 | |||||||||
|  | ||||||||
| |||||||||
| | ||||||||
| kategória | ||||||||||
|
|
||||||||||
|
|
||
Diplomaterv
Viselkedés változás analízise
távközlési hívásadatokon
Tartalomjegyzék
1. Absztrakt ha kell angol is
2. Bevezetés
2. 1. A téma elhelyezése a világban; adatbányászatról pár szó
2. 2 Adatbányászati feladatok
2. 3. BME és a T-com közös projektjének leírása: mirõl szól, milyen adataink vannak
2. 4. A téma indoklása, a konkrét megoldandó feladat, a probléma megoldása mit tesz lehetõvé a számunkra, Miért indokolt a probléma kezelése
2. 5. A CRISP-DM modell rövid bemutatása, mely alapján a téma kidolgozása történik.
3. 1. Business Understanding: a kitûzött feladat miért hasznos üzleti szempontból
3. 2 Data Understanding: adatok feltérképezése (piped-mine), begyûjtése (piped-mine), megértése
3. 3. Data Preparation: a tényleges adathalmaz elkészítése
3. 4. Modeling: konkrét adatbányászati mûveletek: modellezési technika
3. 4. 1. technika kiválasztása: milyen modelleket próbáltunk, a sikeres (leghatékonyabb) modell ismertetése matematikai szempontból (elméleti háttér)
3. 4. 2. modell felépítése, futtatás
3. 4. 3. sikeresség vizsgálata, modell ellenõrzése
3. 5. Evaluation
3. 6. Deployment
4. Összefoglalás, következtetések
V. Irodalomjegyzék
VI. Rövidítések jegyzéke
VII. Ábrajegyzék
VIII. Köszönetnyilvánítás
IX. Mellékletek
Napjainkra a tároló kapacitások erõteljes növekedése valamint az árak nagymértékû csökkenése a hétköznapi életben is egyre több helyen elérhetõvé tette adatbázisok és adattárházak használatát. Ezáltal manapság szinte minden közép- és nagyvállalat alkalmazza ezeket az informatikai eszközöket vásárlóik, ügyfeleik, illetve saját adataik tárolására. Ez a folyamat azt eredményezte, hogy egyre több információ halmozódott fel, melyeket eleinte csak ellenõrzésre illetve visszakeresésre használtak, így alakultak ki az úgynevezett "adattemetõk" (data tombs) [1].
Azonban egyre több területen merült fel az igény arra, hogy a meglévõ információkból valami új, hasznos információt nyerjünk ki, melyekre a régebbi adatbázis kezelõ rendszerek még nem voltak felkészülve. Ez az igény keltette életre az adatbányászatot, az 1980-as éves végén, mely mostanra már közel húsz éves fejlõdésen ment keresztül.
Az adatbázisból való tudásfeltárás[1] során adatbányászati algoritmusokat alkalmazunk. Az algoritmusok elvégzése után mintákat fedezünk fel az adatokban, végül számítógép segítségével a mintákból használható tudást kovácsolunk. Az adatbányászat definíciója tehát a következõ: nagyméretû adatbázisokból új, nem triviális és egyben hasznos összefüggések feltárása.
Az adatbányászat egy új tudományterület, mely számos korábbi tudománnyal is szoros kapcsolatban áll, illetve ezeket ötvözi. Ilyenek például a teljesség igénye nélkül a matematika, statisztika, számítástudomány, mesterséges intelligencia és a marketing. A diplomatervem során az adatbányászat már meglévõ eredményeit, módszereit használom föl, illetve feladatom megoldásához új módszert (modellt) alakítok ki, mellyel mindegy hozzájárulva az adatbányászat eddigi töretlen diadalmenetéhez.
A sikeres alkalmazások eredményeképpen az adatbányászat egyre elfogadottabb tudománnyá vált, így ma már az adatok tárolásán kívül, szinte mindenütt fontos azok feldolgozása és elemzése is. Az adatbányászat a kereskedelem, a pénzügy, valamint a biológia és orvostudomány területén már bizonyította hatékonyságát. Mégis van néhány tipikus feladat, mely több különbözõ környezetben is felmerül és általános megoldási módszereik hasonlóak a különbözõ felhasználási területeken. Ilyenek például a következõ feladatok:
Gyakori minták kinyerése [2]: olyan elemcsoportok megkeresése, melyek gyakran együtt fordulnak elõ, azaz asszociációs szabályok megkeresése. Tipikus példája a vásárlói kosár elemzése, ahol a gyakran együtt vásárolt termékek kerülnek feltárásra.
Attribútumok közötti kapcsolat: itt az elemek attribútumai közti kapcsolatokat tárjuk fel, így alakítunk ki korrelációs, illetve függõségi szabályokat.
Osztályozás [2]: az elemeket valamilyen tulajdonságuk alapján elõre definiált csoportokba soroljuk, vagyis osztályozzuk õket.
Klaszterezés [2]: itt az elemeket egy-egy elõre nem definiált csoportokba soroljuk be. Az adott klaszterezõ algoritmus feladata az egyes csoportok kialakítása. Az a fontos, hogy a csoporton belüli elemek egymáshoz valamilyen szempontból közeliek legyenek, a különbözõ csoportokban lévõk pedig távoliak.
Sorozatelemzés: a hasonló sorozatokat vagy részsorozatokat keressük meg, illetve azokat, amelyek gyakran fordulnak elõ. Megpróbáljuk meghatározni, hogy egy adott sorozat nagy valószínûséggel mivel fog folytatódni.
Eltéréselemzés: az elõzõ feladatoknál általában nem vettük figyelembe az általános trendtõl erõsen eltérõ néhány elemet. Itt viszont pont azokat kell megkeresnünk. Tipikus példája a hibadetektálás, vagy a csalások felderítése.
Viselkedés elõrejelzés: feladat itt az, hogy a múltbéli események alapján megjósoljuk, hogy milyen fordulatok várhatók a vizsgálati alany viselkedésében. Ez használatos, ha például meg akarjuk tudni, melyik ügyfél hajlik arra, hogy szolgáltatót váltson (churn-analízis), vagy, hogy melyik ügyfél nagy valószínûséggel hogyan fog reagálni egy-egy új termék bevezetésére (affinitás elemzés). Diplomatervemben fõként ez utóbbi kérdéskört vizsgálom meg.
Az elõzõ félévek során bekapcsolódtunk a tanszék egyik adatbányászati projektjébe. A projekt a T-Com távközlési cég megbízásából indult, a MTA-SZTAKI[2], a TMIT tanszék és az AITIA Rt. részvételével. A cég vezetékes telefonhívások szolgáltatásával is foglalkozik, így nagy mennyiségû hívásadatok állnak rendelkezésükre. Az adatok tárolása itt létfontosságú, hiszen az elõfizetõk nyomon követéséhez és a számlázásához elengedhetetlen nagyméretû adattárházak használata. A tárolt adatok nagy segítséget nyújtanak akkor is, ha egy vállalat racionalizálni szeretné a mûködését, illetve mindezeken kívül az adatokból másfajta összefüggésekre is rá lehet jönni az adatbányászati tudomány segítségével. A tanszék hallgatóinak feladata pedig az, hogy az adatokon különbözõ adatbányászati projekteket hajtsunk végre. Természetesen a felhasználói viselkedések helyes modellezése a többi telekommunikációs területen, például mobil távközlés, vagy internet szolgáltatók esetén is alkalmazható, sajnos azonban ilyen adatbázis nem áll rendelkezésünkre. A tanszéken elemezzük a hívások különbözõ attribútumait, úgymint a hívások idõpontját, idõtartamát, irányultságát valamint a költségét, mely a tarifacsomagokhoz szorosan kapcsolódik. Természetesen a hasznos információ megszerzéséhez az elõfizetõk megfelelõ modellezésére van szükség, mely tulajdonképpen ezen adatbányászati projektek célja.
