 | |||||||||
|  | ||||||||
| |||||||||
| | ||||||||
| kategória | ||||||||||
|
| ||||||||||
|
| ||
|
||||||||||
BMF-NIK Államvizsga Tételek - Szoftvertervezés
10. Dinamikus adatszerkezetek 1. (Bináris fa, láncolt lista, B-fa, alkalmazási esettanulmányok, elönyök, hátrányok)
LÁNCOLT LISTA
Az egyirányú láncolt lista
Ez egy nagyon egyszerü dinamikus adatszerkezet, amely egy eleje mutatóból, és rekordokból áll. A rekordok azonos típusúak: egy tartalom mezöböl és egy következö mutatóból állnak. Attól, hogy a mutatók egyértelmüen meghatározzák a végighaladás sorrendjét, az adatok a memóriában össze-vissza helyezkednek el. Az utolsó elem nil-re mutat. Ez jelzi a láncolt lista végét.
A tömbbel összehasonlítva
Új elem felvétele egyszerü, mert csak két mutatót kell beállítani. Törölni is gyorsan lehet: a törlendö elötti elem mutatóját a következöre állítjuk, öt pedig felszabadítjuk. Hátránya a tömbhöz képest: átlagosan n/2 lépésben találunk meg egy elemet, mert csak szekvenciálisan tudunk keresni egy rendezetlen listában.
Akkor érdemes láncolt listát használni, ha az elemek mennyisége változik, mert a memória dinamikusan foglalható. Rendezni nem érdemes, mert az elemek közvetlen elérése nem valósítható meg, és csekély sebességnövekedést eredményez.
Müveletek
Lista létrehozása
type
Pelem=^Elem;
Elem=record
tartalom: integer;
kovetkezo: Pelem;
end;
Itt megengedett, hogy elöbb használjuk a típus (Elem), mint deklarálva lenne.
Eleje:=nil; //nem hagyható el
Lista bejárása
P:=eleje; //segédváltozó
While p<>nil do begin
Kiir(P^.nev);
P:=P^.kov;
End;
Új elem felvétele
Lehetséges az elejére beszúrni vagy rendezett lista esetén egy megfelelö helyre. (elöbb egy keresési feladat) Láncol listában nem tudunk visszalépni, ezért tárolni kell az elözö címét.
Elejére szúrás
New(Q); //elem létrehozása
Q^.tart:=x; //tartalommal való feltöltés
Q^.kov:=eleje; //beláncolás az eleje mutató elé
Eleje:=Q; //Q lesz az eleje a listának
Rendezett beszúrás
Elejére: ha az elsö elemnél kisebb a beszúrandó, vagy üres a lista. Középre: meg kell keresni az elem helyét. Végére: ha nagyobb, mint az utolsó.
Lánc végére szúrás
While p^.kov<>nil do P:= P^.kov; //a végéig lépkedés
P^.kov:=R; R^.kov:=nil; //beláncolás, vége nil
Keresés
Szekvenciálisan végignézzük, amíg meg nem találjuk a keresett eleme(ke)t.
Törlés
Elöször egy keresés, aztán kiláncolás.
Strázsa-technika
Alapelv: definiálható két olyan elem (max és min), amelyek a lánca berakható elemek intervallumának széleit képezik. Ezek a megállási feltételek. Így a lista soha nem lesz üres, az ebböl származó problémák megoldódtak.
Kör adatszerkezet
A lista utolsó eleme nem nilre, hanem egy másik lista elejére mutat. A másik lista vége pedig ennek az elejére. Így csak a belépési pontot kell megjegyezni.
A kétirányú láncolt lista
Visszafelé is van mutató, oda-vissza is tudunk lépkedni. Rendezettségnél jól használható.
4. Bináris Fa (adatszerkezet, felépítés, bejárások, törlés, gyakorlati haszna, alkalmazási példák)
Adatszerkezet
A fa egy összefüggö körmentes gráf, tehát bárhonnan bárhová el lehet jutni rajta. Irányított, mert van egy gyökérpontja és ágai is. A gyökérpontba nem megy él, csak innen indulhat ki.
