 | |||||||||
|  | ||||||||
| |||||||||
| | ||||||||
| kategória | ||||||||||
|
|
||||||||||
|
|
||
Budapesti Müszaki és
Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Kar Automatizálási és Alkalmazott Informatikai Tanszék Alkalmazott Informatika Csoport
T i
Informatika 2. gyakorlat
hallgatói segédlet
6. mérés
Formális nyelvek a gyakorlatban
A mérés elsödleges célja az elöadás a formális nyelvek témakörében elhangzott elméleti konstrukciók gyakorlatban történö alkalmazása. A segédlet feltételezi, hogy a hallgató ismeri a formális nyelvek megadására használt nyelvtanokat, a nyelvtani szabályok megadási módjait és az egyes nyelvosztályok közti alapvetö különbségeket. Ezek az ismeretek szükségesek a gyakorlat sikeres elvégzéséhez.
A formális nyelveket gyakorlati szinten legtöbbször fordító-programokban használják fel. A fordítóprogramok általánosságban képesek egy megadott forrásnyelven készített adatállományt egy célnyelvre lefordítani. A forrás és a célnyelv sokféle lehet, tipikus példa, hogy egy programozási nyelvröl (C++) gépi kódú alkalmazást készítünk. Fontos azonban tudnunk, hogy fordítókat nem csupán programozási nyelvek feldolgozásához használhatunk. Fordítóprogram segítségével értelmezhetünk pl. egy HTML nyelvü weboldalt és fordító programmal dolgozhatunk fel egy saját, speciális formátumot használó dokumentumot is. A formális nyelveket ebben az esetben a fordítás mechanizmusának leírására, a fordítási szabályok megadásához használjuk, ahogy az a segédletben bemutatott példán is látszódni fog. A fordítókról rengeteg jó, részletes és áttekintö jellegü leírás van az Interneten[1], ill. nyomtatott könyv formájában.
A gyakorlat célja, hogy a hallgatók használják fel a formális nyelvekkel kapcsolatos ismereteket egy gyakorlati példa megoldásában, ismerkedjenek meg a fordítók készítésének föbb lépéseivel és müködésük mechanizmusával egy egyszerü példán keresztül.
A legfontosabb fordítási lépések az 1. ábrán láthatóak[3]:
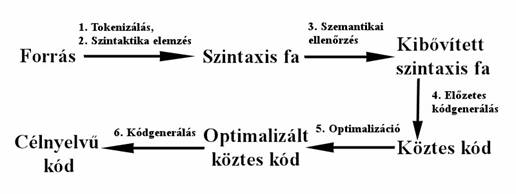
. ábra Fordítási lépések
A kiindulás a forrásnyelvü adatállomány, ami elsö lépésben kisebb blokkokra, tokenekre bontunk. A tokenizálás során a forrásnyelvü adatállományt jelentö karaktersorozatból a fordító számára önálló jelentéssel bíró atomi elemeket készítünk, ezek a tokenek. Egy-egy token lehet egy elemi szó, egy utasítás neve, egy változó, egy szám, vagy karaktersorozat. Ebben a lépésben távolítjuk el a felesleges sortöréseket és szóközöket is a forrásból.
A tokenekböl a következö lépésben a forrásnyelv szabályai szerint szintaxis fát építünk. Ez az a lépés, ahol a formális nyelvek szerepet kapnak, mivel a szabályok megadása legtöbbször a formális nyelvekben megszokott formátumot követi. A felépített szintaxis fában már látható, hogy melyik müveletnek milyen attribútumai vannak, ill. a müveletek hogyan ágyazódnak egymásba.
Amíg az elsö két lépés során csupán a szintaktikai helyességet ell 616g65g enörizhettük, addig a harmadik lépés során a szintaxis fát ellenörizzük szemantikai szempontból. Itt ugyanis a szintaxis fa bejárásával már több információ áll rendelkezésre, így elvégezhetö többek közt az egyes kifejezésekhez tartozó típusok ellenörzése is.
