 | |||||||||
|  | ||||||||
| |||||||||
| | ||||||||
| kategória | ||||||||||
|
|
||||||||||
|
|
||
AZ INTERNET
Az Internet I.
Az Internet - a közhiedelemmel ellentétben - jóval összetettebb, mint hálózatba kötött számítógépek sokasága. Az Internet valójában a hálózatok többszörös hálózata.
Az Internet kezdetei valahol a hatvanas években kezdödtek, amikor is az USA védelmi minisztériuma egy, a katonaság és a kormányzat számára kialakított titkos hálózat, az ARPANET (Advanced Research Projects Agency Network) építését határozta el. A hálózattal szemben támasztott követelmények a szabad fejleszthetöség, a - biztonsági korlátoktól eltekintve - teljes átjárhatóság, a lehetöségekhez képest gyors müködés, a megbízhatóság és az akár teljes szegmensek kiesése esetén is tovább-müködés képe 919i86j ssége volt. Ezen igények alapvetöen meghatározták a hálózati architektúrát és a rajta alkalmazható protokollok fö tulajdonságait.
A Hálózat modularitását és viszonylag gyors müködését fa-struktúrájú topologiája biztosítja, ami lehetövé teszi a csomagok gyors és biztos továbbítását a célállomás felé, elhelyezkedésének közvetlen ismerete nélkül is. A Hálózat elemei az egységes Internet-protokoll, a TCP/IP révén képesek egymással kommunikálni - ezt biztosítja a hálózat bármely két pontja közötti kapcsolat-létesítés lehetöségét.
A TCP/IP protokoll
Általános elterjedt fogalom a "TCP/IP protokoll" - gyüjtöfogalomként, az Internet-en és a hozzá kapcsolodó alkalmazásokban használt protokollok összességét ezen a néven emlegetik Valójában maga a név sem egyetlen protokollt, hanem egy - az Inteneten leggyakrabban használt- átviteli protokoll-párost: a TCP (Transmission Control Protocol - átvitel-vezérlö protokoll) és az IP (Internet Protocol) kettösét jelenti.
Az Interneten alkalmazott protokollok egy része ún. alacsony szintü (low-level) protokoll, melyek generális átviteli és adatcsere feladatokra használhatók és amelyekre a magasabb szintü protokollok épülnek. Ilyen alacsony szintü protokoll a TCP, az IP, az UDP vagy a PPP. Más, magasabb szintü protokollok specifikus feladatok végrehajtására alkalmazhatóak: fájlok átvitelére (FTP), levelek küldésére és fogadására (SMTP és POP) vagy távoli futtatásra (TELNET) - ezek az Internet klasszikus alkalmazásai.
A TCP/IP rétegezett protokoll-készlet, azaz a teljes átviteli eljárás jól meghatározott, diszkrét feladatcsoportokra bontható. A legmagasabb szinten van az alkalmazási réteg, például a levelezési protokoll. Ez a protokoll a gépek közti kommunikáció, azaz a címezett és a feladó valamint magának az üzenet szövegének a meghatározására használt utasításokat és az ezekkel összefüggö szabály-rendszert határozza meg. Ez a protokoll azonban egy, a két gép közt fennálló megbízható kapcsolatot feltételez. E megbízható adatcsere fenntartásának biztosítására használható a TCP protokoll - az ö feladata az elküldött csomagok a célállomásra történö megérkezésének biztosítása. A TCP nyilvántartja az elküldött csomagokat és ha kell újraküldi azt amelyik valamilyen okból nem ért célba. Ugyancsak az ö feladata az átviendö adatblokk a hálózat által feldolgozható csomagokba történö szabdalása, illetve azok helyes sorrendben történö összeállítása a célállomáson. A TCP réteg a csomagokat az IP protokoll (a minden alkalmazás által igényelt funkciókat implementáló réteg) felé továbbítja - ez utóbbi feladata az egyes csomag elküldése a célállomás felé ill. azok fogadása azon. Az IP a csomagokat a legalsó réteg: a fizikai hálózati médiumot (pl. Ethernet, modem, stb.) kezelö réteg felé továbbítja ill. fogadás esetén attól kapja meg.
A hálózati protokollok rétegezése az alkalmazások sokrétüségében és felhasználásának rugalmasságában rejlik. Például nem minden alkalmazásnak van szüksége megbízható adatkapcsolatra a küldö és a fogadó állomás között: egy élö video-sugárzást továbbító (szóró) alkalmazás számára elég, ha közvetlenül az IP réteggel kommunikál, hiszen számára nincs jelentösége (söt!) egy-két adatcsomag elvesztésének az alkalmazás jellegéböl adódóan.
A TCP/IP olyan hálózatokon tud effektíven müködni, ahol nagy számú csomagkapcsolt (al)hálózat áll egymással összeköttetésben átjárókon (gateway) keresztül (ezt a fajta hálózatok-hálózatát szokás "catenet"-nek hívni). Ilyen hálózatokban az adatcsomagok általában (al)hálózatok tucatjain vándorolnak keresztül mire elérnek rendeltetési helyükre, a célállomásra. A müvelet elvégézéséhez szükséges útvonal-vezetésnek (routing) azonban teljesen átlátszónak kell lennie az alkalmazási réteg számára - neki mindössze a célállomás "Internet-címét" kell tudnia. Az Internet-cím (az IPv4-es protokollban) egy 32-bites szám, amely 4 darab, egyenként 8 bites számmá van felosztva a mindenki ismert pontokkal elválaszott formátumban (pl. "192.234.16.1"). Ez a hálózat topológiájából eredö (de a felhasználó számára kis mértékben érdekes) felbontás egyben a cím megjegyzését is könnyebbé teszi. A még egyszerübben megjegyezhetö DNS neveket (pl. "www.company.com") a számítógép úgynevezett név-szerverek (name server) segítségével fordítja tényleges IP címekké.
A TCP/IP alapvetöen üzenet(datagram)-alapú (kapcsolat nélküli) protokoll. Az üzenet adatok csoportja mely egyetlen, összefüggö egységként kerül elküldésre. Bár magasabb szintü (a TCP/IP-re épülö) protokollok létrehozhatnak kapcsolat-alapú átviteli csatornákat is, ezen csomagok mindegyike különálló darabként került átvitelre a hálózaton, amely nem is tud(hat)ja, hogy ezek valójában esetleg egymással szorosan összefüggö, folyamatos adatfolyamot alkotnak. Például egy több száz kilobájtos fájl átvitele nem történhet meg egyetlen csomagban, hiszen a legtöbb hálózati médium nem képes ilyen nagy méretü blokkok átvitelére, így a protokoll ezeket több, általában 512 bájt méretü darabra "vágja fel", amelyek mindegyike a másik oldal felé kerül elküldésre. A túloldalon aztán újból összeállításra kerülnek és egyetlen csomagként jutnak el az alkalmazási réteg felé. Az egyes csomagok azonban az utazás közben akár teljesen eltérö csatornákon - és ebböl eredöen - a küldésitöl teljesen eltérö sorrendben érkezhetnek meg a túloldalra, ahol azonban a protokoll feladata helyes sorrendbe állításuk és összefüzésük.
A TCP (protokoll)
A TCP feladata az üzenet-csomagok esetleges darabolása, azok rendbe- és összeállítása a túloldalon, valamint az esetlegesen elveszett rész-csomagok újraküldése, ezáltal két pont közt egy megbízható átviteli csatorna biztosítása. Az adatátvitel során (az OSI modellnek megfelelöen) a két TCP szint "beszélget" egymással az alattuk elhelyezkedö réteget (pl. IP) felhasználásával. Az adatkapcsolat kezdetén a két TCP szint megegyezik egymással a legnagyobb, mindkét hálózat által egy egységként feldolgozható rész-csomag (chunk) méretében. A továbbiakban minden átvitelre kerülö üzenet-csomagot a küldö fél maximálisan ekkora méretü darabkákra "szabdal fel". A csomag vétele után a fogadó TCP réteg egy nyugtázást (acknowledge) küld vissza a már fogadott rész-csomagok megjelölésével. Amennyiben a küldö fél megadott idön belül nem kap ilyen nyugtázást úgy a kérdéses csomagot újraküldi. Mivel nem effektív minden egyes csomag küldése után annak nyugtázását megvárni, ezért a TCP réteg egy ún. sliding window technikát alkalmaz. Ez azt jelenti, hogy egyszerre (az elözöek nyugtázása nélkül is) több csomagot is útjára bocsát a célállomás felé, majd a window limit (az egyszerre úton lévö csomagok maximális száma) elérésekor megvárja a nyugtázásokat.
A TCP a csomagok továbbításakor az alsóbb rétegek felé egy ún. TCP fejlécet illeszt azok elé. Ez a fejléc a küldö- és a célállomás IP címének megjelölése mellett a két pont közti kapcsolatot azonosító egyedi kapukat (port) és egy sorszámot is tartalmaz. A kapu-azonosítók a két azonos csomópont közti párhuzamos üzenet-átviteli csatornák megkülönböztetésére szolgálnak. A sorszám mezö kapcsolat folytonosságának, azaz az esetlegesen meg nem kapott csomagok ill. az összeállítási sorrend megállapítására használhatóak. Ez a mezö azonban nem a csomag sorszámát (1,2,3...stb.) hanem az adott csomag elsö bájtának az üzeneten belüli elhelyezkedését adja meg. Így az 512 bájtos darabokban átvitt üzenetek csomagjainak sorszám mezöi rendre a 0, 512, 1024 stb. értékekeket fogják kapni. Ezen kívül a fejléc rendelkezik még egy ellenörzö-összeg (checksum) mezövel is, melynek segítségével az átvitel fizikai hibái is kiszürésre kerülhetnek.
Az Internet II.
Az elözö részben áttekintettük a Hálózat müködését és megismerkedtünk müködtetésében résztvevö protokollok általános jellemzöivel. Most folytatjuk a TCP/IP protokollpáros müködésének leírását, valamint megismerkedünk az alkalmazási protokollok jellemzöivel és müködésükkel.
A TCP/IP protokoll (folytatás)
A TCP után most ismerkedjünk meg az IP (protokollal). (Azért rakosgatom a TCP, IP, stb. után zárójelbe a "protokoll" szót, mert ugye az már magában mozaikszóban is benne van (pl. IP - Internet PROTOKOLL) és így igazából nem szabadna kiírni utána - nélküle mégis furcsán hangzanak.)
Az IP (protokoll)
Mint azt az elözöekben tisztáztuk a TCP feladatai közé tartozik az alkalmazási réteg (pl. FTP protokoll) felöl érkezö üzenetek az IP (vagy valamilyen öt helyettesítö protokoll) által már feldolgozható darabokra, azaz csomagokra bontása. Az IP protokoll egyetlen feladata a TCP réteg felöl érkezö adatcsomagok eljuttatása a meghatározott célállomásra. A protokoll az átvivendö csomagot az alsóbb réteg felé történö továbbítása elött egy IP-fejéccel látja el. Ez a fejléc a forrás- ill. a célállomás IP címén, valamint a csomagok sorrendjét meghatározó információn kívül egy ún. protokoll-számot és egy ellenörzö-összeget is tartalmaz. A protokoll-szám jelentösége annak meghatározása, hogy a célállomáson az IP réteg a csomag fogadása után azt melyik felsöbb réteg (protokoll) felé továbbítsa (erre azért van szükség mert az IP protokoll szolgáltatásait nem feltétlenül csak a TCP, hanem más azonos szintü protokollok is használhatják).
Az alkalmazási réteg és a socket-ek
Az elöbbiekben tisztáztuk, hogyan juttathat el információt az alkalmazási réteg a TCP/IP protokollpáros felhasználásával a Hálózat egyik pontjából egy másikba. De hogyan tudja az egyik számítógép "megmondani" a másiknak, hogy az fogadjon egy üzenetet vagy küldjön el egy fájlt? Nos, az adatátvitelnél magasabb szintü müveletek elvégzése az ún. alkalmazás-protokollok feladata. E protokollok mindegyike a TCP (protokollra) épül, azaz futása során annak szolgáltatásait felhasználva kommunikál a Hálózaton. A TCP biztosítja az elküldött adatok átvitelét a célállomásra, ezáltal az alkalmazási protokollok számára egy bájtfolyam-jellegü, telefonvonalhoz hasonló - látszólag - közvetlen, megbízható adatkapcsolatot nyújtva.
De hogyan nyílik lehetöségünk annak meghatározására, hogy a kommunikáció során az egyetlen hálózati csomóponton (gépen) esetlegesen elérhetö több alkalmazási protokoll közül melyikhez intézzük kérésünket? E probléma megoldására a TCP protokoll logikai csatornákat, ún. socket-eket (csatlakózókat) definiál. Amikor egy alkalmazási protokollt aktiválnak egy kiszolgálón, akkor egy egyedi - általában jól ismert és elöre meghatározott - sorszámú socketet (portot) nyitnak meg a számára. A TCP réteg a beérkezö csomagokat mindig a csomag által meghatározott port, azaz alkalmazási protokoll felé fogja továbbítani. Ezek után a kliens-alkalmazásoknak nincs más dolguk, mint hogy kéréseiket a célállomás azon socket-je "felé" intézzék, amelyiket az adott alkalmazás szerver-protokollja felügyel. Amennyiben az alkalmazások véletlenszerüen vagy pl. indítási sorrendnek megfelelöen foglalnák le maguknak a különbözö socket-számokat, úgy a szolgáltatások eléréséhez nyilvánvalóan minden egyes szerverröl pontosan tudnia kellene a kliens alkalmazásnak, hogy az adott gépen a szerver-protokollnak milyen sorszámú socket-et sikerült megnyitnia. Ennek elkerülésére az általános célú, szabványosított protokollok gépenként eltérö, véletlenszerü, hanem minden gépen azonos sorszámú socket-en keresztül érhetöek el (pl. az FTP szerver-protokoll a 21-es portra "ül rá"). (Nyilvánvalóan a kliens oldalon ez a probléma nem lép fel - magyarul: ott nem érdekes, hogy éppen milyen sorszámú socketet sikerül "megkaparintani" a kapcsolat megnyitásának kezdetén - hiszen az elsö (a kapcsolatot megnyitó) csomag a szerver felé történö elküldése után az a fogadott TCP-fejlécböl már könnyen megállapíthatja a kezdeményezö alkalmazás socket-számát.) E "foglalt" port-számokat és a hozzájuk kapcsolódó szabványosított protokollokat tartalmazó listát "Assigned Number" (Hozzárendelt Számok) címmel idöröl-idöre közzéteszi az Internet-et "felügyelö" Network Working Group.