A bináris fa egy dinamikus (és rekurzív) adatszerkezet. Egy-egy levélpontja áll egy tartalom mezöböl, egy bal -és egy jobb mutatóból.
Felépítése: Az elsö elemfelvételnél a gyökérponthoz viszonyítva balra tesszük az elemet ha a gyökérnél kisebb, és jobbra, ha nagyobb. A többi elemfelvételnél ugyanígy elöször a gyökérponthoz viszonyítunk, majd elmegyünk az egyik irányba. Ha itt van már elem, azzal is összehasonlítjuk az új elemet, és elrakjuk annak a megfelelö oldalára.
Elfajult eset: ha növekvö sorrendben vesszük fel az elemeket, egyágú bináris fát kapunk, amellyel a bináris fa már értelmét veszti, hiszen egy ilyen fában átlagosan n/2 lépésben találunk meg egy elemet, ellentétben a kiegyensúlyozott fával, amelyben egy keresés átlagosan log2N ideig tart.
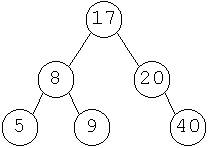
Például ilyen fa esetén
az elemek felvitelének egy lehetséges sorrendje: 17, 8, 5, 9, 20, 40. De
nem tudhatjuk mindig biztosan, hogy az elemeket milyen sorrendben vették
fel.
Bejárások
InOrder (bal, gyökér, jobb); PreOrder (gyökér, bal, jobb); PostOrder (bal, jobb, gyökér). Az In/Pre/Post a gyökér feldolgozásának idejére utal.
InOrder
procedure InOrder(p: pelem); //param.-ként kapott gyökér
begin
if P<>nil then begin //megállási feltétel
InOrder(P^.bal); //rekurzív hívások
Kiír(P^.tart); //Tevékenység
InOrder(P^.jobb);
end;
end;
A rekurzív hívás mindig eltárolja, hogy P hova mutatott. Müködése: az összes bal oldali elemet feldolgozza, mielött a gyökérre kerülne a sor. Rendezett, növekvö listát állít elö. Az elöbbi példa esetén: 5, 8, 9, 17, 20, 40. Ha csökkenö, rendezett listát szeretnénk, felcseréljük a bal mutatót a jobbra.
PreOrder
procedure PreOrder(p: pelem);
begin
if P<>nil then begin
Kiír(P^.tart);
PreOrder(P^.bal);
PreOrder(P^.jobb);
end;
end;
Az ezzel a módszerrel kapott lista alapján a fa rekonstruálható.
(Ha ilyen sorrendben vesszük fel az elemeket egy új, üres fába)
A példa alapján: 17, 8, 5, 9, 20, 40.
PostOrder
procedure PostOrder(p: pelem);
begin
if P<>nil then begin
PostOrder(P^.bal);
PostOrder(P^.jobb);
Kiír(P^.tart);
end;
end;
Elöször a levélelemeket dolgozza fel. A fa felszabadítása így lehetséges. Ha paraméterként nem a gyökérelemet kapja, hanem egy levélpontot, akkor az ez alatti elemeket szabadítja fel, beleértve a levélelemet is. (A részfa-törlö algoritmust lásd az 5. tételben)
A példa alapján: 5, 9, 8, 40, 20, 17.
Keresés
A rekurzív újrahívások során az algoritmus mindig elmegy balra, vagy jobbra, aszerint, hogy kisebb vagy nagyobb a keresett elem az éppen vizsgáltnál.
A megállás a tevékenység végrehajtása után következik be, mivel nem történik újabb rekurzív eljáráshívás.
Egy elem törlése
Cél: egy elem törlése minimális munkával.
A levélelemeket könnyü törölni, mert nincs alattuk semmi. Dispose(p) után a "szülö" elem mutatóit nil-re állítjuk.