A negyedik lépésben a szemantikailag ellenörzött szintaxis fából köztes kódot generálunk. Összetettebb feladatokban ezen a köztes kódon további ellenörzéséket (pl. adatfolyam ellenörzés) végezhetünk el, amivel csökkenthetjük a majdani futásidejü hibák esélyét.
Az ötödik lépés során a köztes kódot optimalizáljuk, ez föképp nagy forrásállományoknál és idökritikus végrehajtásnál kap nagy szerepet. A C++ fordítóba épített optimalizáció nélkül a C++ nyelvü programjaink is sokkalta lassabban futnának.
A hatodik lépésben legeneráljuk a célnyelvü adatállományt (pl. bináris kódot) az optimalizált köztes kódból.
A fordítás lépései a komolyabb fordítókban gyakran több, mint hat lépésböl állnak, de léteznek olyan egyszerü feladatok is, ahol egyes lépések kihagyhatóak. Általánosságban elmondható, hogy az elsö két lépés, valamint a kódgenerálás minden fordítóban megtalálható, a többi opcionális. A fordítási folyamat elsö két lépése nagyrészt automatizálható, ha a tokenek definícióját és a szintaxis fát építö nyelvtani szabályokat megadjuk. Az automatizálás lehetösége nem csak egyszerü mintapéldák esetében lehetséges, hanem olyan bonyolult feladatokban is, mint pl. a C++ kódból Java kódra történö fordítás. A többi lépésnél ilyenfajta automatizálásra általánosságban nincs lehetöség. A tokenizálás és szintaxis fa építésének automatizálására több alkalmazás, eszköz létezik, pl. Flex, Bison, ANTLR. A mérés során, és a segédletben is az ANTLR nevü programot fogjuk használni.
A tokenizálás automatizálása során a token-definíciók általánosságban regurális kifejezések, vagy EBNF[5] szabályok segítségével adhatóak meg. Az ANTLR esetében használható szabályok formátumát az A melléklet tartalmazza.
A nyelvtani szabályok a formális nyelveknél tanult módon, a mondatszimbólum nemterminálisokra történö bontásával adhatóak meg. Természetesen a nemterminális szimbólumok további felbontását is meg kell adni egészen a terminális szimbólumokhoz vezetö szabályokig. Az ANTLR esetében használható szabályok sajátosságait a B melléklet foglalja össze.
Az ANTLR számára megadott tokenizáló és szintaxis fát építö szabályokat egy nyelvi definíciós fájlban kell megadni. Az ANTLR ezen fájl alapján olyan osztályokat generál, amelyek képesek elvégezni a forrás elemzését, tokenekre bontását, valamint a szintaxis fa felépítését. A fa elkészítését követöen a programozó feladata, hogy további ellenörzéseket folytasson (a szemantikai elemzés keretein belül), amennyiben azokra szükség van, ill. kódot generáljon a szintaxis fa alapján. A nyelvi definíciós fájl szintaktikai felépítését a C melléklet tartalmazza.
Az ANTLR otthoni telepítésével kapcsolatos információk a D mellékletben találhatóak meg. Fontos, hogy a mérés sikeres elvégzéséhez nem szükséges az ANTLR otthoni feltelepítése, csupán a segédlet példáinak megismerése és megértése. A mérésre való felkészülést segítendö jelen segédlet mellé letölthetök a project fájlok is, amikben csak az ANTLR telepítési útvonalát kell átírni (amennyiben az szükséges).
Mind a segédletben leírt példa, mind a mérésen elvégzendö feladatok javarészt a tokendefiniciók és faépítö szabályok megadásából, valamint ennek a fának a feldolgozásából állnak. A kezdeti szöveges formátumból tehát a feladatokban az eddig elmondottak szerint elöször tokenek sorozatát készítjük majd el, utána ezekböl a tokenekböl építjük fel a szintaxis fát. A példák szemléltetésén látványos felrajzolni ezt a szintaxisfát, ahogy az a 2. ábrán is látható egy konkrét példa esetén.