Manapság a telekommunikációs piac telítõdött, így a cégek számára a legfontosabb, hogy a már meglévõ ügyfeleiket, megtartsák. Ezért, ha sikerül elõre jelezni, hogy ki fog szolgáltatót váltani (ez a terület a churn-analízis), célzott reklámokkal, ajánlatokkal (Direct Marketing) van esély megtartani az ügyfelet. A cégek hajlandóak az ügyfelek részére egy kedvezõbb tarifacsomagot ajánlani, ezáltal kevesebb profithoz jutni, csak azért, hogy nehogy más szolgáltatót válasszanak. Ráadásul a helyzetet még az is bonyolítja, hogy a tarifacsomag váltása után a legtöbb ügyfélnek megváltoznak a telefonálási szokásai. Sokan jóval többet kezdenek telefonálni, mások pedig jobban odafigyelnek arra, hogy mikor telefonáljanak. Természetesen vannak olyanok is, akik érzéketlenek a tarifacsomag váltásukra vagy nincsenek pontosan tudatában annak, hogy a nap melyik szakában milyen irányban mekkora költséggel telefonál. A diplomatervemben ezt a feladatkört próbálom megoldani, vagyis olyan modelleket kívánok létrehozni, melyek hûen türközik egy átlagos elõfizetõ viselkedését egy új tarifacsomag bevezetése esetén.
Az üzleti feladat részletesebb kifejtésére és az adatbányászati cél meghatározására . fejezetben kerül sor.
Az adatbányászati algoritmusok megszületését követõen problémaként merült fel, hogy a konkrét adatbányászati projektek terén nincs olyan jól kidolgozott általános módszertan, mely mentes lenne a különbözõ szaksági specifikumoktól. Mivel az adatbányászati feladatokat széleskörûen alkalmazzák, ezért a tapasztaltabb szállítók kidolgoztak egy olyan módszertant, mely rendszerezi a nélkülözhetetlen lépéseket és lehetõvé teszi, hogy egy adott területen megszerzett tudást egy másikban is felhasználják. Így jött létre a CRISP-DM (CRoss Industry Standard Process for Data Mining − Iparág független Szabványos Adatbányászati Módszertan) [3] .
A módszertan hat fõ lépését az ábrán láthatjuk ( . ábra), vizsgáljuk meg ezeket a lépéseket sorjában!
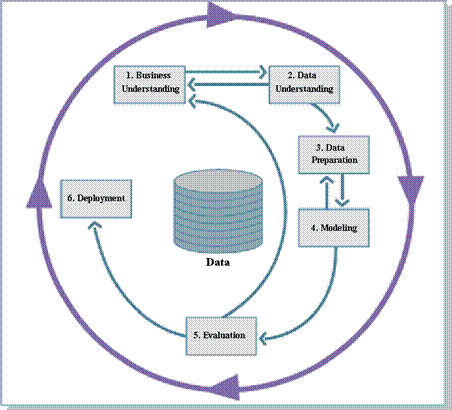
. ábra ACRISP-DM módszertan
1. Üzleti célok meghatározása (Business Understanding ez a projekt elsõ fázisa, itt fogalmazzuk meg a projekt célkitûzését, illetve a vele szemben támasztott elvárásokat üzleti szemszögbõl igyekszik meghatározni. Itt határozzuk meg az alkalmazási környezetet is.
2. Az adatok megismerése (Data Understanding Ebben a fázisban elõször begyûjtjük az elemzéshez szükséges adatokat, megértjük õket, majd megvizsgáljuk mely attribútumok fontosak számunkra az elemzés szempontjából és ezek milyen típusúak. Elemezzük az adatainkat adatminõség szempontjából is, hogy mennyire hiányosak vagy inkonzisztensek a rendelkezésre álló adatok. Ez utóbbi lépés nagyon fontos minden projekt során, mert ha nem tiszta adaton dolgozunk a konkrét adatbányászati algoritmusokkal, akkor vagy hibás eredményeket kapunk, vagy eredménytelen lesz a projekt.
3. Adatelõkészítés (Data Preparation ebben a fázisban a különbözõ forrásokból begyûjtött adatokat egységes formátumra hozzuk. Elvégezzük az adattisztítást, mely során az adat minõségének feltárása során megismert hiányosságokat pótoljuk: a hiányzó illetve hibás adatokat feltöltjük. Valamint elvégezzük az adatbeszúrás mûveletét is, mely során akár új attribútumokat, vagy rekordokat fûzhetünk a már létezõ adatstruktúrákhoz. A fázis végére elkészül az a struktúra, mely az elemzés bementéül szolgál.
4. Modellek megalkotása (Modeling): Ebben a fázisban érkezünk el az adatbányászati mûveletek végrehajtásához. Elõször a modellezési technikát választjuk ki, általában valamely erre a célra kifejlesztett szoftver (például Clementine) segítségével. A technika kiválasztása után, a modellt az aktuális adatokhoz hangoljuk, vagyis felparaméterezzük a modellünket. A modellezés elvégzése után meg kell vizsgálnunk a modell sikerességét. Nem kielégítõ eredmények esetén új modellel, vagy új paraméterekkel kell újrakezdeni a modellezési lépést. Ezeket a lépéseket egy adatbányászati projekt keretében többször is végrehajtják. Egy ilyen projektre ugyanis sokkal inkább jellemzõ az, hogy elsõre nem sikerül a helyes modellt megtalálni.
5. Eredmények értékelése (Evaluation Ebben a szakaszban már a megfogalmazott üzleti céloknak megfelelõen értékeljük ki a modell, illetve a modellezési lépések sikerességét, hogy teljesítettük-e az elsõ fázisban megalkotott üzleti célokat. Amennyiben az eredményt megfelelõnek ítéljük, akkor modellünket éles bevetésben is használhatjuk és továbblépünk a megvalósítás fázisába. Ha a modellünk nem megfelelõ, akkor vissza kell kanyarodnunk egy korábbi lépéshez, vagy egy új projekt keretén belül más irányvonalat kell keresnünk.
6. Az eredmények üzleti szintû alkalmazása (Deployment Ezen utolsó fázis célja, hogy a projekt során megszerzett ismereteket a megrendelõ számára is érthetõ formába kell hoznunk. Ehhez egy alkalmazási és egy üzleti tervet kell készíteni. Ez utóbbi azért szükséges, hogy az adatbányász csoport kivonulása után is folytatódhasson a munka. Bizonyos esetekben célszerû gondosan kidolgozott fenntartási stratégiákat is kidolgozni. A projekt végén gyakran szükség lehet egy olyan összefoglaló dokumentumra, mely a projekt során nyert tapasztalatokat összegzi. Végül saját magunk számára is hasznos egy olyan dokumentum létrehozása, melyben a projekt pozitív és negatív tapasztalatait gyûjtjük össze és levonhassuk a megfelelõ konzekvenciákat.
Mivel diplomatervem gyakorlatilag egy teljes adatbányászati projekt végrehajtását tartalmazza, ezért munkám során ezt a jól kidolgozott módszertant követem a továbbiakban.