Az egy leszármazottal rendelkezö elemeket is könnyü törölni: kiláncolás. Nehéz törölni azokat az elemeket, amelyeknek két leszármazottjuk van, mert feltétel a fa tulajdonságainak megtartása. Ebben az esetben a törlendö elem bal oldali részfájának legjobboldalibb elemével kell felülírni a törlendö elemet. Sorrendben ez a kisebb a törlendönél. Az eljárás hívása: Torol(törlendö, gyökér).
Bináris Fa és Típusos Fájl Összekapcsolás
Cél: nagyobb adatmennyiség gyors elérése háttértárról, a keresés megvalósítása log2N lépésben.
Módszer: Legyen egy név szerint rendezett típusos fájl. Ebben a logaritmikus keresés használható. Hátránya, hogy csak egy szempont szerint lehet egy idöben rendezett a fájl (fizikailag). Új elem felvétele, törlése a rendezettség megtartásának kényszere miatt lassú.
B-fa (alapvetö szabályok, új elem felvitel, keresés, törlés)
A bináris fa hátrányai
A B-fa (Bayer, 1972)
A B-fákban a csúcsoknak sok gyerekük lehet, akár több ezer is. A B-fák elágazási tényezöje sokkal nagyobb, mint a bináris fáké, ezért magasságuk lényegesen kisebb.
Ha a B-fa egy X csúcsa N[X] kulcsot tartalmaz, akkor az X-nek N[X]+1 gyereke van. Ha a B-fákban egy kulcsot keresünk, akkor (N[X]+1)-féle választásunk lehet, mert a keresett kulcsot N[X] kulccsal hasonlítjuk össze.
A B-fa magassága a benne lévö csúcsok számának növelésekor csak a csúcsszánok logaritmusával nö.
Tulajdonságai
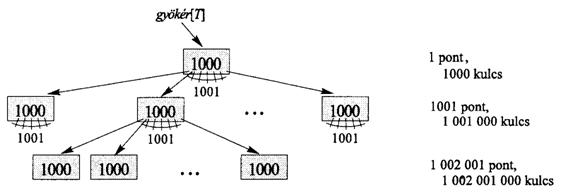
19.3. ábra. Egy 2 magasságú B-fa, amelynek több, mint egymilliárd kulcsa van. Mindegyik belsö csúcsnak és levélnek 1000 kulcsa van. Az 1 mélységben 1001 csúcs van, a 2 mélységben több, mint egymillió levél található. Minden x csúcsban n[x], azaz az x-ben levö kulcsok száma is látható.
Beszúrás
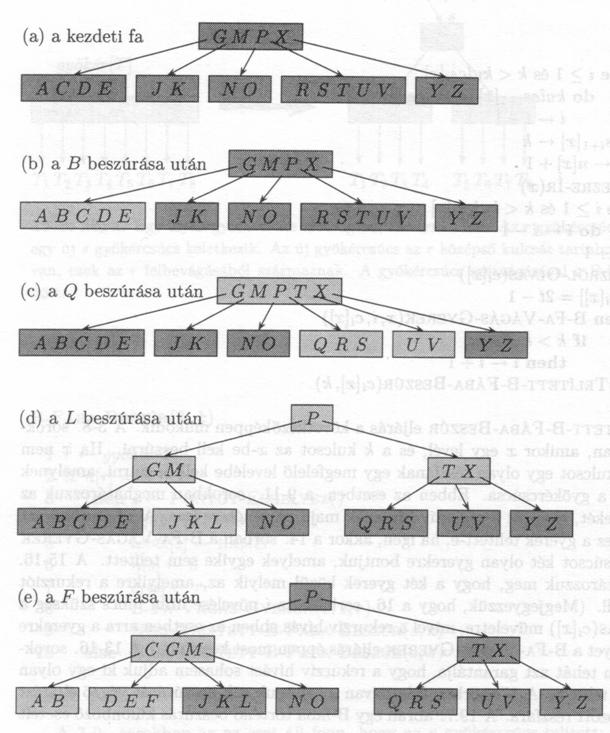