. ábra Példa szintaxis fa
A fa ez esetben azt mutatja, hogy egy SubString müveletnek három gyermeke
(három paramétere) van: a kiindulási karakterlánc, a kezdö index és a
kimásolandó karakterek száma.
Ennek az ábrázolásmódnak a használata sokszor nehézkes (elsösorban nagy fák esetén), ezért gyakran használják egy szöveges formáját:
#(Gyökér_elem Gyerek_1 Gyerek_2 . Gyerek_N)
A leírásban mi is fogjuk ezt a formát használni és az ANTLR fa bejáró
kódrészletében is szerepet kap, ezért érdemes megjegyezni.
A feladat egy, a standard inputon megadott müveletsor beolvasása és a müvelet eredményének kiírása. A müveletsor csak egész számokat, a "+" és a "*" müveleteket, valamint zárójelet tartalmazhat.
A feladat megoldása a .g fájl
megadásával történik. Ebben a fájlban kell megadni mind a token definíciókat, mind a szintaxis fa építö akciók pontos
szabályait.
A tokenek definíciója viszonylag egyszerü, szükség van a számok, a müveleti jelek, a zárójel megadására, valamint két speciális elemre. Az egyik elem segítségével a szóköz és sortörés karaktereket szürjük ki a bemeneti karakterek közül, a másik egy, a müveleti sort lezáró karaktert. Ez utóbbi karakter jelzi a feldolgozandó karaktersor végét.
A müveleti jelek ebben az esetben egy karakteresek. Az ANTLR-ben megszokott konvenció szerint a tokeneket leíró szabályokat csupa nagy betüvel adjuk meg. Ennek megfelelöen pl. a szorzás jelnek a következö szabály felel meg:
STAR: '*';
Azaz a szorzást a '*' karakterrel fogjuk jelölni és a token neve 'STAR' lesz (ilyen néven hivatkozunk majd rá a szintaxis fa építésekor). Hasonló szabályt adhatunk meg az összeadáshoz is (PLUS: '+';). A zárójelek esetében két tokent is kell definiálnunk:
A lezáró karakter szabálya szintén egyszerü (SEMI: ';' ; ). Ebben az esetben tehát a lezáró karaktert ';'-vel fogjuk jelölni és SEMI (az angol semicolon alapján) lesz a token neve.
A következö teendö a számokat reprezentáló token megadása:
INT: ('0'..'9')+;
Azaz a szám (INT token) 0 és 9 közti karakterekböl áll (a '..' az intervallum jelölésére szolgál), méghozzá ezen jelcsoportból (a csoportot a zárójellel zártuk egységbe) minimum egy van (ezt jelöli a '+' jel). A csoport hosszát nem specifikáljuk, azaz elviekben bármilyen hosszú számokat elfogadunk.
Végül szükség van a felesleges szóközök (white space) eltüntetésére is:
WS : ( ' ' | '\r' | '\n'| '\n' | '\t')
;
Ez a szabály bonyolultabb az elözöeknél. Több olyan karakter is van, amit szeretnénk figyelmen kívül hagyni, ezért a szabályban több lehetséges kódot (szóköz, sortörés, tab) is megadunk közöttük "vagy" jelegü kapcsolatot létesítve. Ez azt jelenti, hogy az ANTLR bármelyik kódot is olvassa a forrásból, mindenképpen ezt a szabályt fogja alkalmazni. További újdonság, hogy a token definíciója után itt megadunk egy végrehajtandó akciót a kapcsos zárójelek között. A setType müvelet egy beépített függvényre hivatkozik, ami beállítja az aktuális token típusát Token.SKIP-re. A Token.SKIP konstans azt jelenti, hogy az adott tokent nem akarjuk felhasználni a szintaxis fa építése során.