Az 1. ábrán jól láthatjuk, hogy az egyes lépések között visszalépések is történhetnek, ez a CRISP-DM metodika egyik legfontosabb jellemzõje, mely azért van, mert nem megfelelõ eredmények esetén gyakran vissza kell lépni az elõzõ fázisba és addig változtatni az adathalmazon, új ötleteket kipróbálni, ameddig kielégítõ eredményeket nem kapunk. Diplomaterv feladatom megoldása során magam is többször alkalmaztam ezt a visszalépési eljárást, de ebbe a dokumentumba már csak a végleges, legjobb eredményt hozó módszert fejtem ki részletesen, az elõfordult esetleges visszalépéseket és eredménytelen "vakvágányokat" csak megemlítem a dolgozatomban.
A fejezet címe egy adatbányászati projekt elsõ lépése. Ebben a fázisban a projekt célkitûzéseit, illetve a vele szemben támasztott elvárásokat üzleti szemszögbõl igyekszünk meghatározni. Az "üzleti" kifejezés itt nem feltétlenül a hagyományos pénzpiaci értelmezését fedi, hanem az általános alkalmazási környezetet adja meg, ezért ebben a fejezetben térek ki a munkám során rendelkezésre álló technikai és alkalmazási eszközökre is.
A diplomatervemben olyan modelleket kívánok létrehozni, melyek hûen türközik egy átlagos elõfizetõ hívási szokásait egy új tarifacsomag bevezetése esetén.
Nehezíti a modell megalkotását, hogy az elõfizetõk egyes csoportjai biztosan másképpen reagálnak egy-egy új tarifacsomag bevezetésére. A nagyobb cégeknél dolgozók munkahelyi hívási szokásait valószínûleg nem befolyásolja, hogy a cég milyen szolgáltatót választott, és épp az adott idõpontban mekkora költséggel telefonál a dolgozó. Másrészt pedig a nagyobb cégek általában olyan kedvezményekre is jogosultak, melyek egyéni elõfizetõk számára nem elérhetõk. Ezért a további vizsgálatokban csak az egyéni elõfizetõket veszem nagyító alá. Tovább nehezíti a modellalkotást az, hogy egyéni elõfizetõkön belül is több csoport létezik, hiszen biztosan más hívási szokásai vannak egy üzletembernek, akinek munkájához elengedhetetlen a telefon használata, illetve egy nyugdíjas idõs hölgynek. Ezek az elõfizetõi csoportok azonban nem választhatók szét a rendelkezésre álló hívási információk alapján.
Határozzuk meg, hogy mit értünk egy elõfizetõ hívási szokásai alatt, vagyis hogy mit kell mégis modelleznünk! A hívási adataink (mely részletesen a 3. 2. 1. fejezetben kerül majd részletes bemutatásra) lényegében azt tartalmazzák, hogy az egyes felhasználók, mikor, milyen irányban és milyen hosszan telefonáltak. Ezekbõl az adatokból többféle származtatott adatot készíthetünk, melyek modellezése a célom. Ilyen származtatott adatok a következõk:
felhasználónként a legkorábbi és legkésõbbi hívás idõpontja a vizsgált idõszakban
hány hívást bonyolított a felhasználó egy adott hónapban
a felhasználó átlagos híváshossza
egy hónapban összesen hány percet telefonált
Természetesen ezeket az értékeket különbözõ bontásokban külön-külön is kiszámíthatjuk. Ilyen bontások lehetnek a következõk:
Hívás idõpontja szerinti bontásban
Ø hétköznap csúcsidõben
Ø hétköznap csúcsidõn kívül
Ø hétvégén
Hívás iránya szerinti bontásban
Ø helyi
Ø távolsági
Illetve ezek kombinációjaként például kiszámíthatjuk a hétköznap csúcsidõn kívüli, helyi hívások átlagos hosszát. Ezekbõl az adatokból és a különbözõ felbontásokból nagyszámú adatot tudunk származtatni az egyes felhasználókhoz, melyek jól leírják viselkedésüket.
Feladatom ezen értékek elõrejelzése, abban az esetben, ha egy felhasználó tarifacsomagot váltott. Természetesen az egyes felhasználókról feltételezhetjük, hogy a hozzájuk tartozó hívási adatok (hívások száma, átlagos híváshossz, hívások idõtartamának összege) a váltás után nem változik és így a váltás elõtti hónap adataival becsülhetjük. Hasonlóan jó becslés lehet, ha a felhasználók tarifaváltás elõtti összes hívási adata alapján számítjuk az értékeket és ezt vetítjük le egy hónapra majd feltételezzük, hogy a váltás után szintén ilyen paraméterekkel fog telefonálni.
Az adatbányászat eszközeivel viszont kihasználhatjuk, hogy már vannak olyan elõfizetõk az adatbázisban, akiknek tudjuk, hogy hogyan változtak meg a szokásaik váltásuk után. Ezen felhasználók segítségével egy modellt építve egy olyan felhasználóról is kiszámíthatjuk a hívási szokásainak peremétereit, akik még nem is váltottak át másik tarifacsomagra, vagy éppen most váltottak át. Ez üzleti szempontból nagyon fontos, melyrõl a következõ fejezetben esik szó.
Diplomatervem célja, tehát hogy olyan modellt alkossak, mely pontosabb becslést tud adni annál, mintha az adott felhasználó szokásának változását csak egyszerûen az elõzõ havi (váltás elõtti), vagy váltás elõtti életciklusának átlagával becsülnénk. Amennyiben ez sikerül, akkor tekinthetjük úgy, hogy az adatbányászati projekt elérte célját.
Az adatok elemzése során továbbá megtudhatjuk, hogy mennyire érzékenyek az emberek saját tarifacsomagjukra és így a saját pénztárcájukra, valóban megváltoznak-e a hívási szokásaik, ha új tarifacsomagba lépnek át. Megéri-e a szolgáltatónak olcsóbb tarifákat bevezetni és ezzel több elõfizetõt megtartani, illetve hogy többet telefonálunk-e a szükségesnél, ha bizonyos idõpontokban olcsóbban, vagy akár teljesen ingyen telefonálhatunk.
Elsõsorban a szolgáltatók számára nagyon fontos az elõzõ fejezet kérdéseinek megválaszolása. Napjaink üzleti világában elengedhetetlen, hogy egy-egy tarifacsomag bevezetése után kiszámítható legyen, hogy ez a szolgáltató számára milyen többlet költségekkel fog járni a jövõben, vagy mekkora többlet nyereség várható egy új számlázási rendszer megvalósítása esetén. Egy ilyen felhasználói modell segítségével elemezhetõ, hogy vajon egy rivális szolgáltató miért vezetett be egy adott új tarifacsomagot, esetleg nekünk is megérné-e hasonlót létrehozni.
Üzleti szempontból tehát nagyon fontos, hogy modellezzük egy elõfizetõ viselkedését, hiszen ezzel megtudhatjuk, hogy egy felhasználó melyik tarifacsomagról melyikre áttérve milyen paraméterekkel fog telefonálni. Ebbõl aztán költséget számíthatunk a telefonszolgáltató számára, meghatározhatjuk a tarifacsomagok percdíjait, melyekbõl aztán kiszámíthatjuk a bevételt és kiadásokat, illetve ezáltal a távközlési szolgáltató nyereségét.