A B-fa t minimális fokszáma 3, ezért egy csúcsnak legfeljebb 5 kulcsa lehet. Azokat a csúcsokat, amelyeket a beszúrás alatt módosítottunk, halványabban sötétítettük. (a) A példában szereplö fa kezdeti állapota. (b) A B beszúrásának az eredménye; ez egy egyszerü eset, egy levélbe kellett beszúrni. (c) Az elözö fába egy Q kulcsot szúrtunk be. Az RSTUV csúcs két részre bomlott, az RS és az UV csúcsokra, a T a gyökércsúcsba ment, és a Q a baloldali új csúcsba (RS-be) került. (d) Az elözö fába egy L kulcsot szúrtunk be. A gyökércsúcsot fel kellett bontani, mivel már telített volt, így a B-fa magassága eggyel nött. Ezután az L kulcsot a JK-t tartalmazó levélbe szúrtuk be. (e) Az elözö fába az F kulcsot szúrtuk be. Az ABCDE csúcsot szétvágtuk, és ezután az F kulcsot a jobboldali új csúcsba (DE-be) szúrtuk be.
Törlés
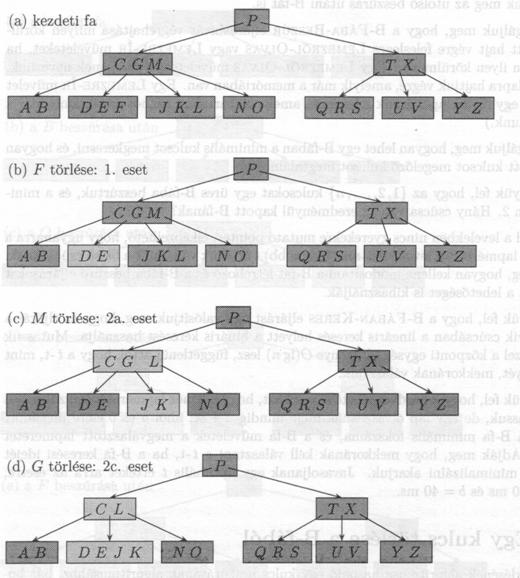
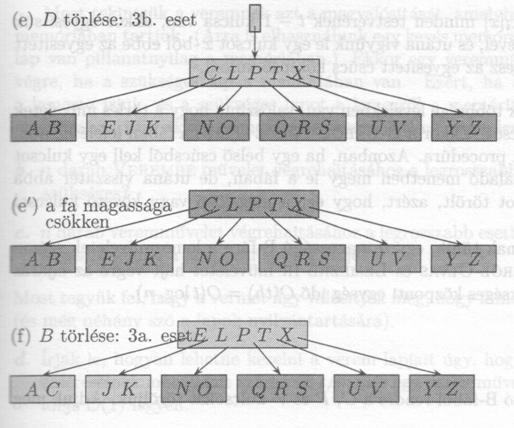
A B-fa minimális fokszáma t = 3, így a csúcsoknak (a gyökércsúcsot kivéve) nem lehet kettönél kevesebb kulcsa. A módosított csúcsokat kevésbé sötétítettük be. (a) A 19.7(e) ábrán látható B-fa. (b) Az F törlése. Ez az leset: egy egyszerü törlés a levélböl. (c) Az M törlése. Ez a 2a. eset: L-t, ami az M megelözöje, felvisszük az M helyére. (d) A G törlése. Ez a 2c. eset: A G-t levisszük, és elkészítjük a DEGJK csúcsot, majd a G-t kitöröljük ebböl a csúcsból. (e) A D törlése. Ez a 3b. eset: a rekurziót nem lehet levinni a CL csúcsba, mivel annak csak 2 kulcsa van, ezért a P-t kell levinni, egyesíteni a CL-t és a TX -et a CLPTX csúcsba; ezután a D törölhetö a levélböl (1. eset). (e') A (d) után a fa gyökércsúcsát töröljük, ezzel a fa magassága eggyel csökken. (f) A B törlése. Ez a 3a. eset: A C elfoglalja a B helyét, E pedig a C pozícióját.