A fentieknek megfelelöen egyetlen kapcsolatot összesen két számpáros határoz meg: a küldö ill. a fogadó oldal Internet címei, valamint a küldö ill. fogadó oldali port-szám. E négy szám közül bármelyiket megváltoztatva egy újabb logikai csatornát definiálunk. Ennek megfelelöen nyugodtan elképzelhetö, hogy ugyanaz a kliens gép ugyanarról a szerverröl párhuzamosan két fájl-átviteli müveletet is végrehajtson. Ez esetben a kapcsolatot meghatározó számpárosok valahogyan így nézhetnek ki:
|
|
Kliens Internet-címe |
és port száma |
Szerver Internet-címe |
és port száma |
|
Kapcsolat 1 |
|
|
|
|
|
Kapcsolat 2 |
|
|
|
|
Mivel mindkét kapcsolat során azonos gépek kommunikálnak egymással ezért mindkét kapcsolat kliens és szerver oldali IP-címei is egyeznek, és mivel mind a kettö során fájl-transzfer történik az FTP protokoll felhasználásával, ezért mindegyiket a kliens oldal ugyanahhoz a jól ismer, szabványosított szerver oldali socket-hez címzi megnyitásakor. Az egyetlen eltérés - ami azonban elég a kapcsolatok megkülönböztetéséhez és a csomag szétválasztásához - az a kliens oldali port-szám.
Maga az alkalmazási-protokoll felépítése és müködése általában jóval egyszerübb, mint az alatta elhelyezkedö rétegeké. Az alkalmazási-protokollok általában a két fél által megértett parancsok, valamint az esetleges adatátvitel módjának és szabályozásának meghatározására korlátozódnak.
A hagyományos Internet alkalmazási-protokollok (mail, FTP, stb.) a két fél közti parancsokat és a válaszokat általában standard ASCII formátumban küldik el egymásnak. E megoldás egyértelmü hátránya a sávszélesség rossz kihasználása a bináris átvitelhez képest (éppen ezért a tisztán bináris adatokat általában nem ilyen módon küldik), vitathatatlan elönye azonban platform-függetlensége (hiszen a standard ASCII jelkészletet használja, így nem okozhat problémát a két kommunikáló fél esetlegesen eltérö szó-mérete, vagy bájt-sorrendje) valamint az, hogy a parancsok valamint üzenetek (lévén szövegesek) ember által is könnyen olvasható formában kerülnek elküldésre, ezáltal elösegítve az adatcsere felügyelését (monitoring) valamint esetlegesen azok közvetlen kiadását (célalkalmazás nélkül) is egy egyszerü terminálprogram segítségével.
Egy konkrét alkalmazás: az SMTP
A könnyebb érthetöség érdekében lássunk egy tipikus levél-küldési folyamatot az SMTP (Simple Mail Transfer Protcol - Egyszerü Levél-Átviteli Protokoll) (protokoll) segítségével. E protokoll segítségével nyílik lehetöségünk a munkaállomásunkon megírt levél elküldésére egy Internet-postafiókba.
Tegyük fel, hogy a
"Hétfön mennek a cikkek.
Az operációs rendszerröl majd beszélünk."
üzenetet szeretnénk elküldeni barátunknak az 'proghu@freemail.hu' postafiókra.
Magának a levélnek a formátumát, azaz a feladó, a címezett, maga üzenet és esetleges egyéb információk kódolását, sorrendiségét és megjelenítését az RFC822-es dokumentum (lásd késöbb) definiálja. Az ennek megfelelö formára történö hozás után az üzenetünk (nagyon leegyszerüsítve, minimális tartalommal) valahogyan így néz ki:
"Date: Sun, 03 Jan 99 20:59:27 CET
From: sting@freemail.hu
To: proghu@freemail.hu
Subject: Cikkek
Hetfon mennek a cikkek.
Az operacios rendszerrol majd beszelunk."
A levelet elküldeni szándékozó program elöször is megnézi, hogy mi a címzett mail-szerver (freemail.hu) IP-címe a címfordító-szolgáltatás (DNS) segítségével. Ennek megállapítása után egy adatcsatornát próbál nyitni a távoli gép (a mail-szerver) felé. A csatorna megnyitása során a DNS-szervertöl kapott IP-címet és a SMTP által használt standardizált 25-ös port számot használja fel a célcím meghatározására. A kapcsolat megnyitása után a következö "beszélgetés" folyik le a munkaállomás és a mail-szerver között (WKST a munkaállomás, FREE a levelezö-kiszolgáló):
FREE 220 FREEMAIL.HU SMTP Service at
03 Jan 99 21:00:35 CET
WKST HELO 192.234.4.1
FREE 250 FREEMAIL.HU
WKST MAIL From: <sting@freemail.hu>
FREE 250 MAIL accepted
WKST RCPT To: <proghu@freemail.hu>
FREE 250 Recipient accepted
WKST DATA
FREE 354 Start mail input; end with
<CRLF>'.'<CRLF>
WKST Date: Sun, 03 Jan 99 20:59:27 CET
WKST From: sting@freemail.hu
WKST To: proghu@freemail.hu
WKST
WKST Hetfon mennek a cikkek.
WKST Az operacios rendszerrol majd beszelunk.
WKST .
FREE 250 OK
WKST QUIT
FREE 221 FREEMAIL.HU Service closing
transmission channel
Mint az a fentiekböl látható a teljes átvitel során tisztán ASCII formátumú szöveges kommunikáció zajlik a két gép között. Ezen kívül megfigyelhetö, hogy a mail-szerver által küldött üzenetek mind egy számmal kezdönek. Ennek jelentösége a gép-gép közti kommunikáció során van, hiszen amennyiben a küldö fél gép (program), azaz a felhasználó nem egy terminál-kapcsolaton keresztül kommunikál a mail-szerverrel (nem közvetlenül üt be minden egyes parancsot a billentyüzetröl) úgy ezek a standard, az SMTP protokoll által szintén definiált számok jóval könnyebben és biztosabban azonosíthatók, mint az után következö szöveges információ. (Ez utóbbi a közvetlen, terminál-kommunikáció során hasznos, hiszen így a levet küldö felhasználónak nem kell a különbözö nyugtázó- és hibakódokat megjegyeznie, az esetleges kliens-program pedig úgy sem veszi figyelembe a sort nyitó szám után szereplö karaktereket.) Ez a kettös, szám + szöveges információ típusú kommunikáció mindegyik hagyományos szabvány Internet alkalmazási-protokollra jellemzö.
A fentiekben többször említettem RFCxxxx jelzéssel ellátott dokumentumokat. Nos, ezek nem mások, mint a már említett, maga az Internet müködését felügyelö ill. az azon használt standard protokollok és formátumok kidolgozását és koordinálását végzö Network Working Group által kibocsájtott, folyamatos sorszámmal ellátott tervezetek, javaslatok és szabványok.
Az Internet III.
Az elözö részekben megismerkedtünk az adatcsere lebonyolításának elemi lépéseivel, valamint az alkalmazási szintü protokollok müködésével. Most azonban nézzük, hogyan is tartják nyilván az információk elhelyezkedését a hálózaton.
A domain-rendszer
Avval már tisztában vagyunk, hogy hogyan tud az alkalmazás a Hálózaton keresztül információt eljuttatni az egyik pontból a másikba. De vajon hogyan határozza meg az alkalmazás a célállomás azonosítóját, IP-címét, amikor mi, a felhasználók általában a célállomás kilétére vonatkozóan csak szöveges információkat, ún. URL-eket (Universal Resource Locator - Univerzális Eröforrás Helymeghatározó) adunk meg? (Az igazsághoz hozzátartozik azért, hogy az URL jóval több információt tartalmazhat mint a gazdagép azonosítására szolgáló szöveges kód, de erröl majd a késöbbiekben...)
Az ember alapvetöen könnyebben memorizál jelentéstartalommal is bíró szöveges információkat, mint egyszerü számsorokat, még akkor is ha azok jóval kevesebb kódból (karakterböl) állnak. E felismerés eredményeként az Internet tervezöi olyan adatbázisokat kezdtek el kialakítani, amelyek a használatban lévö IP-címekhez és szolgáltatásokhoz szöveges információkat rendeltek, illetve a tárolt címek visszakeresését tették lehetövé ez utóbbiakon keresztül. A kezdeti idökben ilyen adatbázis akár mindegyik, a hálózatba kötött gépen lehetett, amely akár csak azon gépek címeit tartalmazhatta, amelyekkel az illetö munkaállomás szoros kapcsolatban állt. A hálózat méretének növekedésével azonban annyira megnött e adatbázisok mérete, valamint annyira gyorsan váltak elavulttá a bennük tárolt információk, hogy e adatok nyilvántartását késöbb néhány speciális, kiválasztott szerverre bízták, amelyektöl aztán bármelyik gép lekérdezhette a kérdéses címeket. Ezeket a gépeket Domain Name Server-eknek, az általuk nyújtott szolgáltatásokat pedig Domain Name Services-nek hívják (ez utóbbi valójában sokkal több szolgáltatást takar, mint az említett egyszerü URL®IP cím-fordítás, de mi egyelöre csak ezzel foglalkozunk). E gépek egymással is kommunikáló, folyamatos adat-cserét folyató, jól szervezett rendszerek, melyek segítségével a legfrissebb információk "maguktól" is eljutnak a legtávolabbi pontokig is függetlenül annak eredeti keletkezési helyétöl.
A domain-rendszer létrehozásának több elönye is volt. A nyilvánvaló észszerüségi megfontolásokon túl e megoldás egy általános elnevezési séma kialakításával (pl. www.cégnév.com) a korábban esetlegesen nem ismert eröforrásokat is könnyen elérhetövé tette, ráadásul függetlenítette azokat (mármint az elnevezéséket) a referált gépek a hálózat topológiáján belüli elhelyezkedésétöl. Ugyanakkor lehetövé tette, pl. a kérdéses csomópontok geológia elhelyezkedésének megállapítását is megfelelö kiegészítö információk eltárolásával. Ráadásul a hálózati csomópontokat azonosító szöveges információk, az ún. domain-nevek kezelését is központosította, ezáltal elkerülhetövé téve az esetlegesen önkényesen választott, véletlenül azonos nevekböl származó konfliktusokat, valamint lehetövé tette a kapcsolódó adatok a mindenkori lehetöségekhez képesti frissességének megörzését. Természetesen ez a központosítás nem egyetlen gép totális kontrollját jelentette az összes többi felett - hiszen ez elöbb-utóbb túlterhelési problémákhoz vezetett volna -, hanem inkább a nagyteljesítményü gépek bázis-jellegét a topológiában lejjebb elhelyezkedö, általában kisebb kapacitású DNS-szerverek számára, amelyek azonban ugyanúgy keletkeztethettek újabb, lokálisan tárolt, a topológiában lejjebb elhelyezkedö gépekre vonatkozó információt a rendszer számára, mint nagyobb teljesítményü társaik.
Mint azt mindannyian tudjuk a DNS-ek egy-két (legtöbb esetben három) pontokkal elválaszott szóból álló kódsorozatok. Egy ilyen tipikus azonosító lehet például a PMMFK.JPTE.HU, a WWW.MICROSOFT.COM vagy a WWW.GNU.ORG. Bár az URL-ek domain-nevei igazából tetszöleges számú pontokkal elválasztott szóból állhatnak, a legtöbb esetben az egyszerüség és a szabványosítás kedvéért ezeket három tagból rakják össze. A domain-nevek szoros hierarchiát alkotnak, amelyek alapján mindenkor megállapítható, hogy mely DNS-szerver tárolja az elérni kívánt (cím-)információt.
A legmagasabb szintet a domain-nevek tulajdonosainak földrajzi elhelyezkedése, valamint tevékenységi és müködési jellegéböl adódó besorolás adja. Ennek megfelelöen pl. minden magyarországi domain-név .HU-ra, minden holland .NL-re és minden német szerver URL-je .DE-re végzödik. Az USA-ban kiosztott domain-nevek ilyen szempontból speciális kategóriát alkotnak, mert ezeket müködési profiljuk és jellegük alapján is megkülönböztetik. Ilyen azonosítók pl a. .COM (Commerical) - kereskedelmi, .EDU (Education) Oktatás és .ORG (Organization) egyéb, általában non-profit jellegü szervezetek, alapítványok, stb.
A következö szintet az intézmények nevei valamint az egyéb önkényes módon választott azonosítók szolgáltatják, amelyek azonban csak a fö-domain-en belül kell, hogy egyediek legyenek (pl. a WWW.HP.COM és a WWW.HP.HU egy teljesen más szervert is jelenthet - és általában jelent is - függetlenül attól, hogy ugyanannak a cégnek az üzemeltetésében állnak-e vagy sem).
Ennél lejjeb elhelyezkedö struktúrálási szintek is kialakíthatók, amelyeket azonban csak nagyon kevés esetben használnak ki.
Amikor browser-ünknek megadjuk mondjuk a WWW.MICROSOFT.COM címet, akkor az részeire bontja azt és elkezdi keresni az azonosítót a beállított - vagy pl. PPP esetén az ISP-töl (Internet Service Provider - Internet-Szolgáltató) automatikusan megkapott - DNS-szerveren. Ennek során általában eljut a legmagasabb szintet kezelö DNS-szerverig, amely megmondja neki, hogy annak a DNS-szervernek a címét amelyik a MICROSOFT.COM-ra végzödö címeket tartja nyilván. Ettöl a szervertöl aztán megkapja a WWW.MICROSOFT.COM domain-name-hez rendelt IP-címet, amelynek felhasználásával már kapcsolatot kezdeményezhet a szerver felé. Ez persze a kiindulási DNS-szerver beállításától függöen teljesen automatikusan is megtörténhet, mert az egyrészt bizonyos - az eredeti DNS-szerver által meghatározott - ideig nyilvántartja a leggyakrabban elért címeket (cache-eli azokat), másrészt amikor megkérdezzük töle a WWW.MICROSOFT.COM címet, akkor a helyett hogy átirányítana minket a legmagasabb szintü DNS-szerverig akár saját maga is elvégezheti a keresést és visszaadhatja nekünk az kérdéses IP-címet, mintha már eleve tudta volna azt.
E hierarchikus felépítés lehetövé teszi az adatok áttekinthetö, struktúrált tárolását és karbantartását, valamint a topológiában egyel lejjebb elhelyezkedö szint kezelését mindig kihelyezi a megfelelö szervezetnek. Így pl. amennyiben mi regisztráltatva lettünk mint XYZ.HU, abban az esetben egy, a saját, XYZ.HU domain-név alatt elérhetö gépünkön futó DNS-szerver szolgáltatással akár tovább is bonthatjuk azt, és újabb a struktúrában lejjebb elhelyezkedö szinteket is kialakíthatunk (pl. TRADE.XYZ.HU, és karbantarthatunk a fentebb elhelyezkedö szintek bevonása nélkül.
Fontos megjegyezni, hogy a domain name-ek által kialakított struktúra teljesen független a hálózat fizikai topológiájából, vagy a szervezet felépítéséböl adódó struktúrától. Ennek megfelelöen akár több domain-név is jelentheti ugyanazt az IP-címet, valamint látszólag bizonyos szintig azonosan eredeztetett domain-nevek (pl. WWW.ABC.HU és FTP.ABC.HU) is jelölhetnek valójában teljesen más fizikai helyen - és ennek megfelelöen általában teljesen más hálózati szegmensben - fellelhetö gépeket is.