Azonban a telekommunikációs szolgáltatók számára nem pusztán az anyagi értékek elõrejelzésére (prediktálására) használhatják ezt a modellt. Távközlési és informatikai szempontból is szükség van arra, hogy elõre lássuk egy-egy vonal terheltségét, kihasználását, hiszen a tervezések és fejlesztések során ezek az információk nélkülözhetetlenek. Ugyanakkor ennek a problémakörnek a megoldására a távközlési szolgáltatók jelentõsen túlméretezik saját kommunikációs hálózatukat, mert anyagi és üzleti okok miatt így gazdaságos számukra a jövõre nézve, és ezzel kerülik el a hálózat esetleges túlterheltségét.
Egy-egy új tarifacsomag bevezetése esetén létrejöhetnek kritikus idõpontok, amikor a hálózat terheltsége nagyon megnõ vagy lecsökken. Ezek kiszámításához szintén elengedhetetlen egy ilyen ügyfélmodell megalkotása.
A tanszéki projekt a T-Com távközlési cég megbízásából indult, a MTA-SZTAKI, a TMIT tanszék és az AITIA Rt. részvételével. A hívási információk tárolását és alapvetõ feldolgozását a SZTAKI tette lehetõvé számunkra. A tanszék adatvédelmi okok miatt kisebb módosításokkal kapta meg az adatokat a SZTAKI-tól, azonban ezek a módosítások az elemzés szempontjából irrelevánsak, így lehetõvé vált számunkra az adatbányászat ezeken hívási információkon.
A Távközlési és Médiainformatikai Tanszék a módosított adatokat tárolta és a SZTAKI a tanszéki szerveren is elérhetõvé tette az adatok kitömörítéséhez és alapvetõ feldolgozásához szükséges piped-mine nevû programot, melyet a SZTAKI fejlesztett ki.
Ez egy komponens alapú rendszer, mely erõsebb kapcsolatot jelent a komponensek között, mint az objektum orientáltság. Lényege, hogy adott egy komponens keretrendszer, melyet egyszer létrehoztak és ebbe a programozás során lehet behelyezni az egyes komponenseket. Ezen rendszer felépítését szemlélteti a . ábra.

. ábra A piped-mine keretrendszer
Mikor a komponenseket a rendszerbe helyezzük, a komponensek tudnak kommunikálni egymással, és a keretrendszerrel. Nekünk csak azt kell ismerni, hogy a "core" és közöttünk milyen interfész található. A rendszerben jelenleg hozzávetõlegesen 40-50 komponens található. Amennyiben valamelyiket használni szeretnénk, akkor ezeket bármilyen sorrendben egymás mögé rakhatjuk, szintaktikailag mûködni fognak, csak rossz esetben értelmetlen kimenetet kapunk. Illesztésekkel tehát nem szükséges foglalkozni. Ilyen módon a számunkra szükséges komponensek felhasználásával egy "csõvezetéket" (innen ered a rendszer neve is) építhetünk melynek a kimenetén megjelenik a számunkra szükséges adathalmaz.
A feladatunk tehát egy olyan konfigurációs fájl elkészítése, mely tartalmazza, hogy milyen komponensekbõl tettük össze a rendszert és azok hogyan kapcsolódjanak egymáshoz (melyik melyikkel álljon kapcsolatba). Tehát a konfigurációs fájl megírásánál a következõ információkat kell megadnunk:
melyik komponensbõl: pl. kitömörítõ, szûrõ (filter), aggregáló, hisztogram készítõ, fájlba író komponensek
hányat: szükség esetén természetesen több ugyanolyan komponens is egymás mögé fûzhetõ pl. több szûrõ komponens egymás után
kivel kommunikáljon: melyik másik komponenstõl kapja az információt és melyiknek adja tovább a "csõvezetékben"
A komponensek és a keretrendszer egy egységben vannak, melynek a mérete (csak az algoritmusokat tartalmazza) kb. 24 MB. A SZTAKI ezt a rendszert tette elérhetõvé számunkra a tanszéki szerveren, mivel az adatok tömörített formában vannak tárolva és a piped-mine segítségével megoldható, hogy csak azok az adatok kerüljenek kitömörítésre, melyekre a további elemzések során szükségünk lesz.
A keretrendszerrõl egy általam készített részletesebb útmutató található az irodalomjegyzékben .
Ez a Java alapú adatbányászati szoftver-rendszer lehetõvé teszi az üzleti tapasztalatokon alapuló elõrejelzõ modellek gyors kifejlesztését, és azok üzleti és a döntési folyamatokba való beillesztését. Mivel az SPSS a nyílt, egymással összekapcsolható eszközök híve, így a Clementine az iparág független CRISP-DM módszertant követi, mely a diplomatervem során rendkívül elõnyös. A Clementine nyitott architektúrája lehetõvé teszi a meglévõ IT befektetések megõrzését és felhasználását a rugalmas elemzési modell kialakításban és annak üzemelési folyamatokba történõ beépítésében.
Az alapvetõ szükséges adatok kiválasztása és kitömörítése után (melyet az elõzõ fejezetben ismertetett piped-mine rendszerrel végeztem el a tanszéki szerveren) az adatokat átmentettem a saját itthoni számítógépemre. Ezt követõen az adatok további átalakítását, a modellek megalkotását és értékelését itthon végeztem el a Clementine 11. 1. -es verziójával.
Intel(R) Core(TM)2 Duo E6750 2,66 GHz
3071 MB RAM
Háttértárolók: Samsung SP1614C 160 GB valamint 2 db Seagate Barracuda 7200. 10 320 GB (Raid1)
Windows Vista x64 operációs rendszer
Sun Java(TM) 6 Update 5
Clementine 11. 1.
Dual Opteron processzor
4 GB memória
Debian Linux operációs rendszer
Piped-mine keretrendszer
Az adatbányászati projekt következõ lépése az adatok megértése. Ekkor feltérképezzük, hogy milyen adatok állnak rendelkezésünkre, majd az elemzési célt figyelembe véve ezekbõl kiválogatjuk az elemzéshez szükséges adatokat. A kiválogatott adatokat részletesebben is megvizsgáljuk, hogy milyen típusúak, milyen értékkészletûek, grafikonokat készítünk az eloszlásukról. Elemezzük, hogy van-e hiányzó, vagy téves adat, illetve, hogy mennyire konzisztens az adatbázisunk. Ezek a lépések egy adatbányászati folyamat sarkalatos pontjai, hiszen itt dõl el, hogy mely adatokon fogunk dolgozni. Hibás, vagy téves adatok elronthatják a modell építését és végül hibás eredményekhez jutunk és a projekt sikerességét is veszélyeztetjük.
A SZTAKI által rendelkezésünkre bocsátott adathalmaz 54 attribútumot tartalmaz. A feladatunk ezek közül a számunkra lényegesek meghatározása. Az összes mezõ rövid leírása megtalálható a [M1] mellékletben, azonban az attribútumok beszédes neve miatt részletes tárgyalásukra itt nem térek ki. Általánosan elmondható, hogy a "D _ SZAM" kifejezést tartalmazó információ a hívó félre vonatkozik, míg a "B _ SZAM" a hívott félre vonatkozó attribútum.
Mivel diplomatervem feladata az ügyfelek telefonálási szokásainak vizsgálata, ezért olyan mezõket kell kiválasztanunk az 54 közül, melyek egy elõfizetõ szokásait jellemzi. Egy hívás legfõbb tulajdonságai ilyen szempontból, hogy milyen irányban telefonálunk, milyen idõpontban és természetesen, hogy mennyi ideig. Ezek alapján a következõ mezõket választottam ki az elemzéshez, melyeket az alábbiakban részletesen is bemutatok:
D _ SZAM: Ezen mezõ kiválasztása azért szükséges, hogy a hívó felet azonosítani tudjuk. Ez tulajdonképpen a hívó fél telefonszáma is lehetne, azonban adatvédelmi okok miatt ezek nem a tényleges hívó fél telefonszámai, hanem valamilyen módon azokból elõállított azonosító. Ez egy string típusú változó az adatbázisban.