1. Ha a k kulcs az x csúcsban van, és x egy levél, akkor az x kulcsot töröljük az x-böl.
2. Ha a k kulcs az x csúcsban van, és x a fa egy belsö csúcsa, akkor a következöket kell végrehajtani:
3. Ha a k kulcs nincs benne az x belsö csúcsban, akkor határozzuk meg annak a megfelelö részfának a ci[x] gyökércsúcsát, amelyben a k biztosan benne van, ha egyáltalán benne van k a fában. Ha ci[x] -nek csak t - 1 kulcsa van, akkor hajtsuk végre a 3a. vagy a 3b. pontban leírtakat, mivel biztosítani kell azt, hogy annak a csúcsnak, amelyre lelépünk, legalább t kulcsa legyen. Ezután a müveletet az x megfelelö gyerekén rekurzióval befejezhetjük.
Mivel egy B-fában a kulcsok többsége levelekben van, valószínü, hogy a törlés müveletek nagy része levelekböl töröl kulcsot. Ekkor a B-FábóL-TÖRÖL eljárás a fában lefelé haladó, egymenetes, visszalépés nélküli procedúra. Azonban, ha egy belsö csúcsból kell egy kulcsot törölni, az eljárás egy lefelé haladó menetben megy le a fában, de utána visszatér abba a csúcsba, ahonnan egy kulcsot törölt, azért, hogy ezt a megelözö vagy követö kulccsal helyettesítse (2a. és 2b. eset).
11. Dinamikus adatszerkezetek 2. (Gráfok. Ábrázolási módok. Bejárási módszerek. Feszítöfa algoritmusok. Problémák, feloldási lehetöségek.)
Gráf
Csúcsok és élek halmaza: G (V,E)
Lehetnek benne körök (probléma: ezeket nem láthatjuk elöre bejáráskor)
Negatív kör: végtelen ciklusú optimális útkeresés
Típusok: irányított (nyíllal) és irányítatlan, súlyozott (költség) és súlyozatlan
Tipikus gyakorlati példa: úthálózat, térképek
Elöfordulhat, hogy egy súlyozott gráf esetén a rövidebb út nagyobb költséggel jár. Pl. emelkedön kell felmennünk autóval vagy arról közeledik a világvége
Gráfok ábrázolási módjai
A számítógép számára le kell írni a gráfokat (átlátható megjelenítés; zoom, grab lehetösége)
o Szomszédsági lista (láncolt lista)
o Csúcsmátrix
Szomszédsági lista:
![]() irányított gráfnál
csak azt írjuk fel, akit valahonnan el lehet érni
irányított gráfnál
csak azt írjuk fel, akit valahonnan el lehet érni
súlyozott esetén egy költséggel is kiegészítjük a listát
Tárolásra vonatkozó módszerek:
o láncolt lista
o láncolt lista a láncolt listában (minden listaelemböl egy új lista indul, mátrixszerüen)
o Egy tömbbe felvesszük a lista elsö elemeire mutató mutatókat (gyorsabb elérés)
o Tárigény: N db eleje mutató + az élek száma
Elönyök:
o hatékony és tömör tárolás kevés él, sok csúcs esetén