A következö lépés a szintaktikai szabályok megadása. Négy szabályra lesz szükség: egy magának a pontosvesszövel végzödö teljes kifejezésnek a leírására, egy a szorzás, egy az összeadás és egy a zárójeles kifejezések leírására.
Az elsö szabály:
Sentence: expr SEMI!;
Ez a szabály azt fejezi ki, hogy a számológépbe beütött müveleti sor egy kifejezésböl áll, amit pontosvesszö (SEMI token) zár le. A felkiáltó jel a SEMI tokent követöen azt jelzi az ANTLR számára, hogy magát a lezáró karaktert már ne tegye a szintaxis fába.
A második szabály:
expr: mexpr (PLUS^ mexpr)*;
A szabály az expr nevü nemterminális felbontását írja le, ami áll egyrészt
egy mexpr nevü nemterminálisból, valamint egy csoportból (zárójel jelzi a
csoport definicióját), ami bármennyiszer ismétlödhet, de akár el is
hagyható (ezt jelzi a '*' a zárójel mögött). A csoport a definició szerint '+'
jelböl és egy újabb mexpr nemterminálisból tevödik össze.
Külön szót érdemel még a PLUS tokent követö '^' jel. Ez azt jelenti, hogy az expr feldolgozása során a PLUS token nem az mexpr-el egy szinten lesz, hanem annak gyökérelemeként jelenik meg a fában. A jobb érthetöség kedvéért nézzünk egy másik példát is erre. Ha van egy szabály:
a : A B C;
Akkor a fa aktuális elemének
(ahonnan az 'a' szabályt meghívtuk) három gyermeke lesz: A, B és C (a szintaxis fa szöveges formájával:
(#a A B C).
Evvel szemben, ha a szabályt
a : A B^ C;
formában írjuk, akkor ez egy olyan részfát fog építeni az aktuális elem alá, aminek a gyökere B lesz és annak két gyermek eleme lesz: A és C, azaz (#a (#B A C))
Ebben az esetben a "^" jelre azért van szükség, mert így a késöbbi lépések során, amikor a fát be szeretnénk járni elöször kapjuk majd meg a müveleti jelet és után kérhetjük el az operandusait. Ha a két mexpr egy szinten lenne a PLUS tokennel, akkor a szintaxis fa nehezebben átlátható és feldolgozható lenne.
A harmadik szabály a szorzást írja le:
mexpr: atom (STAR^ atom)*;
A szabály felépítése hasonló, de itt mexpr helyett atom-okra bontunk és a müveleti jel PLUS helyett STAR, valamint az mexpr-t már nem kell SEMI-vel lezárni. A lezárás azért maradhat el, mert azt már az expr szabály alkalmazásakor felhasználtuk, ott már elöírtuk, hogy a müveleti sor legvégén majd pontosveszöre lesz szükség. Ha itt újra megkövetelnénk ezt, akkor az azt jelentené, hogy minden müvelet végére is ki kell tennünk a pontosvesszöt.
Ellentmondásosnak tünhet elsö pillanatban, hogy a szabályoknál elöször alkalmazzuk az összeadást, majd a szorzást, holott a matematikában megszokott müveleti jel sorrend pont fordítva tenné ezt indokolttá. Az ellentmondás azonban csak látszólagos, ugyanis arról van szó, hogy a szorzás jelen esetben "erösebben köt", mint az összeadás, azaz a szorzás müveletét elöbb kell végrehajtani, mint az összeadásét, amikor a fát építjük. Például a 2+3*4+1; kifejezés feldolgozásakor a helyes zárójelezés (2+((3*4)+1)) és nem ((2+3)*4)+1).