D _ SZAM _ KORZET: Ez a mezõ a hívó fél körzetszámát tartalmazza. Azért van rá szükségünk, hogy meg tudjuk állapítani, hogy vajon az adott hívás az helyi, vagy távolsági hívás. Ezen kívül pedig szükség esetén akár demográfiai információk is visszafejthetõk ebbõl a mezõbõl. Ez a mezõ egész számokat tartalmaz, tehát integer[4] típusú.
D _ SZAM _ BIU: Ez tartalmazza azt az információt, hogy egy adott ügyfél milyen ügyfélcsoporthoz tartozik. Az adatbázisban több mint 182 ügyfélcsoport létezik, melyek az [M2] mellékletben hivatkozott helyen megtalálhatók. Azonban amennyiben ez a mezõ "1" értékû az minden esetben a lakossági, egyéni ügyfeleket tartalmazza. A diplomatervem . fejezetében részletezett okok miatt csak az egyéni elõfizetõket vizsgálom, cégek hívásinformációját nem. Így a késõbbiekben csak azokat a rekordokat tartottam meg, ahol ez a mezõ "1" értékû. A mezõben található adat integer típusú.
D _ SZAM _ UGYFEL _ VONALDARAB _ SZAMA: Az elemzések késõbbi fázisaiban fény derült arra, hogy egy felhasználó (azaz egy D _ SZAM) 60-70-szer váltott tarifacsomagot. Ez természetesen hibás feltételezés, melynek oka, hogy egy D _ SZAM-hoz több vonal is tartozik melyek más-más tarifacsomag szerint számlázódnak. Így eddig a lépésig vissza kellett lépni a CRISP-DM (2. 5. fejezet) metodika alapján és ezt a mezõt is felvenni a szükséges, vizsgálandó mezõk közé. Tehát ez a mezõ azt az információt tartalmazza, hogy a hívó fél számához hány tényleges vonal tartozik. A legtöbb rekord esetében ez tipikusan "1" értékû, de mint látjuk természetesen elõfordulhat, hogy egy számhoz több vonal is tartozik.
B _ SZAM _ KORZET: Ez a mezõ a D _ SZAM _ KORZET-hez hasonlóan, a hívott fél körzetszámát tartalmazza. Ez a mezõ szintén integer típusú. Szükséges ezen mezõ felvétele is, hiszen a D _ SZAM _ KORZET és a B _ SZAM _ KORZET mezõkkel együttesen tudjuk megállapítani az adott hívás típusát (helyi, helyközi, távolsági).
TARTASIDO: Ez a mezõ tartalmazza az adott hívás hosszát. Értéke egy egész szám, vagyis interger, mely a hívás hosszának másodpercekben kifejezett értéke.
HIVAS _ IDEJE: Ez az attribútum tárolja azt az információt, hogy az adott hívás mikor történt. Értéke egy nagy egész szám, mely az 1970. január 1. -e óta eltelt másodpercek száma az adott hívás idõpontjáig. A SZTAKI így tárolta a hívási idõpontokat ezért számunkra is ilyen meglepõ formátumban áll rendelkezésünkre.
TARIFACSOMAG _ KOD: Ez egy string típusú mezõ, mely a hívó fél tarifacsomagjának kódja. 48 féle lehetséges értéke van, melyek az [M3] mellékletben találhatók meg.
A hívási adatok a SZTAKI-tól a tanszéki szerverre kerültek, ahol a piped-mine keretrendszer szintén elérhetõ. A keretrendszerrõl részletesebb információ diplomatervem 3. 1. 3. 1. fejezetében található, valamint egy általam írt dokumentum is elérhetõ az irodalomjegyzék pontjánál.
Elkészítettem azt a konfigurációs fájlt, mely elvégezte a szükséges attribútumok kiválasztását. Mivel hatalmas méretû adathalmazról van szó (tömörítetten 28,5 GB) ezért az elõzõ fejezetben említett D _ SZAM _ BIU mezõ alapján már itt szétválasztottam az egyéni ügyfeleket a vállalati ügyfelektõl. Ehhez a mûvelethez a piped-mine-ban egy filtert definiáltam, mely kiválogatta azokat a rekordokat, melyekben D _ SZAM _ BIU "1" értékû. Ezzel hozzávetõlegesen a hívási adatok felét kiszûrtem az elemzés korai fázisában.
Ahogy az elõzõ fejezetben említettem a késõbbi elemzések szükségessé tették a D _ SZAM _ UGYFEL _ VONALDARAB _ SZAMA mezõ használatát is ezért erre is egy külön filtert írtam, mely csak azokat az ügyfeleket válogatta ki, melyeknek egy vonal tartozik a hívószámukhoz.
Elhagyva ezeket a számomra felesleges rekordokat egy sokkal kisebb méretû adathalmazt kellett csak a hálózaton átmásolnom az itthoni számítógépemre, melyen az elemzés további részét végeztem.
A piped-mine konfigurációs fájl, mely az adatok kitömörítését és a szükséges attribútumok kiválasztását végzi az [M4] mellékletben található.
A kitömörítés után célszerû az adatokat ismét összetömöríteni és így átmásolni a hálózaton, hiszen sok azonos karakter fordul elõ bennük, ezért nagy méretcsökkenés érhetõ el az eljárással. A hálózaton ilyen tömörített formában másoltam át a számomra szükséges adathalmazt. Az így átmásolt majd kitömörített adathalmaz mérete: 34 GB mely 687 481 666 rekordot és az elõzõ fejezetben megjelölt 8 attribútumot tartalmaz.
A SZTAKI 2005. október 3. -tól 2006. április 30. -ig tartó idõintervallum hívásait bocsátotta rendelkezésünkre tömörített formában.
A kitömörítés és a szükséges adatok kiválasztása után Clementine segítségével végeztem el az átmásolt adatok elemzését. Az adatbázisban csak a vezetékes hívásokat találtam, mivel az adatokat megvizsgálva a B _ SZAM _ KORZET oszlopban nem találtam mobil irányba menõ hívásokat, azaz 20-as, 30-as, 70-es körzetszámot.
A körzetszámokat tovább vizsgálva kiderült, hogy a leghosszabb hívási idõtartamok általában az 51-es körzet felé irányulnak. Ami nem is véletlen, hiszen az 51-es körzet a modemes internetszolgáltató körzetszáma. Mivel az adatok 2005. és 2006. évbõl származnak, ezért ebben az idõpontban még jelentõsebb volt a modemes internet kapcsolattal webezõk száma mint manapság, ezért ez jelentõs összeget jelent. Mivel diplomatervem célja a hívási szokások elemzése, ezért a továbbiakban az ilyen irányú hívásokat kivettem a további vizsgálatokból.
Az adatok megismerése sokszor grafikonokkal a legegyszerûbb és legszemléletesebb, így a kiinduló adatokból is készítettem ábrákat. Az adatokat Clementine segítségével összegeztem, majd az adatokat Microsoft Excelbe vittem át és ott készítettem el az ábrákat, melyek közül az alábbiak voltak érdekesebbek. A 3. ábraán a vizsgált idõszakban ábrázoltam az összes hívás összegét, minden elõfizetõre nézve. A grafikon függõleges tengelyén az adott nap lebonyolított összes hívás idõtartamának összegének percben kifejezett értéke látható. Kimagasló számot mutat a Karácsony és Szilveszter, ami érthetõ is, hiszen ekkor a legtöbben felhívjuk szeretteinket. A többi csúcsérték jellemzõen vasárnapi idõpontokat mutat, azonban ezek a csúcsértékek nem túlzottan magasak, így ezekbõl további szokási következmények nem vonhatók le.