o könnyü eldönteni, hogy két él szomszédos-e
Hátrányok:
o nehéz meghatározni, hogy két tetszöleges pontot összeköt-e él (lineáris keresés, lassú)
 Csúcsmátrix:
Csúcsmátrix:
|
0 |
1 |
0 |
0 |
1 |
|
1 |
0 |
1 |
1 |
0 |
|
0 |
1 |
0 |
1 |
0 |
|
0 |
1 |
1 |
0 |
0 |
|
1 |
0 |
0 |
0 |
0 |
Tulajdonságai:
o irányítatlan gráf esetén a mátrix a föátlóra szimmetrikus
o irányított esetén nem szimmetrikus
Tárolás:
o csak a föátló alatti vagy feletti elemeket kell tárolni
o Súlyozatlan gráf esetén 1 bit elég (igaz / hamis)
o Súlyozott esetén pedig közvetlenül a táblázatba írjuk a súlyokat
o Tárigény: NxN (táblázat)
Elönyök:
o sok él esetén hatékony tárolás
Hátrányok:
o nehéz eldönteni, hogy két él szomszédos-e
Bejárási algoritmusok
Szélességi bejárás
Cél: szélességi sorrendben bejárni a gráfot
o egy kezdöpontból indulva
o a kezdöponttól való távolság függvényében
o minden csúcsot egyszer érintve
Ha a gráf nem összefüggö, egy pontból kiindulva nem érhetö el minden csúcs
Eredménye
o egy fa (összefüggö, körmentes gráf)
o nem egyértelmü, más megoldás is lehet
Algoritmus
Szélességi Keresés (G, s)
![]() Ciklus minden U V [G] - S kezdöpont
minden csúcsra //V[G] : a csúcsok
halmaza
Ciklus minden U V [G] - S kezdöpont
minden csúcsra //V[G] : a csúcsok
halmaza
Szín(U) := fehér
D(U) := végtelen //a kezdöponttól való távolság
p (U) := NIL //az elözö elemet jelenti: ahonnan jöttünk
D(S) := 0 //a kezdöpont
p (S) := NIL //a kezdöpont elött nincs senki
Q := //FIFO adatszerkezet
![]() Ciklus amíg Q nem
üres
Ciklus amíg Q nem
üres
U := ElsöElem (Q)
Ciklus minden V Szomszéd(U) //U minden szomszédjára
Ha (Szín (V) = fehér)
Akkor
Szín (V) := szürke
d(V) := d(U) +1
p(V) := U //a V csúcsba az U-ból jöttünk
SORBA (Q, V) //'Szín(S) := szürke' nem kell, mivel a végén fekete lesz, addig nem bántjuk
elágazás vége
Ciklus vége
SORBÓL (Q) //kivesszük az elsö elemet a sorból,
Szín (Q) := fekete // mivel a fenti ciklus már feldolgozta
Ciklus vége
Ciklus vége
Szélességi keresés vége
Magyarázat
o Fehér: olyan csúcs, amelyet még nem érintettünk
o Szürke: olyan csúcs, amelyet már érintettünk, de van olyan szomszédja, amit még nem
o Fekete: minden szomszédját és öt magát is feldolgoztuk
o Lehet, hogy maradt fehér, de amit valaha elértünk, az fekete lett
Útkiíró eljárás: (Egy láncolt lista fordított sorrendü kiíratása, eredménye egy erdö)
o Az összes p elsöbbségi listához helyes megoldást ad.