Ennek megfelelöen lehetöség van ún. alias-ok kialakítására is, melyek valójában nem igazi IP-címeket tartalmazó referenciák, hanem csak "átirányítják" a kérést egy másik domain-névre, amely - lévén esetlegesen szintén egy alias - vagy továbbhivatkozik egy következö névre, vagy egy tényleges IP-címet tartalmaz magában. (Pl. így lehetséges, hogy a www.msn.com ugyanarra címre visz minket, mint a home.microsoft.com - az elöbbi egyszerüen átirányít minket az utóbbira.)
Az Internet IV.
Miután áttekintettük az Internet alapvetö müködési elveit ideje megismerkednünk a leggyakrabban alkalmazott Internet alkalmazási-protokollok müködésével és használatával.
Az Internet klasszikus alkalmazásai I.
Az FTP (protokoll)
Az FTP (File Transfer Protocol - Fájl Átviteli Protokoll) az egyik legrégebbi Internet-protokollok egyike - legelsö változatát még 1971-ben dolgozták ki. A protokoll feladata a számítógépek közti fájl-csere biztosítása: a különbözö platformok fájl-rendszereinek eltéréseit elrejtve, az állományok ellenörzött és biztos átvitele az Internetre kapcsolt bármely két egység között. A protokoll eredményesen használható mind interaktív, mind program által vezérelt automatikus üzemmód esetén. Bár megjelenése óta hasonló feladatok ellátására számos új protokollt is kidolgoztak, kiforrottságának és egyszerüségének köszönhetöen még mindig az egyik leggyakrabban használt Internet-protokollok közé tartozik.
Az FTP a fájlok átvitele során az eddig megismertektöl alapvetöen eltérö, azonban hatásfok és mechanizmus szempontjából indokolt adatátviteli modellt alkalmaz. Az FTP kliens a kapcsolat kezdeményezése során a már megismert módon hozza létre az ún. vezérlö-csatornát (control channel/control connection). A vezérlö-kapcsolat felépülése után a felhasználó különbözö, alapvetöen szöveges parancsokat adhat ki a távoli számítógép számára, amelyeket az értelmez és végrehajt. Ebben az üzemmódban minden adatcserét a felhasználó (kliens) kezdeményez, amelyre a szerver a parancsnak megfelelö üzenettel vagy hibakóddal válaszol. (Természetesen ezekre az üzenetekre is jellemzö, a már elözö részben is említett tulajdonság, ti. hogy a válaszkód egy, programok által is könnyen azonosítható szabványosított szám-kódból, valamint a felhasználók által is könnyen értelmezhetö szöveges információ összefüzéséböl áll, ezáltal egyszerüvé téve mind a közvetlen, mind a célprogram közbeiktatásával lefolytatott kommunikációt.)
Fájl-átvitel (küldés v. fogadás) kezdeményezése során azonban a parancs hatására a szerver egy második ún. adat-csatornát (data channel) nyit a kliens-számítógép felé, amelyen aztán az adatcsere bonyolítása történik. E csatorna - a vezérlö-kapcsolatban alkalmazottól eltéröen - szigorúan csak bináris adatok átvitelére alkalmazható - az átvitelt és a kapcsolat további részeit befolyásoló parancsok továbbra is a vezérlö-kapcsolaton keresztül adhatók/adandók ki. Az átvitel befejeztével a szerver automatikusan lezárja (bontja) az adat-csatornát. Ez az architektúra több szempontból is elönyös: egyrészt elméletileg egyetlen kontroll-csatorna felhasználásával is lehetöség nyílik több, szimultán adatátvitel kezdeményezésére (akár feltöltés és letöltése egyszerre is). Másrészt, mivel nem keveri a kis mennyiségü szöveges parancsok és az általában jóval nagyobb mennyiségú bináris adattömegek átvitelét, ezért a rendelkezésre álló sávszélesség jobb kihasználása céljából elképzelhetö, hogy a kontroll csatornán keresztüli kommunikáció egy viszonylag lassú, de ez által általában olcsóbb médium segítségével, míg az adatátviteli csatorna egy jóval gyorsabb, de így költségesebb - azonban szigorúan csak a tényleges adatátvitel idejére igénybe vett - hálózati közegen keresztül valósul meg. Ez utóbbi lehetöségböl egyenesen következhet a harmadik elönyös tulajdonság is, mely szerint adatátvitel kezdeményezhetö két olyan állomás között is, melyek közül egyik sem lokális (magyarul egy harmadik gépröl felépítünk egy-egy kontroll kapcsolatot mindkét géphez, ahol az egyiket utasítjuk az adatok küldésére, míg a másikat a fogadásra - ezek után a két gép automatikusan felépíti az adatkapcsolatot egymás közt és elvégzik a fájl(ok) átvitelét).
A kommunikáció befejezését a kliens-oldal kezdeményezi, de valójában a szerver hajtja végre.
Az FTP parancsokat a könnyebb áttekinthetöség érdekében érdemes funkciójuk alapján csoportokba sorolnunk.
Az elsö csoportot az adat-reprezentációs parancsok alkotják, melyeknek a különbözö platformokon keletkezett/platformokra szánt információk értelmezését és továbbításának módját határozzák meg. Ide tartoznak a TYPE, STRU(CTURE) ill. MODE parancsok.
A TYPE paranccsal az adatátvitel során a bájtok kódolásának módját határozhatjuk meg, azaz azt, hogy az eredeti gépen tárolt adatfolyamot a továbbítás (küldése) elött hogyan alakítsa át a szerver, hogy az a kliens által értelmezhetö formára kerüljen. A kódolási eljárást a parancs paramétereként megadott kulcsszó határozza meg, mely ASCII, EBCDIC, IMAGE ill. LOCAL. Az alapértelmezett formátum itt általában az ASCII, ami az eredeti fájlban található szöveg - esetlegesen platform-specifikus - karaktereit standard ASCII kódokra cseréli. E formátum azonban csak szöveges fájlok átvitelére használható, mert a bináris állományok átvitele esetén is "minden szívfájdalom nélkül" lecseréli a megfelelö kódokat ez által a szóban forgó programot tökéletesen használhatatlanná téve. Így általában tömörített fájlok, vagy bináris futtatható állományok átvitele elött érdemes egy "TYPE IMAGE" v. "TYPE BINARY" paranccsal indítani, hogy biztosan egy-az-egyben jöjjön át minden letöltött fájl.
Ugyancsak az adatok megjelenési formáját határozza meg a STRU(CTURE) parancs is, amellyel az átviendö adathalmaz belsö szerkezetét határozhatjuk meg. Alapértelmezett értéke általában a fájl-struktúra, azaz amikor az adathalmaz (fájl) egyetlen komplett, nem megbontható egységet alkot. Bár e utasítás segítségével akár lapokból álló, ill. komplett rekord-szerkezeteket is definiálhatunk az adathalmazra gyakorlati jelentösége PC-s környezetben elég kicsi, így nem is térnék ki taglalására.
A harmadik említett parancs, a MODE, segítségével az adatfolyamban elhelyezendö információkat határozhatjuk meg. Alapértelmezett esetben az átvitel ún. STREAM módban folyik, ami a nyers adatok folyamatos bitfolyamként történö továbbítását jelenti. Ez a mód a leggyorsabb átviteli módot nyújtja - hiszen nem csatol kiegészítö információkat az adathalmazhoz - de ugyanakkor nem nyújt lehetöséget pl. a megszakadt átviteli folyamat folytatására egy késöbbi idöpontban. Ilyen irányú igény esetén érdemes a BLOCK átviteli módot aktiválni, ami a teljes adathalmazt diszkrét blokkokra bontva - és azokhoz kiegészítö információkat csatolva - küldi el a célállomás felé. Mivel ez az átviteli mód minden egyes blokkhoz mellékeli annak adathalmazon belüli pontos pozícióját is, így egy esetlegesen megszakadt kapcsolat után a kliens könnyen újrakérheti a hiányzó részeket tartalmazó blokkokat. A COMPRESSED mód a biztonság mellett adattovábbítás gyorsaságát helyezi elötérbe, hiszen az adatok tömörített formában, a BLOCK módhoz hasonló kiegészítö információkkal "megtüzdelt" módon történö átvitelét teszi lehetövé. Alacsony tömörítési rátájának azonban elsösorban csak rendkívül lassú átviteli közegek esetén van jelentösége és az alkalmazott egyszerü algoritmus (RLE) miatt általában csak szöveges információ hatékony tömörítését teszi lehetövé.
Az FTP parancsok legnagyobb csoportját a közvetlen adat-transzferre utasító ill. az azokhoz történö hozzáférést szabályozó/lehetövé tevö parancsok alkotják. Minden FTP kapcsolat megnyitásakor elöször be kell lépnünk (login) a távoli gépen, azaz azonosítanunk kell magukat. Erre a USER (NAME) parancs használatával nyílik lehetöségünk. A felhasználó-név megadása után általában még egy ahhoz kapcsolódó jelszót is meg kell adnunk, amit a PASS(WORD) parancs kiadásával tehetünk meg. Érdemes megjegyeznünk, hogy a legtöbb publikus FTP-szerverre az "anonymous" felhasználónév és a saját e-mail címünk, mint jelszó megadásával léphetünk be. Ez utóbbi általában csak a felhasználó egyedi azonosítását teszi lehetövé (hiszen maga a user-név ez esetben nem egyedi), de gyakorlatilag bármilyen e-mail címre hasonlító szöveges információt elfogad, hiszen igazából nem állhat módjában az ellenörizni. Ez persze nem jelenti azt, hogy szabadon garázdálkodhatunk a rendszeren belül, hiszen saját, egyedi IP címünk továbbra is ott "csücsül" minden elküldött csomagunk elején, ezáltal lehetövé téve azonosításunk.
A sikeres belépés után kedvünkre tallózhatunk a jogosultságainknak megfelelö könyvtárakban és szintén ez utóbbitól függ, hogy mely állományokat tölthetjük le (download), ill. hogy egyáltalán tölthetünk -e fel (upload) a szerverre bármilyen saját információt. Érdemes megjegyezni, hogy a navigáció során a UNIX rendszerek szintaxisa a mérvadó, azaz például az elérési utakban a DOS-ban megszokott visszaperjel (\) karakter helyett itt a sima perjel (/) használandó, valamint az esetleges kapcsolókat nem perjellel, hanem mínusz-jellel (-) kell prefixálni. A navigáció során könyvtárat CD parancs segítségével válthatunk. Amennyiben a prompt nem jelzi ki, úgy aktuális könyvtárat a PWD parancs beírása után tudhatjuk meg. Az egy szinttel feljebb elhelyezkedö szülö-könyvtárba történö váltáshoz mind a CDUP, mind a "CD .." parancs használható. Az aktuális könyvtár tartalmát az LIST (LS) ill. esetlegesen a DIR parancs segítségével listázhatjuk ki.
Amennyiben az átvitel során a kontroll-kapcsolattól eltérö címmel szeretnénk felépíttetni az adat-csatornát, úgy annak IP-címét a PORT parancsnak kell átadnunk. Ez esetben a mások távoli gépet a PASSIVE (PASV) parancs segítségével kell utasítanunk, hogy készüljön fel az érkezö fájl fogadására.
A fájlok a szerver gépröl a kliensre történö letöltése a RETRIEVE (RETR) parancs kiadásával lehetséges. Ugyanezt a folyamatot a másik irányba (azaz a feltöltést) a STORE (STOR) parancs segítségével tehetjük meg. Mindkét parancs elsö paramétereként a le- ill. feltöltendö távoli ill. lokális fájl nevét kell megadnunk, míg második paraméterként opcionálisan egy, az eredetitöl eltérö fájl nevet is megadhatunk - az adatok ilyen néven kerülnek majd tárolásra a kliens ill. szerver oldalon. Amennyiben véletlenül sem szeretnénk valamilyen állományt felülírni a feltöltés során a szerveren - vagy egyszerüen csak lényegtelen a feltöltött fájl neve - úgy a STORE UNIQUE (STOU) parancsot érdemes használnunk, ami garantáltan egyedi néven fogja létrehozni a fájlt a célkönyvtárban. Ha pedig éppen az lenne a célunk, hogy egy, a szerveren már létezö állományhoz füzzünk hozzá plusz adatokat, úgy azt az APPEND (APPE) parancs kiadásával tehetjük meg.
A fent felsoroltakon kívül még számos parancs létezik elsösorban a könyvtár-szerkezet manipulálására (MKD(IR), RMD(IR)), a fájlok átnevezésére (RENAME FROM és. RENAME TO) ill. törlésére (DELETE), valamint egyéb kiegészítö információs funkciók ellátására (SYSTEM, STATUS, stb.), de ezekre kis gyakorlati jelentöségük miatt jelen cikkben nem térnék ki.
Amennyiben szeretnénk látni a használható parancsok listáját, vagy szeretnénk bövebb információt kapni egy-egy parancs paramétereiröl és használatáról, úgy a HELP parancs lehet segítségünkre.
A kapcsolat lezárása és a rendszerböl történö kilépésre a QUIT ill. BYE parancsok használhatók.
Az Internet V.
Az Internet klasszikus alkalmazásai II.
A WWW
Az Internet mai szerepe a világban, kiterjedése és mérete, valamint robbanásszerü terjedése legnagyobb mértékben egyetlen protokollnak, nevezetesen a HTTP-nek köszönhetö - ez az a protokoll amitöl az Internetböl, Világháló, azaz Web lesz.
A WWW (World Wide Web - Világméretü Hálózat) alapjait az 1990-es évben Tim Berners-Lee, a CERN (az Európai Nagyenergiájú Részecskék Fizikai Kutatólaboratóriuma) egyik munkatársa fektette le. Bár ötleteit elsösorban a már létezö Gopher protokoll "ihlette", sikerült annak számos hátulütöjét és viszonylagos zártságát kiküszöbölve egy olyan rendszert kialakítania, amely alapjaiban napjainkig nem szorult módosításra. Az általa megálmodott világháló a már említett Gopher rendszerezö szerepén kívül képes volt szöveges információ, képek, és ami legfontosabb: ezekbe ágyazott hyperlinkek segítségével összekapcsolt elemek hitetetlen bonyolult rendszerét kialakítani. Ráadásul a protokollok kialakítása is olyan módon történt, hogy ne zárják ki más média-típusok (pl. mozgókép, hang, stb.) továbbítását sem.
Maga a hypertext és hyperlink kifejezések nem a Web sajátjai (már a 1970-es években is müködtek ilyen elveken alapuló rendszerek), de azok ilyen széles mértékü megosztását és összekapcsolását csak is a Web tette lehetövé.
A teljesen WWW alapvetöen három jól elkülöníthetö típusú komponensböl épül fel: a HTML-nyelven íródott Web-oldalak tartalmazzák magukat az információkat illetve abba beágyazva a más információ-forrásokra mutató hyperlinkeket. Ezeket a web-oldalakat az ún. Web-szerverek teszik elérhetövé az Internetre kapcsolódó más gépek számára a HTTP protokoll felhasználásával. Az ügyfél programok vagy más néven Web-browserek feladata ezen oldalak lekérése a szerverektöl és a bennük található információ formázott megjelenítése a felhasználó számára.