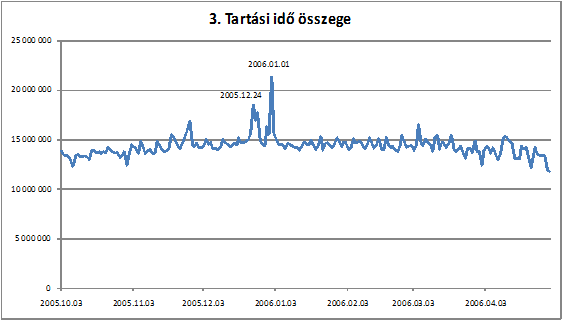
. ábra A tartási idõk összege a vizsgált idõintervallumban
A következõ ábrán (4. ábra) az adott napra esõ összes hívás idõtartamából egy átlagot számoltam. Ez látható a grafikon függõleges tengelyén másodpercekben kifejezve. Az ábrán jellegzetes "tüskék" láthatóak, melyek jellemzõen vasárnapra esnek. Ez azzal magyarázható, hogy az elõfizetõk még vasárnap, a következõ hét elõtt aránylag hosszabb idõtartamban beszélnek szeretteikkel. Mivel az adatbányászat korai fázisában már kiszûrtük csak az egyéni elõfizetõi hívásokat ( . fejezetben kifejtett okok miatt) ezért a grafikon a cégek hívásait nem tartalmazza, így valószínûleg nem a munka okok miatt indított hívások okozzák a kiugró vasárnapi értékeket.
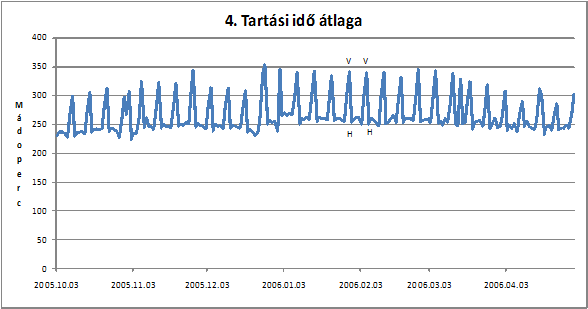
. ábra A tartási idõk átlaga a vizsgált idõintervallumban
A következõ ábrán ( . ábra) a vizsgált idõintervallumban az egyes napokon megszámoltam, hogy hány darab hívás történt. A "tüskék" ezen a grafikonon is jelentkeztek, azonban itt pont a fordított negatív irányban. Azaz a vasárnapi hívások darabszáma mindig kevesebb, mint az egyéb napokon indított hívások.
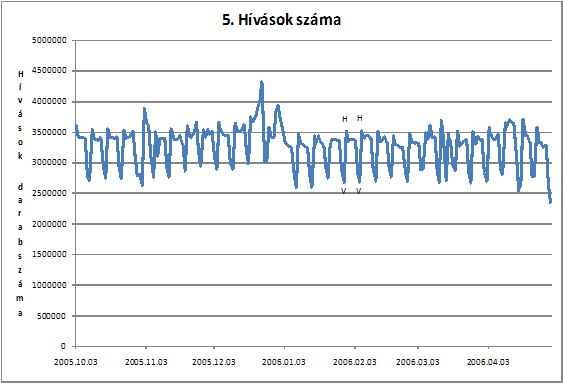
. ábra A hívások darabszáma az adott idõintervallumban
A 4. ábraés . ábra segítségével azonban egy fontos következtetést vonhatunk le a hívási szokásokról. Az ábrákon ugyanazt a két vasárnapi (2006. 01. 29. valamint 2006. 02. 05. ) és hétfõi (2006. 01. 30. valamint 2006. 02. 06. ) napot jelöltem meg, mivel általában ez a két nap jelenti a maximumokat és minimumokat. Vasárnap jellemzõen kb. 15%-al kevesebb hívást indítunk, mint hétfõn, viszont kb. 40%-al hosszabb (mely nagyjából 100 másodpercnek felel meg) idõtartamban beszélgetünk a hívott féllel. Ezzel szemben hétfõn több hívást indítunk, kisebb átlagos híváshosszal. Ez a megállapítás egy fontos hívási szokást jelent.
Azonban a hívásokat nem csak az egyes napokra összegezhetjük, hanem megvizsgálhatjuk azt is, hogy egy nap adott percében hány hívást indítottak. Mindegyik hívásról megállapítottam, hogy a nap mely percében történt, tekintet nélkül arra, hogy a hívás napja hétköznapra vagy hétvégére esett, majd ezeket összegeztem a 6. ábra. Az ábrán két jellegzetes "púpot"fedezhetünk fel. Az elsõ maximumát reggel 8:00 közelében éri el. Ezt követõen a délelõtt folyamán kicsit csökken a hívások száma, majd 14:30 körül ismét emelkedni kezd. A második "púp" délután 17:30 körül éri el a maximumát, majd innen fokozatosan csökken az indított hívások mennyisége. Az ábrán nagyon szembetûnõ még, hogy a második "púpon" belül tüskéket fedezhetünk fel, melyek szabályosan fél órás idõintervallumokkal követik egymást. Valószínûsítjük, hogy ennek oka szoros összefüggésben van a televíziózási szokásokkal, valamint az éppen akkor sugárzott adással. A mûsorok többsége általában egész órakor, vagy félkor kezdõdnek, így reklámok alatt megnõ a hívások mennyisége, majd a mûsor alatt nagymértékben rövid idõ alatt lezuhan. Végül egy érdekes momentum, hogy a nap végéhez közeledve 23:00-kor még egy utolsó ugrás van a hívások számában, melynek okát nem ismerjük biztosan.
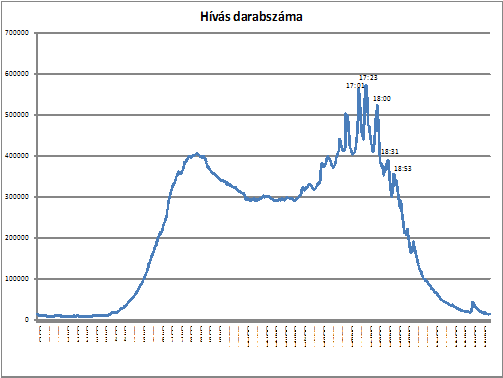
. ábra A nap perceiben indított hívások darabszáma
Az adatok további módosítását már az itthoni számítógépen végeztem el a Clementine adatbányászati szoftver segítségével, mivel ezeket a feladatokat csak sokkal nehezebben, vagy egyáltalán nem is lehetett megoldani a piped-mine keretrendszerben.
Az adatok ellenõrzésekor fény derült arra, hogy egy-két heti hívás információban a szokásos [M3] mellékletbeli tarifacsomag kódok helyet egész számok szerepelnek, melyeknek nem tudtuk a jelentését. Szerencsére ezen adatok kijavítása még idõben megtörtént, de szükségessé tette az összes eredmény újrafuttatását.