A negyedik szabály a zárójelezést oldja meg.
atom: LBRACKET! expr RBRACKET!| INT;
Azaz az atom nevü nemterminális vagy egy zárójelezett kifejezés, vagy pedig egy szám. A zárójeleket természetesen nem építjük bele a fába ("!"). Érdekesség a szabály rekurzív jellege, hiszen az expr-t bontottuk mexpr-re (második szabály), majd azt tovább bontottuk atom-ra (harmadik szabály) és most a szabály szerint az atom expr-ra történö bontását is megengedjük. Ez a megoldás azt fejezi ki, hogy bármilyen kifejezés szerepelhet zárójelben, ami egyébként önállóan is kiértékelhetö lenne.
A .g fájlt a fentieken kívül ki kell még egészíteni néhány dologgal, mielött használni tudnánk.
A legfontosabb kiegészítés, hogy az ANTLR által generálandó kódba még valamiféleképpen be kell illesztenünk az alkalmazás logikáját, azaz nem elég ha a szintaxis fát felépítjük, de a számológép eredményét is ki kell számolni. Ennek a legegyszerübb módja, ha megadunk egy függvényt a .g fájlban, ami a fa alapján egyböl ki is számolja a kifejezés értékét:
expr returns [int r]
: #(PLUS a= expr b= expr)
| #(STAR a= expr b= expr)
| i:INT
;
Ez a definíció a legenerált kódban egy expr nevü, int visszatérési
értékü függvényt fog eredményezni, ami rekurzívan kiszámítja az expr értékét. A függvény müködése a különbözö nyelvtani
szabályokat tükrözi. A #(PLUS a=expr b=expr) azt jelenti, hogy ha a program talál egy
részfát, aminek a PLUS token a gyökere (ezt jelöli a # jel), akkor vegye annak
két gyermekét, amiknek a típusa expr és amikre "a" és "b" néven
fogunk hivatkozni a továbbiakban. Ezek
után megadjuk, hogy milyen akció történjen, ha a szabálynak ez a része
alkalmazásra kerül. Ennek keretén belül az "r" változó értéke (ami a
gyökérelem, az aktuális expr értékét reprezentálja) a két
gyermek értékének összege lesz. Természetesen a gyermekek szintén lehetnek
összetett kifejezések (hiszen expr típusúak), ezért elöször
azokat kell kiszámítani. A szabály a
szorzás esetében hasonló módon jár el.
Ha az expr
már nem összetett, úgy a harmadik al-szabályt alkalmazzuk, azaz vesszük a token
int típusú értékét
(atof(i->getText().c_str());) és avval térünk vissza.
A létrehozott függvény tehát mélységi keresés jelleggel bejárja a fát és kiszámítja a globális gyökérelemnek, azaz magának az egész kifejezésnek az értékét.
Feltünhet, hogy a zárójel, ill. a SEMI token nem jelenik meg ebben a szabályban. Ennek az az oka, hogy a szabályt a már elkészült szintaxis fán fogjuk futtatni, amiben a nyelvtani szabályok szerint ezek a tokenek nem kerültek be. A zárójel által kifejezett müveleti sorrendet ebben az esetben már a szintaxis fa felépítése tükrözi.
A munka befejezéseként meg kell adnunk, hogy szeretnénk, ha az ANTLR felépítené a szintaxis fát a szabályok alapján (lehetöség van saját fa építésére is), valamint, hogy a .g fájlból generálandó tokenizáló és faépítö osztályokat C++ nyelven szeretnénk használni. Ezenkívül példányosítanunk kell a Flexer (tokenizáló), Parser (szabályvégrehajtó) és TreeParser (faépítö) osztályokat. Mivel ezek a beállítások jellemzöen nem változnak, ezért a mellékelt projectben található fájlt érdemes használni. Igaz ez a Main függvény implementációjára is, ami voltaképpen annyit tesz, hogy a standard inputon kapott karaktersorozatra meghívja az általunk készített mini-fordítót és kiírja a kapott eredményt.
A project fájlt (megtalálható mellékletként) ezek után már csak fordítani és futtatni kell. A program az elöbbiek szerint a standard inputról olvassa be a kifejezést, amit ki kell számolnia, és ne felejtsük el, hogy a müveleti sort minden esetben ";"-vel kell lezárni.