A HTML (HyperText Markup Language - hypertext jelölö-nyelv) az SGML (Standard Generalized Markup Language) egy specifikusan a Web számára átalakított módozata. A nyelv lehetöséget nyújt a normál információs szövegben bizonyos jelölö blokkok, ún. tag-ek elhelyezésére, melyek információkat és utasításokat tartalmaznak a browserek számára a dokumentumok tartalmával, megjelenítésével és viselkedésével kapcsolatban.
Mivel így az információk egy új, az addig létezö formátumoktól teljesen eltérö módon kerültek kódolásra, ezért azok megjelenítése is értelemszerüen csak a megfelelö dekódoló, egy browser program segítségével volt lehetséges. Nyilvánvalóan nem terjedt volna el fantasztikus ütemben a Web, amennyiben az ilyen szoftverekért hasonlóan magas árat kértek volna mint az egyéb kereskedelmi programokért. Szerencsére ez a probléma nem vethetett gátat a fejlödésnek minekután az Illionis-i Egyetemen müködö NCSA (National Center for Supercomputing Applications) kibocsátotta az elsö ingyenes browser-t, az NCSA Mosaic-ot. A programot Marc Andreeseen tervezte és diákok egy csapata valamint az egyetem néhány munkatársának közremüködésével fejlesztették ki. A Mosaic úgy terjedt az Interneten, mint a futótüz: a megjelenéstöl számított egy éven belül már kb. 2 millióan használták világszerte. Hamarosan mindenki használta a Világhálót és mindenki saját web-oldalának kialakításán fáradozott - a Web sokkal gyorsabban terjedt mint bármely más újítás a számítástechnikai történelmében. Míg 1993 közepén mindössze kb. 130 web-site létezett, addig az év végére már közel 600, egy évvel késöbb már majdnem 3000 és 1996 elején már több mint 90,000 site volt elérhetö. Napjainkban e számot mintegy ? millióra becsülik.
Mivel nem csak a Mosaic futtatható állományai, de maga a program forráskódja is szabadon terjeszthetö volt, ezért egyre több browser program jelent meg. Ezek közül a legsikeresebb - a Microsoft Internet Explorerjének megjelenéséig - a mindenki által ismert Netscape Navigator lett. (Mellesleg a Netscape-et pont ugyanaz a Marc Andreessen alapította - Jim Clarkkal, a Silicon Graphics egykori munkatársával közösen -, aki magának a Mosaic-nak a fejlesztését is koordinálta.)
A felhasználók nyomására a nagy online szolgáltatók is kénytelenek voltak - addig általában egyedi megoldásokkal müködö - szolgáltatási kínálatukat átalakítani és a web-központúság felé eltolni. A webre hamaros minden éjszaka szörfözök milliói léptek fel, hogy újabb és újabb információk után kutassanak a Háló végtelen útjain.
Az HTTP (protokoll)
A Web kliens-szerver architektúrát alkalmaz az információk megosztására és terjesztésére. A rendszer müködése során a felhasználó gépén futtatott kliens program - a web-browser - kérést intéz az Internetre rákapcsolt web-szerverhez, ami az üzenetet értelmezi és a kért dokumentumot ill. kiegészítö információkat küld vissza a kliens felé. A megkapott fájlt aztán értelmezi a browser és annak tartalmától függöen megjeleníti, lemezre menti vagy éppenséggel - pl. Java kód esetén - elkezdi futtatni azt a felhasználó gépén. A két gép között az információ-csere a HTTP protokoll segítségével zajlik.
Az HyperText Transfer Protocol (Hipertext Átviteli Protokoll) kialakítása során elsödleges szempont volt az egyszerüség és gyorsaság, amik elengedhetetlen feltételei egy jól müködö oszott, hipermédia alapú információs rendszernek. A HTTP egy objektum-orientált, állapot nélküli általános protokoll, ami azonban jóval több feladat ellátására is képes lehet, mint web-oldalak továbbítása.
Az, hogy a protokoll állapot nélküli azt jelenti, hogy a teljes kommunikáció folyamata jól behatárolható, egyedi kérések sorozatából áll melyek mindegyike során a kliensnek minden szükséges információt újból el kell küldenie a szerver felé. Bár e megközelítés ineffektívnek bizonyul egy viszonylag állandó kapcsolat - pl. helyi hálózat szervere és a munkaállomások - esetén, egyértelmüen sokkal hatékonyabb az olyan hipermédia rendszerek, mint pl. a web esetén is, ahol alapvetöen alacsony (<50%) az esélye annak, hogy a kliens két egymás utáni kérése ugyanarra a szerverre fut be, hisz a hiperlinkek segítségével a felhasználó - teljesen észrevétlenül - keresztül-kasul vándorol az hálózaton. Az egy-egy oldal lekérése során végrehajtásra kerülö átviteli tranzakció a következö alapvetö lépésekböl áll:
a kliens és a szerver közti kapcsolat felépítése (a HTTP általában a 80-as TCP/IP portot használja a szerver gépen, de az URL segítségével bármilyen más, tetszöleges port is megadható)
a kliens egy kérést (request) intéz a szerver felé
a szerver a kérés fogadása és az annak megfelelö feladatok elvégzése után egy választ (response) küld vissza a kliens felé
mindkét fél bontja a kapcsolatot
A kliens az összeállított kérésben információkat küld saját magáról (pl. a browser típusa és verziója), az alkalmazott formátumról (pl. az alkalmazott HTTP protokoll verzió) valamint az URL-ben a host-név utáni - a felhasználó által közvetlenül begépelt, vagy egy hiperlinkben megadott - kiegészítö paramétereket, melyek további információkat nyújthatnak a szervernek az információ típusát, jellegét illetöen vagy speciális futtatható modulok esetén végrehajtási módozatával kapcsolatban. Ezen kívül egy ún. metódust is meghatároz, azaz megmondja, hogy milyen müveletet kíván a megadott objektumon elvégezni. Az objektumokon elvégezhetö metódusok az alkalmazott információs rendszer jellegétöl függenek és a WWW esetén pl. a következö feladatok elvégzésére alkalmasak: lekérdezni, hogy egy objektum állapota megváltozott -e (azaz, hogy újra kell -e olvasnia, vagy elöveheti egy régebbi verzióját), letölteni, törölni, stb.
Ezen információkat a kliens egy, az Internel Mail-ben is alkalmazott fejléchez hasonló, alapvetöen szöveges jellegü információs blokkban kódolja és ezt küldi el a szerver felé.
A szerver a kért információs blokk elöállítása után azt egy hasonló fejléccel ellátva küldi vissza a kliensnek. A szöveges blokk elsösorban a visszaküldött objektum jellemzöit írja le: pl. kódolási formátum (sima szöveg, UUENCODE, zip, stb.), típus (szöveges információ, kép, video, hang, bináris állomány, stb.), alkalmazott nyelv, stb. A választ megkapva azután a browser ezen információk alapján tudja eldönteni, hogy mit is kell csinálnia az objektummal: megjelenítenie, lemezre menteni vagy éppenséggel lefuttatni.
Az Internet VI.
Az Internet klasszikus alkalmazásai III.
IRC
Az IRC (Internet Relay Chat) protokoll elsö változatát Jarkko Oikarinen dolgozta ki 1988-ban a Unix "Talk" programjának továbbfejlesztéseként. Eredetileg elsösorban BBS-ek számára, valós idejü szöveg-alapú telekonferenciák létrehozására szánta, azonban a protokoll szerver-kliens architektúrájának és rugalmasságának köszönhetöen sikeresen alkalmazható jóval nagyobb kiterjedésü kommunikációs hálózatokon, meglehetösen nagy felhasználószám mellett is. Bár a protokoll jelenlegi implementációi szinte kizárólag TCP/IP-ra épülve müködnek, egyéb megbízható átviteli protokollok is alkalmasak a kapcsolati réteg funkcióinak ellátására.
Az IRC-n belül a kliensek bizonyos csoportokba, ún. csatornákba (channel) szervezödnek. A csatornának küldött üzenetet minden, az adott csatornába bejelentkezett felhasználó megkapja ill. ö maga is hasonló üzeneteket küldhet a csatorna felé. A csatornát az elsö, a belépéskor a csatorna nevét használó kliens hozza létre, és a csatorna megszünik létezni amint az utolsó kliens elhagyja. (Valójában a csatorna mint fix, permanens kapcsolat vagy eröforrás soha nem is létezik - ez a megközelítés szigorúan logikai jellegü.) A csatornát létrehozó felhasználó automatikusan a csatorna operátorává (channel operator - ChanOp) válik, aki speciális jogosultságokkal bír a hagyományos kliensekkel szemben: módosíthatja a csatorna jellemzöit, meghívásos csatornák esetén meghívhat klienseket, átmenetileg eltávolíthat ill. véglegesen kizárhat bizonyos - pl. nem megfelelöen viselkedö - felhasználókat, vagy akár hasonló jogosultságokkal ruházhat fel a csatornát csak késöbb felkeresö felhasználókat.
Alapvetöen két fajta csatorna létezik: a nyílt, az összes kapcsolódó szerver által ismert, mindenki által szabadon elérhetö csatornák, ill. a zárt, általában meghívásos jelleggel müködö csatornák, melyet kizárólag csak azok a felhasználók érhetnek el, amelyek a csatornát tartalmazó szerver közvetlen kliensei.
Magukat a csatornákat egy max. 200 karakter hosszú sztring, az ún. csatorna-név azonosítja. A nyílt csatornák nevét egy '#', míg a zártakét egy '&' jel elözi meg. A csatornákat általában a rajtuk keresztül folytatni kívánt beszélgetések témájáról vagy annak egy-egy kulcsszaváról kapják a nevüket: ennek megfelelöen pl. a #biking csatornán a kerékpározás megszállottai, míg a #magyar csatornán a magyar nyelvü felhasználók csevegnek.
Egy új csatorna létrehozásához vagy egy már meglévöhöz történö kapcsolódáshoz a felhasználónak a JOIN parancs segítségével be kell lépnie az adott csatornába. Amennyiben a szóban forgó csatorna eddig nem létezett, úgy az létrehozásra kerül és a felhasználó automatikusan a csatorna operátorává válik (nevét a felhasználók listájában egy '@' elözi meg). Ha a csatorna már létezett, abban az esetben a belépés sikere a csatorna jellemzöitöl függ: pl. meghívásos csatornákra kizárólag az után lehet belépni, hogy meg lettünk hívva, ill. jelszóval védett channelre nyilvánvalóan csak a jelszó ismeretével tudunk bejelentkezni. Bár elméletileg egy kliens tetszölegesen sok csatorna tagja is lehet ugyanabban az idöben, de humán felhasználó esetén nyilvánvaló okokból ennek sok gyakorlati jelentösége nincs.
Az IRC-ben alapvetöen két fajta egységet különböztetnek meg: a kliens és a szerver egységeket. Az IRC kommunikációs lánc gerincét a szerverek szigorúan lefelé bomló, fa struktúrába szervezett hálózata alkotja. A szerverekhez kapcsolódnak a kliensek, amelyeket egyedi azonosítójuk, az ún. nickname (becenév) alapján lehet megkülönböztetni.
Ha az IRC gerinc bármilyen (pl. fizikai) okból "kettétörik", azaz bizonyos szerverek közti kapcsolat megszakad, úgy mindkét oldalon két külön csatorna keletkezik, melyeknek nyilvánvalóan csak a megfelelö hálózati szegmenshez kapcsolódó kliensek lesznek tagjai. Amennyiben a kapcsolat a késöbbiekben helyreáll, úgy a két csatorna újból egyesítésre kerül. (Ez igazából logikusan következik a kapcsolat kizárólag logikai jellegéböl adódóan.)
A kliensek és a szerverek üzeneteken keresztül kommunikálnak egymással. Minden egyes üzenet három részböl áll: egy prefixböl (opcionális, az üzenet keletkezési helyét határozza meg), magából a parancsból ill. a hozzá kapcsolódó opcionális paraméterekböl, melyek mindegyike szóközzel van elválasztva egymástól. Az üzenetet minden esetben egy CR-LF karakter-páros zárja. Az egyes üzeneteket követheti válasz (is), ami maga is egy üzenet - ennek (ti. a válasz küldésének) bekövetkezése elsösorban a parancs jellegétöl függ (pl. az érvényes IRC parancsokat általában a szerver egy válasz-üzenettel nyugtázza). A szerver által küldött válasz-üzenetek a szöveges információk elött - az egyszerübb és egyértelmübb gépi feldolgozás céljából - egy három-jegyü kódot tartalmaznak, melyek mind nyugtázó, mind hibakódokat magukban foglalnak.
A kliensek számára érkezö üzenetek alapvetöen négy csoportba sorolhatók. Az információs üzenetek (informational messages) az IRC valamint a csatorna változásairól tájékoztatják a felhasználót: segítségükkel szerzünk információt az új kliensek belépéséröl, mások kilépéséröl, a nickname-ek valamint a csatorna jellemzöinek megváltozásáról. A nyilvános üzeneteket (public messages) minden, az adott csatornába bejelentkezett kliens láthatja - minden, egyéb megjelölés nélkül az adott csatornára küldött üzenet nyilvános. Ezzel szemben a privát üzeneteket (private messages) - bár ezek szintén végigfutnak az IRC hálózaton - kizárólag csak a címzett(ek) olvashatják. Az üzenetek negyedik csoportját alkotó értesítések (notices) elsösorban automatikus rendszerek által küldött válaszok.
A mIRC
Ahhoz, hogy az IRC-ben részt tudjunk venni,
szükségünk lesz egy IRC-kliens programra. Ezek közül Windows alatt a
legnépszerübb a mIRC, ami elsösorban kezdök számára nyújt nagy segítséget
azzal, hogy a legfontosabb IRC funkciókat menükön és dialógusokon keresztül
bocsátja a felhasználó rendelkezésére.
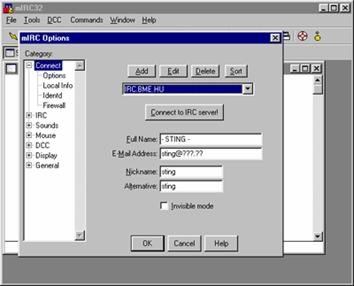
A mIRC indítása utáni elsö lépésként meg kell adnunk annak az IRC szervernek a nevét amelyre kapcsolódni kívánunk. Magyarországon a három legnépszerübb szerverek a következök: irc.bme.hu, irc.sch.bme.hu, darmol.elte.hu. Ezek közül bármelyikre felléphetünk, hiszen ezek egymással - és persze az IRC hálózat többi szerverével - szoros kapcsolatban állnak, így a nyilvános csatornákat mindegyikükön megtaláljuk. Elméletileg lehetöségünk van (speciális esetekben - pl. zárt csatornák - szükséges is) külföldi szerverekre is fellépni, de nyilvános, bármely IRC szerverröl elérhetö csatornák esetén inkább magyar szervert válasszunk. Így egyrészt kevésbé terheljük a hálózatot és gyorsabban érkeznek meg az üzenetek hozzánk, másrészt a nyilvános célú szerverek nagy része ellenörzi, hogy milyen földrajzi helyröl csatlakozunk rá, és ha úgy ítéli meg, hogy nem az "ö körzetébe" tartozunk akkor egyszerüen nem enged belépni.