Eljárás UtKiir (G, S, V) //két csúcs között megtalálja az utat
Ha (V = S) akkor Print S //végeztünk, megállási feltétel
Különben Ha (p (V) = nil) akkor Print "nincs út S és V között" //megállási feltétel
Különben
UtKiir(G, S p(V))
Print V
különben vége
Különben vége
UtKiir vége
Mélységi bejárás
o d(U): U elérési ideje; ezen idöpont elött a csúcs színe fehér
o f(U):
o U elhagyásának ideje
o D(U) és f(U) között a csúcs színe szürke
o F(U) után a csúcs színe fekete
MK (G) //MK : mélységi keresés, G : gráf
Ciklus minden U V (G) csúcsra
Szín (U) := fehér //nem elöd fa, hanem diszjunkt fák
p (U) := NIL
idö := 0 //az elérés, illetve az elhagyás ideje
Ciklus vége
Ciklus minden U V (G) csúcsra
Ha szín(U) = fehér akkor MK Bejár (U)
Elágazás vége
Ciklus vége
Eljárás vége
Bejáró eljárás:
MK Bejár (U)
Szín (U) := szürke
d(U) := idö; //most értük el, az elérés idöpontja
idö := idö +1
Ciklus minden V Szomszéd(U)-ra
Ha (szín (U) = fehér)
akkor
p (V) := U
MK Bejár (V) //itt addig elöáll egy újabb fa, amíg minden fekete nem lesz (erdö)
Elágazás vége
Ciklus vége
Szín (U) := fekete
f(U) := idö; //most hagyjuk el
idö := idö + 1
eljárás vége
Feszítöfa algoritmusok
Minimális feszítöfák
Adott egy G irányítatlan, összefüggö, súlyozott gráf. A G gráf egy feszítöfája tartalmazza G összes csúcsát, valamint az élek egy olyan részhalmazát, amelyre teljesül az, hogy a keletkezö gráf összefüggö, és nem tartalmaz kört. Nyilvánvalóan ilyen fából több is lehet. A minimális feszítöfa probléma az, hogy meg kell találni a minimális összsúlyú feszítöfát. Ha súlyozatlan gráfról van, akkor nyilván mindegyik feszítöfa összsúlya ugyanakkora, mégpedig V-1. Tehát ezentúl feltesszük azt, hogy a gráf súlyozott.
A minimális feszítöfa növelése:
A minimális feszítöfa algoritmusok mohó jellegüek. Az algoritmus müködés közben mindig az egyik minimális feszítöfa egy részét tartja nyilván. Ezt a feszítöfát nyilván elöre nem ismerjük, viszont egy tétel alapján biztosak lehetünk abban, hogy ez valóban minimális feszítöfa. Minden lépésben meghatározunk egy (u,v) élt, amely még nem része az aktuális feszítöfa-kezdeménynek, viszont ha hozzávesszük, akkor továbbra is teljesülni fog az, hogy van olyan minimális feszítöfa, amelynek része a most keletkezett fa. Az ilyen élt biztonságos élnek nevezzük, mivel a feszítöfa-kezdeményhez hozzávéve továbbra is feszítöfa-kezdemény marad, nem rontja el azt.
Algoritmus:
MFF()A biztonságos (u,v) él keresésekor ilyen él biztosan létezik, mivel feltétel az volt, hogy A része egy minimális feszítöfának. Az algoritmus legérdekesebb része, hogy hogyan ismerjük fel a biztonságos éleket, és hogyan találunk egy ilyet hatékonyan.
A Kruskal algoritmus
Egy erdöt fogunk addig élekkel bövíteni, amíg fát nem kapunk. Alapból a gráf minden egyes pontja külön fát alkot, tehát nincs él az erdöben. A föciklus minden egyes lépésében kiválasztjuk a legkisebb súlyú olyan élet, amely két különbözö fát köt össze. Ehhez könnyedén találunk olyan vágást, amely kielégíti a tétel feltételeit, tehát az biztonságos él lesz. Ezért ezzel az éllel bövítjük az erdöt. Ezt addig ismételjük, amíg kész nem lesz a fa.
Kruskal(G) //G egy n szögpontú, súlyozott, irányítatlan gráf
T :=
Ciklus i:=1-töl n-1-ig
e :=
T := T u //T a minimális feszítöfa
Ciklus vége
Kruskal vége
Példa
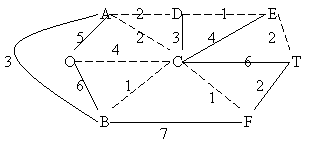 Induljunk az egyik legkisebb
súlyú élböl (tetszöleges):
Induljunk az egyik legkisebb
súlyú élböl (tetszöleges):
1. BC=1
2. DE=1
3. CF=1
4. AD=2
5. ET=2
6. AC=2 (A és C külön halmazból valók, ezért nem alakul ki kör)
7. FT=2, AB=3, DC=3, EC=4 (kör alakulna ki)
OC=4 (jó, készen van)
A Prim algoritmus
Ebben az esetben egy fát bövítünk addig, amíg nem kapjuk meg az eredeti gráf egy feszítöfáját. Egy tetszöleges pontból indulunk ki; kezdetben csak ebböl az egy pontból fog állni a fa.