A mérésen elvégzendö feladatok és példa beugró kérdések az E mellékletben találhatóak.
A melléklet - Token szabályok
A tokenizálást elvégzö, ún. lexer teljes, részletes leírása a https://www.antlr.org/doc/lexer.html oldalon található. Ez a melléklet a segédlet példájához, ill. a mérésben szereplö problémák megoldásához szükséges elemeket taglalja néhány példán keresztül.
A tokenek definiciójában használhatóak a normál ASCII karakterek, valamint az escape szekvenciák, pl '\n'. A karakterekböl a következö konstrukciókkal készíthetünk token definíciókat:
. Táblázat
|
Szimbólum |
Jelentés |
|
|
Al-szabály, a zárójelen belüli jelek csoportként viselkednek |
|
|
A
zárójelen belüli csoport ismétlödik valamennyiszer |
|
|
A
zárójelen belüli csoport ismétlödik valamennyiszer |
|
|
A csoport vagy elöfordul (egyszer), vagy nem |
|
|
Szemantikai parancs (pl. szintaxis fa építése) |
|
|
Szabály argumentum (pl. visszatérési érték) |
|
|
Választási lehetöség a felsorolt elemek közül |
|
|
Tartomány (intervallum) |
|
|
"Nem" operátor (pl. nem szerepel egy bizonyos karakter) |
|
|
Joker karakter |
|
|
Hozzárendelés, legyen egyenlö |
|
|
Címke operátor, szabály kezdet |
|
|
Szabály vége |
Ennek megfelelöen pl az alábbi szabály
ID : ( 'a'..'z' )+ ;
Azt jelenti, hogy az ID token minimum egy karakterböl áll (és bármilyen hosszú lehet). Ebböl az ANTLR a .g fájl feldolgozása során ilyen jellegü függvényt készít:
public final void mID(...)
throws RecognitionException,
CharStreamException, TokenStreamException
} while (...);
...
Ha a tokenizálás során szeretnénk, ha a token nem jelenne meg a szintaxis
fában, szeretnénk a tokent eldobni, akkor a token típusát Token.SKIP-re kell
állítani:
WS : ( ' ' | '\t' | '\n' | '\r' )+
;
Ha ugyanezt az eldobást egy szabályon belül akarjuk jelezni (pl. zárójeles kifejezésnél a zárójel ne legyen a token része), akkor a '!'-lel tehetjük ezt meg:
MYINT: '('! INT ')'! ;
A karakterhivatkozásokat és a fenti
szimbólumokat tetszölegesen lehet kombinálni. Ebböl az ANTLR egy
olyan tokenizáló osztályt (Lexer) készít, aminek lesz egy nextToken() nevü
függvénye. Ezt a függvényt hivja meg a szintaktikus elemzö, amikor a
szintaxis fát építi. Ha a
szabályrendszer két szabályt tartalmaz:
INT : ('0'..'9')+;
WS : ' ' | '\t' | '\r' | '\n';
Akkor abból a következö jellegü függvény generálódik.
public Token nextToken() throws TokenStreamException
...
A tokeneken az ANTLR értelmez néhány függvényt, amik hasznosak lehetnek a szintaxis fa feldolgozása során:
|
Metódus |
Leírás |
|
$append(x) |
Hozzáilleszti az x nevü stringet az aktuális szabályhoz |
|
$getText |
Lekérdezi a szabályban tárolt szöveget és String típus formájában visszatér vele. |
|
$setType(x) |
Beállítja az aktuális szabály tokentípusát. |
Még egy fontos beállítási lehetöség van a tokenekkel kapcsolatban. Az ANTLR alap beállításként greedy (falánk) jelleggel dolgozza fel a token szabályokat, azaz minden karaktercsoporthoz megpróbálja a lehetö legnagyobb forrásrészletet illeszteni. Ez néhány esetben zavaró lehet, ha pl. arra van szükség, hogy egy nyitó zárójel után az elsö záró zárójelet találja meg (és ne az utolsó lehetségest), akkor azt be kell állítani. Erre az options rész greedy változójával van lehetöség), pl.:
stat : "if" expr "then" stat
( options : "else" stat)?
