d=3 esetén
| |
| |
|
| |
| |
| |
| |
| |
d' a lokális mélység. Pl. d'=3=d => a katalógus elemeit címzõ háromjegyû cím mindhárom bitjére szükség van a vödörben; benne minden rekord 000-val kezdõdik. Ha d'=2, akkor az azt jelenti, hogy itt elég 2 bit a rekord eléréséhez, elhelyezéséhez.
A szervezés során mindvégig igaz, hogy d<= d'.
Tehát a globális mélység a használható, a lokális mélység pedig a használt bitek számát jelenti.
Túlcsordulás esetén a vödör lapjait két vödörben próbáljuk elhelyezni.
· d nõ (azaz új, nagyobb táblát készítünk), ha a d' lokális mélységû vödör túlcsordult;
· d csökken (azaz új, kisebb táblát készítünk), ha minden d' < d.
3. Indexelt szervezés
A módszer kihasználja a kulcsok rendezettségét és alapvetõ mûveletek megvalósítására szolgál.
Adott a tényleges, tárolni kívánt "fõ" állomány ("nagy" rekordokkal). Felette helyezkedik el az index állomány, mely (kis) index rekordokból áll. A kettõ közötti összefüggések segítik a lapok elérését.
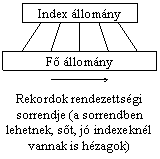
Az index rekordokból - kis méretük miatt - sok férhet el egy lapon.
Az index rekord felépítése
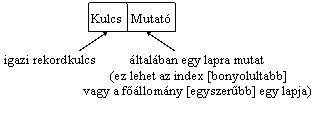
Az indexelés fajtái
a.) Egyszintes ritka indexelés (ISAM)
· az index rekordok kulcs szerint rendezve vannak az index állományban elhelyezve;
· mutatójuk a fõ állományba mutat.
Kapcsolat a mutató és a mutatott rekord között:

K az elsõ (legkisebb) kulcsérték a mutatott lapon.
Keresés: a K kulcsú rekordot keresve az index állományban megkeressük a legnagyobb K' kulcsú index rekordot, amelyre K <= K' teljesül. Ekkor biztosak lehetünk abban, hogy K' mutatóját, m-et követve megkapjuk az "esélyes lapot", ahol K rekordja talán megtalálható - feltéve, hogy egyáltalán része a szerkezetnek.
A ritka indexrekordok között - kihasználva a rendezettséget - kereshetünk (feltéve, hogy N db index lap van):
· lineáris kereséssel: az index állományt az elejétõl kezdve szekvenciálisan járjuk be. A keresés idõigénye az index lapok számával arányos, ~ N lapelérés (N<<fõállomány lapjainak száma).
· bináris kereséssel: felezéses módszerrel járjuk be az index állományt. Az idõigény ~ logN lapelérés.
· interpolációs kereséssel: (pl. a telefonkönyvben így keresünk) szükség van valamilyen tárolt tudásra, statisztikára az index állomány bejárásában. A keresés jósága ennek a tudásnak a minõségéhez mérhetõ, ~ loglogN lapelérés.
A további mûveletekben lényeges, hogy mennyire mozgathatók a fõ állomány rekordjai: szabadok avagy kötöttek.
Tegyük fel hogy a fõ állomány rekordjai szabadok, vagyis lógó mutatóktól nem kell tartani (a fõ állomány rekordjaira csak az index rekordok mutatói mutatnak).
· beszúrás: a rekordok helyét kereséssel határozzuk meg. Túlcsordulás esetén lapvágást kell végezni (ez a B-fáknál megismert módszert jelenti) és ennek megfelelõen új index rekordot létrehozni - ami esetleg az index állományban is lapvágást okozhat.
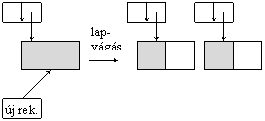
· törlés: a lapvágás inverzét, a lapösszevonást kell alkalmazni szükség esetén.
· tólig: a szervezés támogatja ezt a mûveletet, ami adott kulcs-értékek közötti rekordok kilistáztatására szolgál.
A stratégia következménye, hogy a lapok legalább félig telítve lesznek a fõállományban.
Ha a fõ állomány tömör, akkor a fenti mûveletek nehézségekbe ütköznek. Ezért találták ki a módszer statikus változatát (kötött rekordokra).
b.) Egyszintes ritka indexelés - statikus változat
Itt az index állomány elõre elkészül; az index rekord pedig nem a fõállomány egy lapjára, hanem egy "lap-oszlopára", listájára mutat.
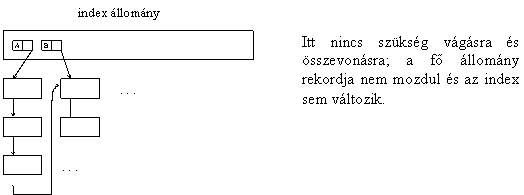
A ritka index szabad és kötött változata között a költség szempontjából drámai különbség van.
További módszerek: (a köv. tétel anyaga)
c.) Többszintes indexelés
d.) Sûrû indexelés
Találat: 2455