A 3. 2. 3. fejezetben említettem, hogy jelentõs hívási idõtartamot jelent az 51-es körzetbe irányuló hívás, vagyis a modemes internet. Ezeket a rekordokat Clementine segítségével eldobtam, mert a késõbbi modellezés jobb eredményeket produkált ezen rekordok elhagyásával.
A következõ fontos lépés a hívás idejének átalakítása volt, melyet a HIVAS _ IDEJE mezõ tartalmazott. Ez a mezõ a 3. 2. 1. fejezetben részletezett módon az 1970. január 1. -e óta eltelt másodperceket tartalmazza. Szerencsére a Clementine szoftverben elõre definiált függvények vannak ezen szám átalakítására, így ezeket a másodperceket jelentõ számokat könnyûszerrel átalakítottam. Megemlíteném, hogy mivel a tarifacsomagok általában egész órakor váltanak, ezért kezdetben elégségesnek láttam a hívás idõpontját úgy átalakítani, hogy dátumot, napot (a hét melyik napja) és órát kapjak. Azonban késõbb kiderült, hogy ez nem elegendõ és szükséges lenne percre pontosan tudni a hívások idõpontját. Ezért ismét vissza kellett lépni a CRISP-DM módszertan alapján és a perc attribútummal kibõvíteni az elemzési adathalmazt.
Ezeket az adattisztítási és átalakítási lépéseket elvégezve elõállt az az adathalmaz, melyben már csak egyéni elõfizetõk adatai vannak (akiknek egy vonaluk van), és nem tartalmaznak internetes hívásokat sem. Így már neki láthattam azon ügyfelek hívásainak kiválasztásához, akik váltottak tarifacsomagot. Ez az eredeti adathalmaz 2 026 352 egyéni ügyfélhez tartozó hívásokat tartalmazza.
Mivel diplomatervem feladata, hogy a tarifacsomagot váltott elõfizetõk szokását elemezzem, ezért a következõ feladatom az volt, hogy a tarifacsomagot váltott ügyfelek hívásait szétválasszam azoktól a hívás rekordoktól, melyek olyan ügyfelekhez tartoztak, akik nem váltottak tarifát.
Ehhez elõfizetõk azonosítója (D _ SZAM) szerint, majd idõ szerint sorba rendeztem a hívásokat, mivel a szerverrõl az adatok havi bontásban lettek átmásolva. Majd megállapítottam, hogy mely rekordpároknál fordul elõ az, hogy két idõben egymást követõ hívás esetén azonos D _ SZAM-hoz különbözõ TARIFACSOMAG _ KOD tartozik, azaz mely ügyfeleknél történt váltás. Ezen ügyfelekbõl egy új adathalmazt készítettem, mely tartalmazta az ügyfelek azonosítóján kívül a tarifacsomag váltását (melyik tarifáról melyikre) illetve a váltás idõpontját.
Persze fél éves idõintervallumban megesik, hogy egy ügyfél akár 2-szer 3-szor is vált tarifacsomagot. Kétszer váltott tarifacsomagot, 50 186 ügyfél és háromszor 8 086 ügyfél. Azonban ez a szám túl nagy és csak nehezítik a késõbbi modellezést, ezért kiválogattam azokat az ügyfeleket, akik csak egyszer tértek át másik számlázási rendszerbe. A futtatás végére 321 191 ilyen ügyfelet találtam, melyet a kiindulási ügyfélszámmal összevetve kiszámítható, hogy fél év alatt az ügyfelek 15,85%-a váltott egyszer számlázási csomagot.
Eloszlás a váltásokról az idõintervallumban
Melyik tarifáról melyikre váltottak sokan
Melyik tarifacsomag párt választottam és miért, tarifacsomag információ a netrõl
Join, havonként és miért.
Az elõbbi két adathalmazt az ügyfél azonosítója alapján összeillesztettem (join), így egy olyan hívási adathalmazt kaptam, amiben csak a tarifacsomagot váltott ügyfelek hívásrekordjai vannak. Ez az adathalmaz ????61 639 742???? rekordot tartalmaz és mérete ????3,6 GB????. Ez mekkora méretû, hány rekordja van.
A két tábla összeillesztése, azokhoz a userekhez tartozó rekordok kiválasztása akik váltottak. Problémák, így hány rekord, mekkora méretû.
Hány rekordból hány lett így, ezek mekkora méretûek
További bontás: azon hívásrekordok kiválasztása, akik egy bizonyos tarifáról egy másikba mentek át
Váltás elõtti hívás-e, melyik hívási típusba esik. A vektor hogyan épül fel, melyik mezõbõl épül fel, hogy bontottuk fel a hetet.
Prediktálás - elõrejelzés
CRISP-DM - CRoss Industry Standard Process for Data Mining, Iparágfüggetlen Szabványos Adatbányászati Módszertan
Business Understanding - Üzleti célok meghatározása
Data Understanding - Az adatok megismerése
Data Preparation - Adatelõkészítés
Modeling - Modellek alkotása
Evaluation - Eredmények kiértékelése
Deployment - Az eredmények üzleti szintû alkalmazása
Filter - szûrõ
Piped-mine - A SZTAKI által fejlesztett komponens alapú keretrendszer
pipestartOrig. headerfields = D _ SZAM
pipestartOrig. headerfields = D _ SZAM _ KORZET
pipestartOrig. headerfields = D _ SZAM _ UGYFELCSOPORT
pipestartOrig. headerfields = D _ SZAM _ BIU
pipestartOrig. headerfields = D _ SZAM _ INSTALLATION _ LINE _ NR
pipestartOrig. headerfields = D _ SZAM _ VONAL _ KEZDO _ DATUM
pipestartOrig. headerfields = D _ SZAM _ LESZERELES _ DATUM
pipestartOrig. headerfields = D _ SZAM _ TELEPULESNEV
pipestartOrig. headerfields = D _ SZAM _ OSS _ TERMEK _ KOD
pipestartOrig. headerfields = D _ SZAM _ ADSL _ FLAG
pipestartOrig. headerfields = D _ SZAM _ MEGSZUNTETES _ TIPUS
pipestartOrig. headerfields = D _ SZAM _ UZEMSZUNET
pipestartOrig. headerfields = D _ SZAM _ HITELKEPESSEG
pipestartOrig. headerfields = D _ SZAM _ FIZETOKEPESSEG
pipestartOrig. headerfields = D _ SZAM _ UGYFEL _ VONALDARAB _ SZAMA
pipestartOrig. headerfields = D _ SZAM _ VONALALLAPOT
pipestartOrig. headerfields = D _ SZAM _ NATURE _ OF _ LINE
pipestartOrig. headerfields = D _ SZAM _ SERVICE _ CATEGORY
pipestartOrig. headerfields = D _ SZAM _ VONALTIPUS
pipestartOrig. headerfields = D _ SZAM _ FIZIKAI _ MEGVALOSITAS _ KOD
pipestartOrig. headerfields = D _ SZAM _ AHIER2 _ KOD
pipestartOrig. headerfields = D _ SZAM _ VALOS _ VONAL