| ID
B melléklet - nyelvtani szabályok
Bár az ANTLR-ben a szintaxis fa építésénél használt szabályok szintaktikája nagyon hasonlít a formális nyelvekéhez, akad néhány különbség, elsösorban a fa építésének módjával kapcsolatban. A részletes leírás a https://www.antlr.org/doc/trees.html oldalon található.
A szabályok felépítése a nemterminális szimbólum: szétbontási szabályok formát követi, pontosabban a legtöbb esetben a
szabálynév
: szétbontás_1
| szétbontás _2
...
| szétbontás _n
;
A szétbontási szabályok megadásában ebben az esetben használhatjuk más nemterminális szabályok neveit, valamint az A melléklet I. táblázatában felsorolt szimbólumokat, módosítókat, pl.:
Variable: ('a'..'z') ('a'..'z'|'0'..'9')*
r : A B . C; // '.' jelentése: bármilyen más szabály
Amennyiben a szabály valamilyen paramétert kap, úgy a
rulename[formal parameters] : ... ;
forma használható. Hasonlóképpen, ha a szabálynak van visszatérési értéke:
rulename returns [type id] : ... ;
Különösen fontos ebben az esetben, hogy az egyes szabályokhoz, alszabályokhoz, vagy szabály részletekhez lehet megadni függvényhívásokat kapcsol zárójelek közt.
Speciális karakterként használható még a '^' jel, ami azt jelenti, hogy az adott elemet a lokális részfa gyökereként kell kezelni.
Ez a szabály elöször megpróbálja megtalálni a forrásban az "A" nevü tokent, majd ha ez sikerült, akkor a "B" tokent. Ha "B"-t is megtalálta, akkor "A"-t áthelyezi "B" gyermekének. A müvelet "C" megtalálásával folytatódik, majd "B" áthelyezése következik "C" alá. Az eredmény: "C" a lokális részfa csúcsa, egy gyermek van "B", aminek szintén egy gyermeke van, "A", azaz (#C (#B A)).
C melléklet - Nyelvi definíció
Az ANTLR által használt definíciós fájlt általában ".g" kiterjesztéssel hozzuk létre. A fájl a következö elemekböl épül fel:
Header fájlok inicializálása
Nyelvi beállítások
A Parser osztály definíciója (nyelvi szabályok)
A Lexer osztály definíciója (tokenek)
A TreeParser osztály definíciója (osztály a fa feldolgozásához)
Az 1. pontra akkor van szükség, ha saját faépítö algoritmust szeretnénk létrehozni, különben ez a lépés kihagyható.
A 2. pont azt szabályozza, hogy a nyelvi definíciót milyen programozási nyelv (C++, C#, Java, .) szintaktikájával kell értelmezni, ill. milyen nyelvüek legyen a definíciós fájlból generált osztályok. Ez egy nagyon fontos lépés, ugyanis az ANTLR Java alapú program, alapbeállításként Java osztályokat generál, ami a jelen mérésben nem megfelelö, mivel a mérés a fordítók C++ alapú változatát írja elö.
A 3. pont a forrásnyelv definíciója. Fontos megemlíteni, hogy az egyes szabályok elé és mögé saját kódrészleteket illeszthetünk be, amennyiben az szükséges. Ezek a kódrészletek képesek pl. az aktuális kifejezés értékét tárolni és változtatni a forrásban megadott müveleteknek megfelelöen.
A 4. pont a tokenek definícióját tartalmazza, egyszerü példák a tokenek megadására a z ANTLR honlapján[6] találhatóak.