Amennyiben elöször indítottuk a mIRC-et úgy még néhány adatot meg kell adnunk, hogy rá tudjunk kapcsolódni a kiválasztott szerverre. A kitöltendö mezök a következök:
real name (valós név) ide a nevünket írjuk be (persze nem kell feltétlenül az igazit)
e-mail - amennyiben nincs e-mail címünk, úgy "n/a"-t írjunk ide
nickname - a használni kívánt becenév
alternate - amennyiben a feni becenév már használatban van, úgy ezt próbálja meg használni
Olyan becenevet érdemes választani, amilyent valószínüleg senki más nem használ a hálózaton, hiszen egyéb esetben nem fogunk tudni fellépni a szerverre, vagy ha éppen nem is ütközünk másokkal - mert nem egy idöben használjuk az IRC-t - de sokan össze fognak téveszteni bennünket azonos becenevü társunkkal, aminek elég kellemetlen következményei is lehetnek. Az olyan slágerek, mint pl. "Jani", "Tomi" stb. nem valószínü, hogy be fognak jönni - e helyett érdemes inkább valami egyedi "müvésznevet" kitalálni, vagy a nevek elötti, utáni speciális karakterekkel (pl. [], _, stb.) játszadozni..
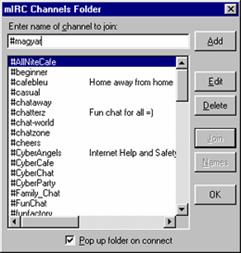
A fenti adatok megadása után máris ráléphetünk a kiválasztott szerverre. Sikeres kapcsolódás után a mIRC felhozza az általa ismert legnépszerübb csatornák listáját, amelyböl kiválaszthatjuk, hogy melyiken kívánunk csevegni. Mivel ez alapesetben egyetlen magyar csatornát sem tartalmaz, ezért mindjárt kezdjük a következö néhány csatorna felvételével:
#alpina
#erdely
#hungary
#internetto
#viccparty
A #magyar csatornára is ráfigyelhetünk, de szerintem mindenki aki rálép erre, egy idö után rá fog jönni, hogy ez nem egészen az amire feltétlen szüksége van.
Egyébként amennyiben kíváncsiak vagyunk rá, úgy a /list parancs kiadásával kilistázhatjuk az összes, az éppen kapcsolódó szerver keresztül elérhetö csatorna nevét, de készüljünk fel rá, hogy a teljes lista kiírása sok esetben egy percet is igénybe vehet.
A csatorna kiválasztása vagy nevének beírása után a mIRC egy új ablakot nyit. Minden kliens ablak három jól elkülöníthetö részböl áll. Jobb oldalt a csatornára bejelentkezett kliensek becenevei láthatóak. Alul a saját üzenet- ill. parancs-szerkesztö sorunk található, míg az ablak fennmaradó részét a magát a csatornán folyó beszélgetést tartalmazó üzenet-ablak található.
Az üzenet ablakban megjelenö elsö sor általában a belépésünkröl tudósító: "*** [nickname] has joined channel #channel" üzenet, amelyet az éppen aktuális témáról (topic) tudosító üzenet, majd a többi kliens által küldött, magát a beszélgetést jelentö üzenetek követnek. Amennyiben a csatornának még egyetlen tagja sem volt - mi hoztuk létre - úgy automatikusan mi válunk a csatorna operátoráva, amit becenevünk elötti "@" is jelölni fog. Ha már létezö csatornára lépünk be, úgy a belépés után illik a többieket köszönteni: írjuk be az üzenet-sorba, hogy "sziasztok!", nyomjunk egy Enter-t és üzenetünk máris megjelenik a saját és az összes többi - a csatornára éppen bejelentkezett - felhasználó képernyöjén. Az üdvözlésekre általában nem szokás reagálni (elég hülyén nézne ki ha minden egyes belépésre mind a 200 aktív kliens visszaválaszolna) - így ezt egyszerüen vegyük nyugtázottnak. Mielött elkezdünk mi is "beszélni" praktikus néhány üzenet-váltás kivárni - hogy egyáltalán lássuk éppen miröl beszélnek - és csak ez után bekapcsolódni a témába. Alapvetöen tartózkodjunk az eröszakos megnyilvánulásoktól és a vulgáris kifejezésektöl. Amennyiben mégsem tesszük ezt úgy elöbb-utóbb egyik vagy másik chanelop kirúg (/kick) minket a csatornáról. Bár a kitiltás ez a fajtája csak átmeneti (csak az aktuális kapcsolatot szakítja meg, így késöbb újra be tudunk jelentkezni a csatornára) de kitartó "munkával" elérhetjük, hogy meghatározott idöre permanensen vagy akár végleg kitiltsanak (/ban) minket a csatornáról.
Amennyiben a beszélgetés során valakivel esetleg "négyszemközt" szeretnénk megtárgyalni valamit úgy egyszerüen egy DCC (Direct Client Chat - Közvetlen Kliens-Csevegés) csatornát kell nyitnunk az adott felhasználó felé. Ugyancsak a DCC segítségével nyílik lehetöségünk fájlok átküldésére is, bár ettöl alapvetöen tartózkodjunk, mert elég erösen leterheli a hálózatot.
A fenti rövid kis ismertetés korántsem teljes - mindössze egy kis kiindulópontot szerettem volna nyújtani a kevésbé kísérletezö kedvü felhasználóknak az IRC-n történö barangoláshoz. Aki tud angolul annak mindenképpen érdemes átnéznie az mIRC súgóját, hiszen még nagyon sok hasznos funkcióval rendelkezik, amiröl itt egy szó sem esett. A CD-n egyébként megtalálható az IRC protokoll teljes leírása az RFC1459.HTM-ben , ill. egy Aliases.INI file is melyet a mIRC alkönyvtárunkba bemásolhatunk (az eredetit mentsük el!), és számos hasznos funkcióval gazdagodhat chatelésünk. A bemásolás (és a mIRC újraindítása) után próbáljuk ki pl. a /b1 Hello! (vagy /b1, /b2, ..., /b9) kapcsolókat, ill. nézzük meg a Tools/Aliases menüpontot a részletesebb parancsok megismerése végett
Az Internet klasszikus alkalmazásai IV.
NEWS
A NEWS rendszer - vagy ismertebb nevén a USENET - nem más, mint egy hatalmas, világméretü vitafórum. A teljes fórum jól elkülöníthetö, témájuk és ennek megfelelöen kialakított nevük alapján szoros (fa-)hierarchiába szervezett ún. hírcsoportok (newgroups) sokaságából áll. A felhasználók által a hírcsoportokba küldött üzenetek (messages) ill. cikkek (articles) a USENET szerverek világméretü hálózatába jutnak ahonnan aztán a hírcsoport többi tagja igénye szerint letöltheti azokat, majd esetleg azokra reflektálva - vagy újabb témát ill. kérdést felvetve - maga is üzeneteket küldhet a fórumon keresztül a többiek felé. A USENET maga folyamatosan változik és átalakul amint újabb és újabb hírcsoportok kerülnek létrehozásra, és az információk cseréje fórumok egyre szélesebb skáláján zajlik. Több mint 25.000 hírcsoportjával és mintegy 20 millió felhasználójával pillanatnyilag a világ legnagyobb osztott rendszerü elektronikus hirdetötáblájának tekinthetö.
Maga a USENET az Internettöl független hálózat - számos, az Internettel közvetlen kapcsolatban nem álló (pl. vállalati intranet) szerverrel rendelkezik, de természetesen a legnagyobb forgalmat azon keresztül bonyolítja.
Érdemes megemlíteni, hogy a USENET-tel párhuzamosan napjaikban is létezik az üzenet-szórásos levelezés egy másik, a hírcsoportok elödjének tekinthetö formája: az ún. levelezési listák. Bár az átlagos felhasználó számára e két rendszer müködése szinte azonosnak tünhet, jelentös eltérés mutatkozik technikai megvalósításukban, céljukban és egyéb tulajdonságaikban.
A klasszikus levelezési listák esetében a postázni kívánt cikkeket egy elöre meghatározott e-mail címre kell elküldeni, ahol is azt a mail-szerver annak fogadása után - esetleg egy lista-moderátor közbeiktatásával - továbbítja a listára feliratkozott felhasználók e-mail címeire, mindegyiküknek egy-egy példányt elküldve az eredeti levél - általában az eredeti feladóra vonatkozó fejléc- ill. a listára vonatkozó lábléc-információkkal kiegészített - másolatát. Érdemes észrevenni, hogy e módszer a részben vagy teljesen azonos hálózati úton elérhetö felhasználók esetében redundáns módon, azaz a szóban forgó hálózati szakaszon teljesen feleslegesen több, azonos példányt is továbbít, ami egy bizonyos számú listatag esetén már jelentös idöbeli eltéréshez (ez rossz esetben akár több óra is lehet) vezethet az üzenet feladása ill. fogadása között.
Ezzel szemben a USENET a rendelkezésre álló sávszélességet jóval effektívebben használja ki. Ez egyrészt annak köszönhetö, hogy a USENET-en belül az üzenetek azok olvasása elött kizárólag magukon a hír-szerveren kerülnek tárolásra, tehát letöltésükig nem foglalnak feleslegesen helyet a fogadó postaládájában. (Ennek köszönthetöen többek között nem jelentkezhet az, a levelezési listák esetében egyébként elöforduló probléma, hogy egy vagy több tag nem kap meg bizonyos üzeneteket, mert - ciklikus ürítés hiányában - a posta-ládájának fenntartott tárterület megtelt, és így a posta-ládát üzemeletetö gép "visszadobta" azt.). Másrészt az NNTP protokoll kialakítása lehetövé teszi, hogy a hír-csoportok tagjai az összes postázott üzenet közül - azok fejléce alapján - kiválaszthassák, hogy mely üzeneteket kívánják elolvasni, ezáltal is kiküszöbölve az érdektelen (egyébként valószínüleg azonnal törlésre kerülö) üzenetek felesleges továbbítását a kliens felé. (Bár ez utóbbi módszer megvalósítására elméletileg hagyományos posta-ládák - tehát levelezési-listák esetén - is lehetöség lenne, azonban mivel maga a mail-protokoll nem ilyen célra került kialakításra, így a legtöbb levelezöprogram nem nyújt lehetöséget a felhasználók számára a letöltendö üzenetek interaktív szelektálására.)
Ugyanakkor, mivel a levelezési listák létrehozásához elegendö egyetlen - akár viszonylag kis teljesítménnyel rendelkezö - az Internet-re kapcsolódó szerveren egyetlen ún. mailer-daemon futtatása, így az nélkülözi a NEWS rendszer centralizált menedzsmentjét, ami jóval dinamikusabb és szabadabban formálható kialakítást tesz lehetövé.
Még egy érdekes szempontot érdemes megemlítenünk a különbségek esetén: a disztribúció szkópját. Ahhoz, hogy egy levelezési lista üzeneteit megkapjuk fel kell iratkoznunk a listára. Ez azt jelenti, hogy egy, a listára postázott üzenetet kizárólag azok kapják meg, akik az eredeti üzenet fogadásának pillanatában a levelezési lista tagjai voltak. Ezzel szemben a USENET nyílt fórum: bárki, aki el képes érni a globális hálózat valamely szerverét lehetösége nyílik az adott szerver által "futtatott" hírcsoportokra küldött üzenetek fogadására ill. maga is azonnal képessé válik azokra üzenetek küldésére. Itt kell megjegyeznünk, hogy bár a levelezési listákhoz hasonlóan a hírcsoportokba is fel kell iratkoznunk, de ez a feliratkozás kizárólag a helyi szerveren kerül adminisztrálásra és kizárólag belsö célokra. (Ez azt jelenti, hogy az üzenet feladója a USENET-en - egy levelezési listával ellentétben - technikailag képtelen megállapítani üzenet fogadóinak listáját, hiszen az "elöfizetök" listája nincs globális szinten, centralizáltan menedzselve.) Ráadásul a USENET szerverek a postázott üzeneteket lejártukig (expire) - ált. legalább egy hétig - meg is örzik, ami elméletileg lehetövé teszi a késöbb feliratkozók számára akár korábban feladott üzenetek megtekintését is.
Általánosságban elmondható, hogy viszonylag alacsony tagszám (max. 100-150) és nem túl magas forgalom (max. 50-100 üzenet naponta) esetén hírcsoport létrehozása helyett jóval célszerübb egy egyszerü levelezési lista üzemeltetése.
A hírcsoportoknak alapvetöen két fajtája létezik: a moderált ill. a moderálatlan csoportok. Ez utóbbiak közös jellemzöje, hogy a rájuk postázott üzenetek - korlátozás nélkül - automatikusan továbbításra kerülnek a USENET világhálózat felé. Ezzel szemben a moderált csoportok mindegyike egy vagy több ún. moderátorral rendelkezik, aki(k) a csoportba érkezö üzeneteket tartalmuk és stílusok alapján megszüri(k): a tartalmi (pl. a csoport témájához nem kapcsolódó, durva kifejezéseket v. egyéb antiszociális megnyilvánulásokat tartalmazó.) vagy formai (pl. csatolt bináris állományok, az csoportban alkalmazandótól eltérö nyelv használata, stb) okból megjelentetésre alkalmatlannak tartott üzeneteket egyszerüen nem engedik tovább a hírcsoport felé.
Mint arról a korábbiakban már szó volt: a USENET hírcsoportjai témájuk alapján szoros hierarchiába vannak szervezve. Minden hírcsoportot egy pontokkal elválasztott szavakból álló név azonosít (pl. alt.comp.announce), amely egyben magában foglalja az adott hírcsoporton folyó "beszélgetések" témáját is. A hierarchia legmagasabb szintjén az elsö pontot megelözö szó adja: ez határozza meg, hogy az adott hírcsoport a USENET mely legnagyobb alcsoportjába tartozik. Ilyen globális alcsoport például az alt (alternative -egyéb kategóriába be nem sorolt), a sci (scientific - tudományos) vagy a rec (recreational - szórakozás). A legmagasabb szint aztán természetesen további alszintekre bomolhat amelyet a föcsoport nevét követö pontokkal elválasztott szavak jelölnek. A hierarchián belül a hírcsoportok száma természetesen változó, de általában valahol a hierarchia 3. és 6. szintje között helyezkednek el.
A hírcsoportokba küldött - és moderált csoportok esetén a moderátorok által elfogadott - üzenetek a USENET globális szerver-hálózatába kerülnek.
A klasszikus hír-terjesztési modellben a szerverek ún. telítéssel (flooding) terjesztik egymás között az üzeneteket, azaz a beérkezett új üzeneteket a szerver továbbítja minden vele közvetlen kapcsolatban álló szerver felé, amelyek azután azokat szintén további szerverekhez küldik el. Ez a terjesztési módszer azonban az Internet hálózati topológiájában erösen redundáns üzenettovábbításhoz vezetne, hiszen egy-egy szerver akár több százszor is megkapná ugyanazt az üzenetet, ami a rendelkezésre álló sávszélesség komoly pazarlásához vezetne.