pipestartOrig. headerfields = D _ SZAM _ KSH _ KOD
pipestartOrig. bodyfields = B _ SZAM
pipestartOrig. bodyfields = B _ SZAM _ KORZET
pipestartOrig. bodyfields = TARTASIDO
pipestartOrig. bodyfields = IMPULZUSSZAM
pipestartOrig. bodyfields = UJRADIJAZOTT _ OSSZEG
pipestartOrig. bodyfields = KORREKCIOS _ OSSZEG
pipestartOrig. bodyfields = OCP _ KEDV _ OSSZEG
pipestartOrig. bodyfields = HIVAS _ IDEJE
pipestartOrig. bodyfields = TARIFACSOMAG _ KOD
pipestartOrig. bodyfields = OSS _ TERMEK _ KOD
pipestartOrig. bodyfields = B _ SZAM _ UGYFELCSOPORT
pipestartOrig. bodyfields = B _ SZAM _ BIU
pipestartOrig. bodyfields = B _ SZAM _ INSTALLATION _ LINE _ NR
pipestartOrig. bodyfields = B _ SZAM _ VONAL _ KEZDO _ DATUM
pipestartOrig. bodyfields = B _ SZAM _ LESZERELES _ DATUM
pipestartOrig. bodyfields = B _ SZAM _ TELEPULESNEV
pipestartOrig. bodyfields = B _ SZAM _ OSS _ TERMEK _ KOD
pipestartOrig. bodyfields = B _ SZAM _ ADSL _ FLAG
pipestartOrig. bodyfields = B _ SZAM _ MEGSZUNTETES _ TIPUS
pipestartOrig. bodyfields = B _ SZAM _ UZEMSZUNET
pipestartOrig. bodyfields = B _ SZAM _ HITELKEPESSEG
pipestartOrig. bodyfields = B _ SZAM _ FIZETOKEPESSEG
pipestartOrig. bodyfields = B _ SZAM _ UGYFEL _ VONALDARAB _ SZAMA
pipestartOrig. bodyfields = B _ SZAM _ VONALALLAPOT
pipestartOrig. bodyfields = B _ SZAM _ NATURE _ OF _ LINE
pipestartOrig. bodyfields = B _ SZAM _ SERVICE _ CATEGORY
pipestartOrig. bodyfields = B _ SZAM _ VONALTIPUS
pipestartOrig. bodyfields = B _ SZAM _ FIZIKAI _ MEGVALOSITAS _ KOD
pipestartOrig. bodyfields = B _ SZAM _ AHIER2 _ KOD
pipestartOrig. bodyfields = B _ SZAM _ VALOS _ VONAL
pipestartOrig. bodyfields = B _ SZAM _ KSH _ KOD
Excel táblázat, mely az ügyfeleket tartalmazza:
https://www. hszk. bme. hu/~fg497/dm/doc/ugyfelcsoport _ biu. xls
Row # TARIFACSOMAG _ KOD TARIFACSOMAG _ NEV
1 U Ismeretlen
2 U Bázis csomag
3 BBB Barangoló
4 CBC CBC LTO-S tcs.
5 FAV Favorit usp.
6 HTC Bázis csomag
7 KKK Kontroll
8 OPE Optimist üzl.
9 RUE Ritmus üzl. egy.
10 SOK Új sokatm. tcs.
11 SOK Sokatmondó tcs.
12 TBO Turbo ISDN. tcs.
13 TST Teszt díjcsomag
14 V8V V8 vállalkozói
15 BELU Belföldi csomag
16 BIZU Minimál díjcsom
17 BPLU Csevegõ díjcsom
18 FPLU Favorit Plusz
19 HETU Hétvégi csomag
20 KORM Kormányzati tcs
21 MINU Mindenkinek cs.
22 R100 Ritmus100
23 R200 Ritmus200
24 R300 Ritmus300
25 RITU Ritmus csomag
26 RUZL Ritmus üzleti
27 SPEC Speciális tcs.
28 UFEL Üzleti felezõ
29 UTBO Üzleti turbó
30 VOCA VoCATV díjcs.
31 BAZIS Bázis díjcsom.
32 TPCBC Teleperc CBC
33 TPERC Teleperc dcs.
34 TPPAR Teleperc Part.
35 WIMAX WIMAX USP.
36 FELEZO Felezõ tcs.
37 LTCSEV Csevegõ LTO tcs
38 RCSUCS Ritmus csúcs
39 RHELYI Ritmus helyi
40 RMOBIL Ritmus mobil
41 RSTAND Ritmus standard
42 FEPLUSZ FelezõPlusz tcs
43 LTOCSEV Csevegõ LTO tcs
44 LTOR100 R100 CBC tcs.
45 R1PLUSZ Ritmus100+
46 R2PLUSZ Ritmus200+
47 R3PLUSZ Ritmus300+
48 RBELFOLD Ritmus belföldi
###
Ez a komponens vegzi a fajlba irast
### letrehozzuk majd beallitjuk a parametereit
create. coord = textwriter
coord. filename = fg200510. txt
coord. writeheader = 1
coord. separator = |
#coord. link = pipestartOrig
#coord. link = dbg
coord. link = filterelementLakossag
###
Ez egy szuro, mely csak a lakossagi elofeizetoket valogatja ki
### azaz azokat a sorokat, ahol D _ SZAM _ BIU = 1
create. filterelementLakossag = filterelement
filterelementLakossag. link = filterelementVonaldarab
filterelementLakossag. create. int32filter1 = int32filter
filterelementLakossag. int32filter1. field _ name = D _ SZAM _ BIU
filterelementLakossag. int32filter1. op = ! =
filterelementLakossag. int32filter1. value = 1
filterelementLakossag. filterobject = int32filter1
###
Az 1 vonaldarabszamu ugyfelek kivalogatasa
### azaz ahol D _ SZAM _ UGYFEL _ VONALDARAB _ SZAMA = 1
create. filterelementVonaldarab = filterelement
#filterelementVonaldarab. link = dbg
filterelementVonaldarab. link = pipestartOrig
filterelementVonaldarab. create. int32filter2 = int32filter
filterelementVonaldarab. int32filter2. field _ name = D _ SZAM _ UGYFEL _ VONALDARAB _ SZAMA
filterelementVonaldarab. int32filter2. op = ! =
filterelementVonaldarab. int32filter2. value = 1
filterelementVonaldarab. filterobject = int32filter2
###
Ez egy hasznos debug eszkoz,
### ez csak maxnumbernyi embert porget vegig a rendszeren
create. dbg = sampling _ debug
dbg. link = pipestartOrig
dbg. maxnumber = 50000
###
Ez a kitomorito elem, itt adom meg hogy melyik filebol dolgozzon
### es hogy milyen mezoket csomagoljon ki.
### A kitomorito elem neve legyen: pipestartOrig
create. pipestartOrig = decoder
#### Ekkor a temp file-okat eltunteti maga utan
#pipestartOrig. file _ operation = -1
#### Ekkor meghagyja a temp file-okat
#pipestartOrig. file _ operation = 0
#### Ekkor kepes meglevo tempfileokbol dolgozni
#pipestartOrig. file _ operation = 1
### Bementi fajlok megadasa
pipestartOrig. sourcefilename = /export/1/compressed _ data/20051003-20051009. dat
pipestartOrig. sourcefilename = /export/1/compressed _ data/20051010-20051016. dat
pipestartOrig. sourcefilename = /export/1/compressed _ data/20051017-20051023. dat
pipestartOrig. sourcefilename = /export/1/compressed _ data/20051024-20051030. dat
### A kivant attributumok beallitasa
pipestartOrig. headerfields = D _ SZAM
pipestartOrig. headerfields = D _ SZAM _ KORZET
pipestartOrig. headerfields = D _ SZAM _ BIU
pipestartOrig. bodyfields = B _ SZAM _ KORZET
pipestartOrig. bodyfields = TARTASIDO
pipestartOrig. bodyfields = HIVAS _ IDEJE
pipestartOrig. bodyfields = TARIFACSOMAG _ KOD
Találat: 5488