Az 5. pont elhagyható, amennyiben saját fa reprezentációt alkalmazunk, vagy ha az elkészült szintaxis fán semmilyen müveletet sem szeretnénk elvégezni. A TreeParser-ek segítségével egyszerüen adhatunk meg a fa alapján elvégzendö müveleteket.
Az ANTLR által generált (C++) nyelvü fájlokat (jelen segédletben leírt, ill. a mérésen elvégzett feladatokhoz) egy Visual Studio project fájlba kell foglalni, majd le kell fordítani, aminek eredményeképpen kapunk egy egyszerü, de hatékony nyelvtani elemzöt a kiválasztott forrásnyelvhez. Ezeket aztán meghívhatjuk tetszöleges forrásállományra, hogy végezzék el a fordítást és feldolgozást.
A https://www.imada.sdu.dk/~morling/antlr/issue1.htm honlap részletesen leírja, hogy hogyan lehet az ANTLR programot otthoni környezetben beüzemelni. Habár a leírás egy régebbi ANTLR verzióhoz készült, mint amit a mérésen használni fogunk, a föbb lépések mégis megtalálhatóak a leírásban:
Le kell tölteni és fel kell telepíteni a Java Development Kit legújabb verzióját
Le kell tölteni (és fel kell telepíteni) az ANTLR legújabb verzióját a https://www.antlr.org oldalról. Érdemes figyelni arra, hogy az elérési útban sehol se szerepeljen szóköz karakter.
Hozzá kell adni a Path környezeti változóhoz a Java bin könyvtárát (ha az nem került oda magától)
Meg kell adni egy ClassPath nevü környezeti változót, itt a honlapon szerelötöl eltéröen elegendö a C:\antlr277\lib\antlr.jar értéket megadni (természetesen az ANTLR telepítési könyvtárát átírva), majd újra kell indítani a gépet (!)
Létre kell hozni Visual Studioban egy új, üres solution fájt[7], majd ehhez hozzáadni egy új C++ projectet.
Meg kell adni a következöket a project beállításainál:
a. AdditionalIncludeDirectories ="C:\antlr\277\include"
b. AdditionalDependencies ="C:\antlr\277\lib\antlr.lib"
c. AdditionalLibraryDirectories ="C:\antlr\277\lib"
A projecthez hozzá kell adni az egyes feladatok .g fájljából generált .cpp és .hpp fájlokot, majd le kell fordítani. A .g .cpp átalakítás parancssorból a java antlr.Tool mydeffile.g parancsot kell kiadni, ahol a mydeffile.g tartalmazza a forrás nyelvének definícióját.
A mérésre való felkészülést segítendö jelen segédlet mellé letölthetök a project fájlok is, amikben csak az ANTLR telepítési útvonalát kell átírni (amennyiben az szükséges).
Az elsö feladat egy, a standard inputon megadott müveletsor beolvasása és a müvelet eredményének kiírása. A müveletsor csak egész számokat ill. a négy müveleti jelet "+","-","/","*" tartalmazhat.
A második feladat az elsö feladatban szereplö számológép kiegészítése a hatványozás müvelettel. A müvelet szintaktikája x^y, aminek jelentése xy. Korlátozzuk a hatványozást úgy, hogy a hatványok hatványa (x^y^z) már ne legyen értelmezve. A feladat része a müveleti sorrend helyes kezelése is!
A harmadik feladat a korábban elkészített számológép kiegészítése, hogy az a tört számokkal végezhetö müveleteket is kezelhesse. A törtszámok egész és tört rész '.' karakterrel vannak elválasztva, a tört rész elhagyható (egész számok esetén).
Példák beugró feladathoz:
(ezt mindenkitöl érdemes megkérdezni)
Alfred V. Aho, Ravi Sethi, Jeffrey D. Ullman: Compilers Principles, Techniques, and Tools, Addison - Wesley, 1988
Találat: 3309