Ezzel szemben a USENET-en alkalmazott NNTP (Network News Transfer Protocol - Hálózati Hírtovábbítási Protokoll) egy interaktív mechanizmust biztosít a szerverek közötti hírcsere lebonyolítására, amelynek segítségével minimalizálható az adatforgalom és elkerülhetö a redundáns hírküldés. Egy tipikus NNTP kapcsolat során egy új üzeneteket a hálózaton propagálni kívánó, vagy új üzenetek érkezését ellenörizni kívánó gép egy kapcsolatot kezdeményez egy másik USENET szerver felé. A kapcsolat felépítése után a kliensnek lehetösége nyílik az esetlegesen létrehozott új hírcsoportok, valamint az utolsó kapcsolat óra érkezett üzenetek lekérdezésére. Végül a szerver áltál elküldött válasz alapján a kliens kezdeményezheti a számára még ismeretlen üzenetek elküldését amelynek befejezése után a kapcsolatot lezárja. Ennek következtében ténylegesen csak azok az üzenetek kerülnek majd átvitelre a kapcsolat során amelyek még nem érkeztek már meg egy esetleges másik csatornán a klienshez.
A hírcsoportokban történö aktív részvétel elött érdemes a következö tanácsokat megfogadnunk:
Ismerkedjünk meg alaposabban a news kliens-programunkkal! Így könnyen elkerülhetjük a téves kezelésböl adódó akaratlan postázásokból ill. egyéb félreértésekböl adódó bonyodalmakat (ne feledjük, hogy leveleinket akár több millióinyian is olvashatják)
Olvassuk el a hírcsoport FAQ-jét (Frequently Asked Questions - Gyakran Ismételt Kérdések)! E dokumentumot direkt az új felhasználók által feltett leggyakrabb kérdésekböl és az azokra adott válaszokból állítják össze. Ezzel elkerülhetjük, hogy "hülyének állítsuk be magunkat" a többiek elött valamint gyorsan és "fájdalommentesen" megismerkedhetünk a hírcsoport egyedi szabályaival és szokásaival is.
Bevezetö
LASSÚÚÚ!!!! Hányszor kiáltunk fel így, bosszankodva amikor a WWW böngészönkkel egy-egy távoli szerveren kalandozunk és alig gyözzük kivárni amíg a kért oldal megjelenik a képernyönkön. Persze hogy lassú, miért is lenne gyors amikor - szerencsére - olyan sokan, egyre többen használjuk a hálózatot, de sajnos a távközlési vonalak kapacitása igen korlátos. A kedvenc WWW pedig sokat fogyaszt, egy-egy szép (vagy csúnya) színes oldal letöltése igen nagy mennyiségü adat átvitelét igényli. Hogyan lehet segíteni ezen a problémán? Hogyan lehet a "nagy fogyasztású" alkalmazásokat úgy használni hogy a hálózatot ne terheljük agyon? Természetesen kézenfekvö megoldás lenne a távközlési vonalak kapacitásának megfelelö bövítése. Csakhogy ez elsösorban pénzkérdés, mivel az ilyen vonalak ma Magyarországon hihetetlenül drágák. Másik megoldás a hatékonyság növelése, és ezzel együtt a takarékoskodás. Mivel a legnagyobb fogyasztó a WWW, a legjobb eredményt a WWW forgalom hatékonyságának javításával érhetjük el. Ennek egyik kitünö módja a WWW cache-ek alkalmazása. Világszerte elötérbe kerültek az ilyen rendszerek, még azon országokban is ahol lényegesen nagyobb sávszélességü Internet kapcsolatok szolgálják a felhasználókat. Magyarországon sincs semmi akadálya annak hogy minél többen igénybe vegyék ezt a korszerü eszközt és ezáltal még jobban használhassuk a Hálózatot.
Mi az a cache?
A "cache" fogalommal gyakran találkozunk a korszerü számítástechnikai rendszerek leírásánál. A szó eredeti jelentése "rejtekhely", és ez némileg utal a cache funkciójára is. A cache egy olyan nagyon gyors müködésü tároló, amelyben a gyakran használni kívánt adatokat átmenetileg tároljuk ("rejtjük") azért mert így azokhoz sokkal gyorsabban hozzáférhetünk mintha mindig az eredeti, lassabb elérésü forráshoz kellene nyúlnunk.
Manapság leggyakrabban a korszerü mikroprocesszor architektúrák leírásánál találkozunk a cache fogalommal. A processzor és a memória között elhelyezkedö gyorsítótárba bekerült utasítás- és adatbyte-ok hozzáférési ideje nagyságrenddel kisebb mint a normál memóriában levöké, és a hozzáférés a rendszerbuszt sem terheli. (1. ábra)
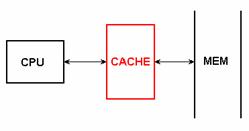
ábra - Cache a számítógép architektúrában
Nem csak a memória müködését szokták cache-el gyorsítani. Gyakran találkozunk egyéb, pl. szoftver segítségével megvalósított cache-ekkel is. Legjellemzöbb példa erre a UNIX operációs rendszer kernelének ún. buffer-cache mechanizmusa, amely az operációs rendszer diszk kezelését gyorsítja meg. (2. ábra) Szoftver cache-eket alkalmaznak többek között a TCP/IP protokollcsomaghoz tartozó ARP (Address Resolution Protocol) és a DNS (Domain Name Service) protokollokban is.
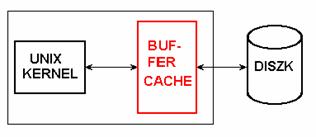
2. ábra - Cache az operációs rendszer architektúrában
A cache mechanizmus igen hatékonyan használható az Internet információs rendszerek müködésének gyorsítására és a nagy távolságú hálózati összeköttetések sávszélességével való takarékoskodásra is. Az ilyen Internet cache-ek felállítása különösen a World Wide Web rohamos elterjedésével került elötérbe. A WWW igen nagy sávszélesség igényü alkalmazás, és a forgalom cache-elésével a müködés gyorsítható, a hálózat terhelése csökkenthetö. A HTTP protokoll alkalmas arra hogy a WWW szerverek és kliensek közé ún. WWW cache-eket iktassunk.
Hogyan müködik a WWW cache?
A HTTP cache szerver használata esetén a WWW kliens (böngészö) nem közvetlenül az eredeti forráshoz fordul amikor egy objektumot le akar tölteni, hanem egy úgynevezett cache szerverhez (HTTP cache, proxy szerver). A cache szerver ellenörzi hogy a kívánt objektum megtalálható-e a saját lokális tárolójában (a cache-ben) és ha igen, akkor azt innen adja és nem a forrás WWW szerverröl tölti le. Ezáltal nem kell a sokszor igen leterhelt és ezért lassú müködésü nemzetközi vagy belföldi nagy távolságú összeköttetéseket igénybe venni és ezzel tovább terhelni. Mivel egy cache szervert sok felhasználó használ, ezért jó esélye van annak hogy a kívánt objektumot nem sokkal elöttünk valaki már lekérte és így az bekerült a cache-be és ott megtalálható. Egyetlen független cache szerver használata esetén is a Találati arány általában >20%, azaz legalább minden ötödik lekérdezni kívánt objektum a cache-ben megtalálható.
Ha az objektum még sincs a cache-ben, akkor a cache szerver vagy más közeli cache szerverektöl próbálja meg azt letölteni (hierarchikus cache rendszer) és továbbítani a kérdezö WWW böngészö programnak, vagy az eredeti forráshoz (WWW szerverhez) fordul.
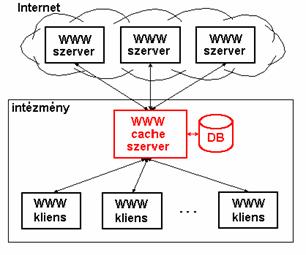
3. ábra. Független, intézményi cache szerver
Az együttmüködö cache szerverekböl nagy hatékonyságú hierarchikus cache rendszer építhetö ahol a találati arány még nagyobb mint a független cache szervereknél (gyakran 30% fölé emelkedik). A hierarchikus cache rendszerbe kapcsolt cache szerverek együttmüködnek, egymással szomszéd vagy szülö-gyerek viszony alapján kommunikálnak. A párbeszédre egy külön erre a célra kifejlesztett Internet protokollt, az ICP-t (Internet Cache Protocol) használják.
A felhasználók WWW kliens programjaiban konfigurálható az hogy melyik cache szervert vegyék igénybe.
Nem csak a HTTP, hanem az FTP és gopher forgalom is cache-elhetö, és a legtöbb cache szerver és WWW kliens erre lehetöséget ad. Mindazonáltal a leghatékonyabb müködés - épp a forgalom volumene miatt - a HTTP cache-eléssel érhetö el.
Hogyan használjuk?
A WWW cache használata igen egyszerü. A legtöbb elterjedt WWW böngészö (kliens) programot (Netscape, Mosaic, Lynx, Internet Explorer) könnyü úgy konfigurálni hogy cache szervert (proxy-t) vegyen igénybe. Figyelem: most nem az adott böngészö lokális cache-éröl van szó (amely sokkal kisebb hatékonyságú), hanem az igazi, külsö cache szerverröl (proxy szerver)!
Az egyetlen adat amire szükségünk van az a legközelebbi, általunk is használható cache szerver domain neve és a cache szolgáltatás számára felhasznált TCP port száma. (A port szám leggyakrabban - persze facto szabványként - a 3128.) A hálózati értelemben (hálózati összeköttetés szempontjából) vett legközelebbi cache szerverröl van szó, elöfordulhat hogy földrajzi értelemben nem ez a legközelebbi. Általában egy-egy intézmény, cég üzemeltet cache szervert a saját felhasználóinak a kiszolgálására. Rendszerint egy cache szervert csak egy meghatározott, a szerver üzemeltetöje által megszabott felhasználói kör vehet igénybe. (Ennek föként gazdasági okai vannak.) Ezért nem minden cache szervert használhat mindenki.
Tételezzük fel hogy az általunk használni kívánt cache szerver neve: cache.SLD.hu (ez fiktív név, ilyen nevü cache a valóságban nem létezik!) Ebben az esetben a cache használatának konfigurálása a népszerübb WWW kliensek esetében a következö:
Netscape 2.*, 3.*:
Menüböl
kiválasztható konfigurációs ablak:
Options -> Network Preferences ->
Proxies -> Manual Proxy Configuration (View)
Az "FTP Proxy, Gopher Proxy és HTTP Proxy" mezökbe rendre be kell írni azt hogy "cache.SLD.hu", a "Port" mezökbe pedig azt hogy 3128.
Mosaic 2.7:
Menüböl
kiválasztható konfigurációs ablak:
Preferences -> Proxy
A "HTTP Proxy Server, FTP Proxy Server, Gopher Proxy Server" mezökbe rendre be kell írni azt hogy "https://cache.SLD.hu:3128/"
Lynx 2.4:
Állítsuk be a "http_proxy, ftp_proxy és gopher_proxy" környezeti változókat a következö értékre: https://cache.SLD.hu:3128/
MS Internet Explorer 2.10:
Menüböl
kiválasztható konfigurációs ablak:
View -> Options -> Proxy
A "HTTP, Gopher és FTP" ablakokba be kell írni azt hogy "cache.SLD.hu", a kis ablakokba pedig azt hogy 3128.
A legtöbb browser esetében még megadható az is hogy mit NEM akarunk a cache-en keresztül lekérdezni (pl. a saját WWW szerverünket).
Ezt követöen böngészönk már használja is a cache-t. Ez valószínüleg meg fog nyilvánulni abban is hogy sok dokumentum gyorsabban töltödik le mint korábban. Ha valamilyen ok miatt szeretnénk kikényszeríteni azt hogy ne a cache-be már korábban letöltött, hanem biztosan az eredeti forrásból származó legfrissebb dokumentumot kapjuk, akkor használjuk a böngészö "reload" funkcióját. Ekkor a cache újra letölti az eredeti objektumot. A cache szerverek rendszerint maximum 24 órán át tárolnak egy objektumot, azt követöen - ha az megváltozott - igény esetén újra letöltik. Így semmiképpen sem fordulhat elö az hogy egy napnál régebbi dokumentumot kapjunk, de azért ez egy kicsit kínos is lehet, mondjuk ha egy tözsdei információ már egy napos akkor nem ér semmi. J
Elönyök, hátrányok
Minden éremnek két oldala van. Ennek is, de az egyik szerencsére sokkal fényesebb. Vizsgájuk meg tehát a cache használatából származó elönyöket és hátrányokat is.
Elönyök
A WWW dokumentumok elérése gyorsabbá válik. Mivel a statisztika szerint legalább minden ötödik letöltendö dokumentum a cache-ben már megtalálható, ezek - ha az eredeti forrás nagy távolságra van, vidéki vagy nemzetközi vonalakon érhetö csak el - sokkal gyorsabban érkeznek. A többi objektum esetében a letöltés sebessége ugyanakkora mint cache használata nélkül. (A cache szerverek által hozzáadott késleltetés olyan kicsi hogy nem érzékelhetö.)
A belföldi és nemzetközi Internet vonalak túlterheltségének csökkenése. Nagyon sok dokumentum ugyanis ahelyett hogy sokszor - minden hozzáféréskor - áthaladna ezeken a vonalakon, csak egyszer okoz forgalmat. A vonalak terheltségének csökkenése egyébként azt is jelenti, hogy minden egyéb forgalom - az is amelyik nem cache-elhetö - gyorsulni fog!
Költségmegtakarítás. Az információtovábbítás - különösen nagy távolságra - igen költséges dolog. A megtakarított forgalommal tehát jelentös költségmegtakarítás is elérhetö.
Hátrányok
Ritkán ugyan, de megtörténhet hogy egy-egy WWW oldalnak nem a legfrissebb verzióját kapjuk, hanem legfeljebb egy nappal régebbi változatát. Ez akkor fordulhat elö ha az eredeti dokumentumot megváltoztatták azóta amióta azt a cache tárolja. Mivel a cache-ek általában legfeljebb egy napig tárolják a HTML szövegeket majd szükség szerint újra frissítik, a napi gyakorisággal változó oldalak esetén okozhat ez leginkább problémát. A WWW adatbázisok dokumentumainak túlnyomó többsége azonban "statikus", azaz nagyságrendekkel ritkábban változik.
A dinamikusan (az oldalra való hivatkozás pillanatában) generálódó dokumentumokkal nincsen probléma mert ezeket a cache-ek amúgy sem tárolják, tehát mindig az eredeti példányt töltjük le!
Ha gyanús hogy esetleg nem a legfrissebb dokumentumot látjuk és ki akarjuk kényszeríteni az eredeti letöltését, a böngészö "reload" funkciójával ezt bármikor megtehetjük.
Vannak olyan esetek amikor egy-egy dokumentum letöltése során a böngészövel nem lehet a "reload" funkciót elöidézni. Pl. olyankor amikor nem HTML dokumentumot töltünk le hanem valami mást, rendszerint a diszkre vagy egy külsö megjelenítö program számára. (pl. amikor FTP helyett használjuk a WWW böngészönket és olyasféle fájlokra hivatkozunk hogy: cikk.ps, MS-CSODA.EXE, szoftver.tar.gz, stb.) Ilyen esetekben ha újra kellene tölteni, nem használhatjuk a "reload" funkciót (mert a böngészökben nem implementálták) és ezért mindig a cache-böl kapjuk az esetleg elavult vagy hibás fájlt. Ilyenkor az a megoldás hogy az adott fájl letöltése idejére ki kell kapcsolni a böngészönkben a cache használatát.
A HUNGARNET cache hierarchiája
A magyar kutatói IP hálózat, az NIIF által üzemeltetett HUNGARNET bekapcsolódhatnak a HUNGARNET hierarchikus WWW cache rendszerébe.
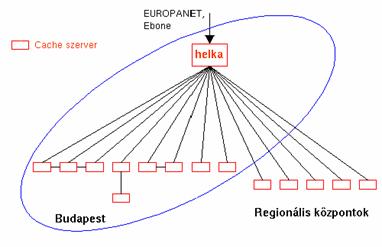
4. ábra.
Ez a cache rendszer jelenleg maximum három szintü. A felsö szinten található az NIIF parent cache szerver, a cache.iif.hu> (a helka.iif.hu gépen) amelyen pillanatnyilag a Squid 1.1. verziója fut és 5 Gbyte diszket valamint 200 Mbyte operatív memóriát használ az objektumok tárolására. A cache.iif.hu szolgálja ki a nagyobb vidéki és budapesti tagintézményekben már müködö lokális cache szerverek kéréseit. Egyes nagy sávszélességü összeköttetéssel rendelkezö budapesti cache szerverek egymást szomszédokként is használják.
A cache.iif.hu elegendö eröforrással és teljesítménnyel valamint jó hálózati kapcsolatokkal rendelkezik ahhoz hogy a központi cache szerepét ellássa. A fenti struktúra alkalmas arra hogy mind a külföldi, mind a belföldi vidéki vonalakon jelentös sávszélesség megtakarítást érjünk el.
Az NIIF részt vesz a TERENA által koordinált CHOICE projektben, melynek célja a cache rendszerek építésének összehangolása, és a jövöbeli összekapcsolásuk egy nagy európai cache rendszerré.
A HUNGARNET cache hierarchiáját, az abba kapcsolódó cache szervereket a tagintézmények felhasználói vehetik igénybe, söt, kell hogy igénybe vegyék, mivel ez a saját érdekük és a közös érdek egyaránt.
Cache szerver felállítása
Kinek és hol érdemes cache szervert felállítani?
Cache szerverek felállítása elsösorban ott célszerü ahol a kisebb vagy nagyobb helyi hálózaton (LAN) többen is használják a WWW-t és a hálózatot a külvilággal (Internettel) összekötö vonal kapacitása idönként vagy rendszeresen szüknek bizonyul. Tipikusan tehát intézményekben, cégeknél, Internet szolgáltatóknál. A cache szervert a hálózat olyan pontján kell felállítani amely jó (gyors) összeköttetéssel rendelkezik a külvilág felé.
A magyarországi akadémiai hálózatot üzemeltetö ill. koordináló NIIF Müszaki Tanácsa eröteljesen szorgalmazza a tagintézményekben a lokális cache szerverek felállítását.
Mi kell egy cache szerver felállításához?
Hardver: egy megbízhatóan üzemelö, UNIX operációs rendszerü gép. Bármilyen manapság elterjedt architektúra és UNIX verzió alkalmas. (LINUX is!) Nincs szükség túl nagy CPU kapacitásra (sebességre)! A fontos az hogy legyen elegendö memória ( >= 16 Mbyte a cache számára) és diszk (min. 50 Mbyte). A szükséges diszk kapacitás függ a cache-t használók számától is, de túlságosan túlméretezni nem érdemes a diszkterületet mert attól NEM lesz jobb a cache! Nem feltétlenül szükséges a cache szerver számára külön gépet dedikálni. A cache mellett a gépen egyéb alkalmazások is futtathatók.
Szoftver: több elterjedt, akadémiai környezetben ingyen használható cache szoftver van:
CERN httpd
Apache httpd
Harvest Cached 1.4
Squid
A fentiek közül a CERN httpd használatát nem ajánljuk mivel teljesítménye lényegesen elmarad a többitöl és hierarchiában is csak korlátozva használható. A Squid 1.1 a legújabb, és a Harvest Cached 1.4 továbbfejlesztéseként jött létre.
Az IPX/SPX protokoll
A Novell 1982-es indulásakor már számos egyedi hálózati kommunikációs protokoll létezett, melyek meglehetösen széles skálán helyezkedtek a sebesség, az egyszerüség és a kompatibilitás/hordozhatóság tekintetében. A Novell szakemberei hosszas mérlegelés után a Xerox által kidolgozott XNS protokoll mellett tették le voksukat és erre alapozva dolgozták ki saját IPX (Internetwork eXchange Protocol - hálózatok közti adatcsere protokoll) kommunikációs protokolljukat.
Az IPX datagram, azaz csomag-alapú hálózati kommunikációs protokoll. A protokoll a csomagok céljának ill. forrásának azonosítására egy 12-bájtos címzési sémát alkalmaz. Ez a 12 bájt három részre bontható: a 4-bájtos hálózati címre (amely a hálózati szegmenst azonosítja), a 6-bájtos node-címre (ami a hálózaton belül a csomópontot azonosítja) valamint a 2-bájtos socket-címre, Ez utóbbi funkciója annak meghatározása, hogy a célállomáson futó process-ek (folyamatok) közül melyik kapja ill. küldte a csomagot. (Ezek meghatározása elvileg teljesen önkényes lehet, de érdemes a Novell ill. más gyártók által fenntartottakon kívüli egyedi azonosítót használni a más programokkal történö ütközések kivédésére.)
A $FFFFFFFF node-szám megadásával szórt (broadcast), azaz nem csak egy, hanem a szegmensen belüli minden állomáshoz eljutó üzenetek küldésére is lehetöségünk nyílik.
A protokoll - mint az nevéböl is kiderül - képes a különbözö hálózati szegmensek között is csomagok továbbítására. Az IPX csomag a továbbítandó adatokon kívül magában hordoz egy ún. IPX-fejlécet is, amely a szegmensek közti vándorlás során is megörzödik és változatlanul tartalmazza több információ mellett a forrás- ill. a cél-állomás címét. Ez azért fontos, mert csomagok küldésekor ill. fogadásakor azonban közvetlenül (!) nyilvánvalóan csak az azonos hálózati szegmensben elhelyezkedö csomópontnak küldhetünk ill. csak azoktól kaphatunk csomagokat. Ezek a csomópontok azonban természetesen lehetnek szegmenseket összekötö bride-ek is, amelyek ez esetben nem csak az aktuális, de egy másik hálózat részei is - ott egy másik címen láthatóak. A bridge a csomagot megkapva azt a másik hálózatban útjára indítja, ahol azt vagy a tényleges célállomás kapja meg vagy folytatja útját egy újabb bridge-en keresztül afelé. A hálózati topológia és az ennek megfelelö ún csomag-továbbítási útvonalak (routing pathways) nyilvántartása a hálózati operációs rendszer feladata - nekünk evvel nem kell törödnünk, de minden egyes csomag elküldése elött meg kell kérdeznünk töle az ún. local target (helyi cél) címet, azaz azt, hogy hova az aktuális (!) szegmens mely csomópontjához kell elküldenünk csomagunkat a célállomás felé.
Fontos megkötés, hogy míg a szegmensen belüli maximális csomag-méretet a hálózati kártya - általában 1KB-ban - limitálja, addig a szegmensek közötti forgalom maximális csomag-mérete 576 bájt. Így érdemes inkább fixen 576 bájtos maximális csomag-mérettel dolgozni, mert így szegmens-közi kommunikáció esetén sem dobja vissza az összekötö bridge a csomagjainkat. Természetesen az ezt meghaladó mennyiségü adatot több csomagban vagyunk kénytelenek elküldeni.
Az IPX-szel szemben az SPX (Sequenced Packet eXchange - sorozatos csomag-csere) egy magasabb szintü stream-jellegü, kapcsolat-orientált protokoll. Az SPX az IPX-re épül, azaz amikor egy csomagot küldünk, akkor az SPX protokoll azt a belsö adminisztrációs munkák elvégzése után az IPX felé továbbítja. Az SPX garantálja a csomagot átvitelét, azaz a túloldali SPX-töl érkezö (vagy éppenséggel nem érkezö) válasz függvényében a csomagot újra elküld(het)i. E mellett az SPX a küldött ill. fogadott csomagot egy-egy sorozatszámmal is ellátja amely lehetövé teszi az esetleg csomag-vesztések detektálását a fogadó oldalon is. Ezen tulajdonságai rendkívül elönyössé teszik a kliens/szerver-architektúrákban történö felhasználásra, azonban jelentös feldolgozási idöt vesznek igénybe és ennek megfelelöen jelentösen - akár felére is - lassítják a kommunikációs sebességét.
A kommunikáció
A kommunikáció megkezdésekor elöször is meg kell nyitnunk egy új socket-et az IPXOpenSocket függvény segítségével. A megnyitás során meg kell adnunk a socket-számot ill. azt, hogy a programból történö kilépés esetén az magától (pontosabban az "IPX-töl") bezáródjon, vagy maradjon nyitva (TSR programok). Az IPX a csomagok érkezéséröl ill. küldéséröl egy kiegészítö struktúrákon, az ún. ECB-ken (Event Contol Block - esemény-vezérlö blokk) segítségével kommunikál a felhasználói programokkal. Ha sikerült a socket-et megnyitnunk (nem léptük túl az egyszerre nyitva tartható socket-ek max. számát ill. nem volt már eleve nyitva) akkor egy ún. listen-ECB-t ("fülelö-ECB"-t) kell nyitnunk az IPXListenForPacket segítségével amelyiken keresztül az IPX az esetlegesen beérkezö csomagokról értesíthet minket. Minden egyes csomag beérkezése után újabb listen-ECB-t kell nyitnunk (amely persze lehet ugyanazon a területen, mint az elözö) az újabb csomagok fogadásához. Hasonlóan, amennyiben csomagot szeretnénk küldeni úgy ezt egy megfelelö ECB felépítésével és annak az IPXSendPacket-nek történö átadásával tehetjük meg. (Fontos, hogy az ECB-ben célállomásként ne a tényleges, hanem az IPXGetLocalTarget által visszaadott címet adjuk meg. Amennyiben a tényleges célállomás az aktuális hálózati szegmensben helyezkedik el, úgy ez a függvény azt, míg egyéb esetben a célállomás hálózatához vezetö, az aktuális szegmensben is jelenlevö bridge címét adja vissza.) A funkció-hívásból történö visszatérés nem feltétlenül jelenti a csomag elküldésének megtörténtét - erról csak az ECB megvizsgálásával szerezhetünk információt. Az tényleges elküldés után a csomag ECB-je megsemmisíthetö, vagy helyette újabb hozható létre ugyanazon a memória-területen. Az ECB egyébként lehetöséget nyújt arra, hogy a csomag érkeztekor vagy továbbításakor egy általunk meghatározott rutin (melynek címét elözetesen az ECB-ben tároltuk) hajtódjon végre (megszakítás-szerüen) ezáltal feleslegessé téve az ECB-k állapotának állandó monitorozását. Az esetlegesen megnyitott, de még fel nem használt ECB-ket az IPXCancelEventsegítségével "vonhatjuk ki a forgalomból" ami után szabadon megsemmisíthetök. A kommunikációt és a socket-et az IPXCloseSocket függvény meghívásával zárhatjuk le.
A mellékletben (a forráskód.zip-ben) található IPXSPX.PAS
()unit a fent felsorolt függvényeken és eljárásokon kívül egy objektumot is rendelkezésre bocsájt, aminek segítségével gyerekjátékká válik a kommunikáció még azok számára is, akiknek esetleg nem minden volt teljesen világos a fentiekben. Mindenki bátran kísérletezzen a unit és az IPXCHAT
forráskódjával (Forráskód.ZIP). (Ja, és bár elsö látásra jó ötletnek tünhet, de senki ne kísérlezetten azzal, hogy ugyanazon a gépen a Windows egyik taszkjából a másikba üzenetet küld - sajnos nem fog menni.)
Az eredeti NetBIOS (Network Basic Input/Output System - hálózati alapvetö ki-/beviteli rendszer) az IBM által a PC-khez gyártott LAN adaptereken ROM-ba égetett, a teljes - az OSI modell mind a 7 rétegét lefedö - hálózatkezelést megvalósító interface volt, amit azonban az idök során továbbfejlesztettek és számos kiegészítéssel láttak el.
A NetBIOS egy magas szintü, - kódméret szempontjából - kényelmesen programozható hálózati felület, ami sikerrel müködhet akár más protokollokra épülö emuláció formájában is (pl. a Novell NetBIOS emulátora a parancsok végrehajtásánál valójában az IPX-et használja a csomagok átvitelére hálózaton), amely azonban nem alkalmas sebesség-kritikus valamint több hálózati szegmensre is kiterjedö kommunikációra. A NetBIOS napjainkban az Internet és a többszegmenses intranetek térhódításával veszt jelentöségéböl, azonban még ma is szinte minden elterjedt hálózati operációs rendszer támogatja használatát.
A NetBIOS lehetöséges nyújt mind kapcsolat-orientált, mind kapcsolat nélküli (üzenetszórásos) adatforgalom bonyolítására a hálózaton névvel azonosított (címzett) csomópontok között.
A NetBIOS nevek 16 bájtos karakterláncok, melyek az alábbi két nagy csoportba oszthatók.
az egyedi nevek (unique names) hálózati csomópontok azonosítására használhatók, melyekböl ennek megfelelöen mindig csak egy lehet a hálózati szegmensben. A hálózati név regisztrációja során a NetBIOS elöször mindig ellenörzi, hogy a név már használatban van -e a hálózaton, ezáltal elkerülve az azonos nevek által okozott címzési konfliktusokat.
a csoportnevek (group names) ezzel szemben akár több állomás által is használhatóak. Segítségükkel lehetöség nyílik a hálózati csomópontok egy jól meghatározott részhalmaza számára üzenetek küldésére. Amikor az üzenet küldése során célcímként egy csoportnevet adunk meg, akkor azt a csomagot minden, a csoportnevet használó munkaállomás megkapja.
Natív (nem emulált) NetBIOS protokoll alkalmazása esetén a kommunikáció során a hálózat minden egyes csomópontja megkap minden elküldött üzenetet, amelyek közül aztán a NetBIOS felsö rétegei az egyedi név ill. a "csoport-tagságok" vizsgálatával döntik el, hogy továbbítsák -e a kapott csomagot az alkalmazási réteg felé vagy sem.
Ennek megfelelöen minden munkaállomás egy vagy több névvel rendelkezhet melyek között több egyedi és több csoportnév is lehet.
A kommunikációnak szintén alapvetöen két fajtája létezik:
a kapcsolat nélküli (connectionless) kommunikáció során diszkrét, egyedi adatcsomagok ún. datagramok küldésére nyílik lehetöség más munkaállomás vagy csoport felé. A csomag vétele esetén a fogadó oldal(ak) semmilyen nyugtázást nem küld(enek) vissza, így nem garantált a csomag megérkezése a célállomásra sem. A csomag küldése során a specifikus (egyetlen állomásnak v. csoportnak szóló) küldési mód mellett lehetöségünk nyílik az IPX-böl már ismert broadcast üzenetek küldésére is, melyet minden - az broadcast üzenetekre figyelö - munkaállomás feltétel nélkül megkap.
ennél jóval magasabb szintü és biztonságosabb (de egyben lassabb) kommunikációra nyújt lehetöséget a kapcsolat-orientált (connection-oriented) üzenetváltási mód. A kapcsolat felépítésének kezdetén a munkaállomásnak egy ún. session-t kell nyitnia két név (egyedi vagy csoportnév) között. A session sikeres megnyitása után mind a két fél küldhet üzenetet egymásnak, melynek megérkezését (vagy a küldés sikertelenségét) a protokoll felügyeli, nyugtázás hiányában hibakódot visszaadva a küldö félnek.
A NetBIOS protokoll lehetöséget nyújt az alkalmazások számára mind szinkron, mind aszinkron kommunikáció megvalósítására. A két mód a NetBIOS parancsok végrehajtásának módjában tér el egymástól. Szinkron mód alkalmazása esetén az alkalmazói program a parancsok sikeres végrehajtásáig (v. a timeout-ig) nem kapja vissza a vezérlést az interface-töl. Tipikusan szinkron parancs pl. a név hozzáadása, hiszen az alkalmazás futása annak sikerétöl v. sikertelenségétöl függ. Ezzel szemben aszinkron parancsvégrehajtás esetén a hívás után az interface azonnal visszaadja a vezérlést a hívó alkalmazásnak, míg a parancs végrehajtásáról a késöbbiekben gondoskodik. Ez esetben a parancs kiadásakor alkalmazott NCB (NetBIOS Conrol Block - NetBIOS vezérlö-blokk) vizsgálatával, vagy egy speciális ún. POST-rutin segítségével lehet észlelni a parancsvégrehajtásának megtörténtét valamint kimenetelét.
Az interface
Mint arról már szó volt a NetBIOS interface ún. NCB-kel kommunikál az alkalmazásokkal - ezek segítségével nyílik lehetöség a parancsok kiadására. Az NCB felépítése és mezöinek jelentése a következö:
|
NCB |
Offset |
Méret |
Leírás |
|
|
00h |
|
Parancskód |
|
|
01h |
|
Visszatérési kód (végrehatási kód szinkron, inicializációs kód aszinkron parancs esetén) |
|
|
02h |
|
Helyi session-azonosító (az azonosítót a session megnyitásakor kapjuk meg) |
|
|
03h |
|
Helyi név-azonosító (a név hozzáadásakor kapjuk meg) |
|
|
04h |
|
Pointer az adat-pufferre |
|
|
08h |
|
Adat-puffer mérete |
|
|
0Ah |
|
Hívónév (a célállomás v. -csoport azonosítója) |
|
|
1Ah |
|
Helyi név (csak név felvételekor v. törlésekor használt) |
|
|
2Ah |
|
Fogadási timeout ? másodpercekben (max. ennyi ideig vár egy csomag megérkezésére) |
|
|
2Bh |
|
Küldési timeout (? másodpercekben) |
|
|
2Ch |
|
POST-rution címe (ha más mint nil, akkor a parancs befejezése után erre a címre adja át a vezérlést) |
|
|
30h |
|
Hálózati(-adapter) azonosító (csak több adapter alkalmazása esetén van jelentösége) |
|
|
31h |
|
Befejezési kód (aszinkron parancsok esetén FFh a feldolgozás alatt) |
|
|
32h |
|
Fenntartva (a hálózati illesztö számára, belsö célra) |
A NetBIOS parancskódok és jelentéseik a következök:
|
Kód |
Név |
Leírás |
|
10h |
CALL |
Új session nyitása két név között |
|
11h |
LISTEN |
Várakozás CALL-ra (session nyitására másik fél által) |
|
12h |
HANGUP |
Session lezárása |
|
14h |
SEND |
Adat küldése egy session-ön keresztül |
|
15h |
RECV |
Adat fogadása egy session felöl |
|
16h |
RECVANY |
Adat fogadása bármelyik session felöl |
|
17h |
SENDCH |
Két puffer küldése session-ön keresztül egyetlen paranccsal |
|
20h |
SENDDG |
Datagram küldése |
|
21h |
RECVDG |
Datagram fogadása |
|
22h |
SENDBRC |
Broadcast datagram küldése |
|
23h |
RECVBRC |
Broadcast datagram fogadása |
|
30h |
ADDUNIQ |
Egyedi név hozzáadása a helyi név-táblához |
|
31h |
DELNAME |
Név (egyedi és csoport) törlése a helyi táblából |
|
36h |
ADDGRP |
Csoportnév hozzáadása a helyi táblához |
|
32h |
RESET |
Adapter inicializásála és helyi névtáblázat törlése |
|
33h |
STATUS |
Adapter állapotának és hibastatisztikájának lekérdezése |
|
34h |
SESSSTAT |
Helyi session-ök állapotának lekérdezése |
|
35h |
CANCEL |
Végrehajtás alatt álló (aszinkron) parancs visszavonása |
|
37h |
ENUM |
Adapterek felsorolása |
|
78h |
FIND |
Név keresése a hálózaton |
|
79h |
TRACE |
NCB-követés ki-/bekapcsolása |
Amennyiben a parancskód 7. bitje 0 (parancskód<128) úgy azt szinkron, míg bekapcsolt állapota mellett aszinkron módon hajtja végre.
Reset
A parancs alaphelyzetbe állítja és konfigurálja a NetBIOS session-réteget. A megengedni kívánt session-ök maximális számát (1-32) az NCB 02h ofszeten elhelyezkedö (helyi session-azonosító) mezöjében, míg az egyeszerre feldolgozás alatt álló parancsok maximális számát (szintén 1-32) a 03h ofszeten lévö (helyi-név azonosító) mezöbe kell tölteni a hívás elött. A parancs meghívásakor minden session megszakad, a helyi név-tábla törlésre kerül és az összes várakozó állapotú parancs megszakításra kerül. (Amennyiben a NetBIOS fölött az alkalmazásunkon kívül más réteg is elhelyezkedett - pl. a hálózati op. rendszer - akkor az ettöl a parancstól természetszerüen "lehal" - ennek megfelelöen óvatosan kell bánni ezzel a paranccsal.)
Cancel
A parancs segítségével egy, már feldolgozás alatt álló - a session layer által egy NCB híváson keresztül átvett - de még végre nem hajtott parancsot lehet visszavonni. A parancsot csak szinkron-módban lehet kiadni és a RESET, CANCEL, ADD NAME, ADD GROUP NAME, DELETE NAME, SESSION STATUS, SEND DATAGRAM, SEND BROADCAST parancsok kivételével bármely parancsra alkalmazható. (Érdemes itt megjegyezni, hogy bár a SEND és a CHAIN SEND parancsok is visszavonhatók, de visszavonásuk egyben a session megszakítását (lezárását) is maga után vonja.)
Adater status
E parancs segítségével nyílik lehetöségünk a helyi vagy akár egy távoli NetBIOS session layer hiba-statisztikájának, állapotának és név-táblázatának lekérdezésére. A parancs végrehajtása elött a lekérdezni kívánt gép egyedi azonosítóját (nevét) vagy a helyi session layer lekérdezése esetén a "*"-ot kell elhelyezni a 0Ah ofszeten kezdödö hívónév mezöbe.
Add unique name
A név-táblázathoz történö egyedi azonosító hozzáadására nyílik lehetösgünk a parancs segítségével. A parancs végrehajtása során a NetBIOS a teljes hálózatot átnézni, hogy a megadott (maximum 16 karakter hosszú) név nincs -e már használatban valahol. Amennyiben talál a megadottal egyezö csoport- vagy egyedi nevet, abban az esetben a 0Dh (duplikált név) hibakódot kapjuk, egyébként pedig a név felvétele mellett egy egyedi (1-254) azonosítóval tér vissza a helyi név azonosító (03h) mezöben.
Add group name
Új név-csoport létrehozására vagy egy már létezö csoportba történö belépésre nyílik lehetöségünk a parancs segítségével. A parancs sikeres végrehajtásának feltétele, hogy a megadott név ne legyen már egyedi névként regisztrálva a hálózaton (csoportnévként nyilvánvalóan lehet, hiszen a csoport lényege, hogy több gép is bele-tartozhat és a csoportnévnek küldött üzeneteket, minden ilyen csoportnevet definiáló gép megkapja).
Delete name
Egy már regisztrált egyedi vagy csoport-név a helyi név-táblázatból történö törlésére ad módot a parancs. Amennyiben a névet egy vagy több nyitott session használja, úgy az nem azonnal, hanem a csak a session-ök automatikus bezására után került törlésre, de addig is minden e név használatával kiadott parancs a 17h (a név már törlésre került) hibakódot fogja visszaadni.
Call
A parancs segítségével nyílik lehetöségünk egy helyi és egy másik név közötti session létrehozására. A kapcsolat sikeres felépítéséhez a hívónév mezöben megadott gépnek e parancs kiadása (v. a time-out lejárta) elött egy LISTEN parancsot kell(ett) kiadnia az általunk használt helyi (vagy bármilyen ("*") ) névre. A sikeres kapcsolatfelépítés esetén visszaadott helyi session-azonosító segítségével küldhetünk ill. fogadhatunk csomagokat a másik gép felöl, illetve ennek segítségével tudjuk a session lezárni a HANGUP paranccsal.
Listen
A parancs kiadásával utasítható a session layer egy beérkezö session-nyitási kérelem fogadására. A kérelem fogadását egy specifikus vagy bármilyen névhez ("*") köthetjük, melyet az NCB hívónév mezöjében kell elhelyeznünk. (Amennyiben egyedi nevet adtunk meg, úgy csak egyetlen, a megadott névtól a mi gépünk felé érkezö session-nyitási kérelem került fogadásra, minden más session-felépítési próbálkozás sikertelen lesz.) Egy név illetve egy név-pár között akár több session is nyitható melyek egymástól teljesen függetlenül menedzselhetök. (Amennyiben egy bejövö session-nyitási kérelem (CALL) egy specifikus és egy bármilyen névre vonatkozó LISTEN-nek is megfelel, abban az esetben - az esetlegesen eltérö aktiválási sorrendtöl függetlenül - a specifikus LISTEN parancs fog végrehajtódni.)
Hangup
A parancs egy már megnyitott session lezárására használható. A session lezárását mind a hívó (aki a CALL-t aktiválta), mind a fogadó (aki a LISTEN-t aktiváltva) fél kezdeményezheti, melynek hatására a másik fél által a szóbanforgó session-re vonatkozó parancsok a 0Ah (session lezárva) hibakóddal fognak visszatérni.
Session status
A parancs egy adott névvel (akár hívó, akár fogadó félként) megnyitott session-ök, illetve azok paramétereinek lekérdezésére használható.
Send
A parancs segítségével nyílik lehetöségünk egy másik géppel megnyitott session-ön keresztül adat-csomag küldésére. A csomag sikeres átviteléhez a célállomásnak legalább egy RECEIVE vagy RECEIVE ANY parancsot kell aktiválnia a parancs kiadása vagy a session megnyitásakor megadott küldési time-out lejárta elött. A session layer a send parancsokat kiadásuk sorrendjében hajtja végre. Amennyiben egy csomag átvitele sikertelen, a session automatikusan bontásra kerül a küldö fél által.
Receive
A parancs segítségével nyílik lehetöségünk egy másik géppel megnyitott session-ön keresztül adat-csomag fogadására. Amennyiben a session megnyitásakor megadott idön belül a másik oldal nem aktivál egy SEND parancsot, abban az esetben a parancs 05h (time-out) hibakóddal tér vissza. (A fogadási time-out - a küldésivel szemben - nem vonja maga után a session bontását.) A RECEIVE parancsok kiadási sorrendben lesznek teljesítve elegendö számú fogadott csomag esetén, de amennyiben egy csomag egy RECEIVE és egy RECEIVE ANY parancsnak is megfelel, abban az esetben a RECEIVE parancs fogja megkapni. Amennyiben az NCB-ben megadott pufferméret túl kicsi a teljes fogadott csomag eltárolásához úgy a pufferméretnek megfelelö rész-csomag fogadása mellett a parancs 06h (data buffer to shoort) hibakóddal tér vissza.
Receive any
A parancs használatával több vagy az összes nyitott session-ön keresztül érkezö adat-csomag fogadására nyílik lehetöségünk. A fogadás feltételeire a RECEIVE parancsnál leírtak érvényesek. Sikeres fogadás esetén az NCB 02h ofszeten kezdödö (helyi session-azonosító) mezöje annak a session-nek a számát tartalmazza, amelyiken keresztül a csomag érkezett.
Send datagram
A parancs segítségével kapcsolaton (session-ön) kívül küldhetünk csomagot egy, az NCB 0Ah ofszetén kezdödö (hívó-név) mezöjében meghatározott állomásnak vagy csoportnak. A NetBIOS implementáció nem feltétlenül garantálja a csomag megérkezését a célállomás(ok)ra. Az átvitendö csomag mérete nem haladhatja meg az 512 bájtot. (Bizonyos NetBIOS implementációkban és alkalmazási környezetekben annyira rossz az átviteli biztonság, hogy az e módon elküldött és sikeresen fogadott csomagok aránya az 50%-ot sem éri el.
Receive datagram
A parancs segítségével a kapcsolaton kívül küldött csomagok fogadására nyílik lehetöségünk. Amennyiben a 03h ofszeten elhelyezkedö (helyi név-azonosító) mezö 0ffh értéket tartalmaz úgy bármely, egyébként pedig az által meghatározott névre érkezö csomagot fogadhatjuk a parancs kiadásával. A parancs nem rendelkezik time-out-tal, így visszavonásáig aktív marad. Sikeres csomag-fogadás esetén a küldö állomás által használt nevet a 0Ah ofszeten kezdödö (hívó-név) mezö tartalmazza.
Send broadcast
A parancs segítségével minden aktív RECEIVE BROADCAST paranccsal rendelkezdö állomásnak történö üzenetküldésre nyílik lehetöségünk. A maximális csomagméret nem haladhatja meg az 512 bájtot. A parancs tipukus felhasználása a hálózaton jelenlévö szerverek enumeráltatása, vagy egy specifikus gép keresése.
Receive broadcast
A parancs segítségével a SEND BROADCAST segítségével szétszórt üzenetcsomag fogadására nyílik lehetöségünk. A RECEIVE DATAGRAM-hoz hasonlóan e parancs sem rendelkezik timeout-tal és sikeres fogadás esetén a hívó-név mezöben tartalmazza küldö állomás nevét.
Találat: 2935