Prim(G) //G egy n szögpontú, súlyozott, irányítatlan gráf
T :=
Ciklus i := 1-töl n-2-ig
e :=
T := T u
Ciklus vége
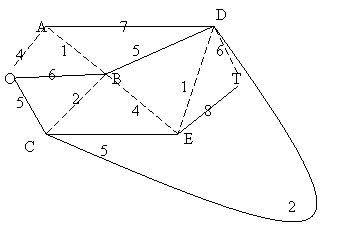 Példa
Példa

12. Konvencionális rejtjelrendszerek (Caesar. Vigenere. Egyszerü helyettesítés. A módszerek ismertetése és fejtésük)
Alapja egy táblázat, amely esetében máig megoldatlan, hogy hányféleképpen lehet kitölteni. Minden sorban egy betü csak egyszer szerepelhet
A nyílt üzenetünk és az ismétlödö kulcs egyes betüi határozzák meg a megfelelö titkosított betüt. Ezt minden karakterpárra elvégezve adódik a titkosított üzenet:
|
|
A |
B |
C |
D |
|
A |
B |
C |
D |
A |
|
B |
C |
D |
A |
B |
|
C |
D |
A |
B |
C |
|
D |
A |
B |
C |
D |
o k betüs: 26k
Ha a rejtett üzenetben két ugyanolyan betüt látunk, az nem feltétlenül ugyanazt a betüt jelenti a nyílt üzenetben (lásd a példát).
Se a betügyakoriságot, se a szógyakoriságot nem tartja meg
A kulcs mérete nagyon fontos. Az egy-egy megfeleltetést a kulcs elrontja. A betük rákövetkezése is sérül
Tegyük fel, hogy tudjuk kulcs hosszát. Így feloszthatjuk a titkosított szöveget kulcshossznyi részekre. Ezekben az egyes betük ugyanahhoz a kulcsbetühöz kell, hogy tartozzanak. A gyakoriságvizsgálatot ezekre az i-edik elemekre végezzük úgy, mint a Caesar módszernél. A módszer ismét a próbálgatás, de most nincs olyan sok lehetöség.
Betügyakoriság-vizsgálatot végzünk minden i-edik betüre. Ha nem találjuk el a jelszót, akkor egyenletes eloszlást kapunk. Ha eltaláljuk, nem egyenletes az eloszlás.
Az XOR használatára rá lehet jönni, de ha táblázattal alkalmazzuk, akkor sokkal nehezebben törhetö
A Brute-force gyakorlatilag nem alkalmazható, mert
o nagy számításigény (k kulcs)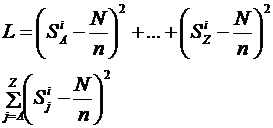 N: az üzenet teljes hossza, n a lehetséges karakterek száma, míg SA a szövegben elöforduló 'A' karakterek számát jelöli.
N: az üzenet teljes hossza, n a lehetséges karakterek száma, míg SA a szövegben elöforduló 'A' karakterek számát jelöli. Egyszerü helyettesítés
Minden nyílt betünek megfelel egy rejtjeles
Olyan, mint a transzpozíciós, csak a kulcshossz 256 (vagy 26)
Törése:
o Az elsö néhány statisztikailag biztos betü (szóköz, e, t, a) meghatározása
o Szótár alapján az olyan szavak keresése, amelyekben az imént megtalált betük adott helyen vannak
o Pl. a statisztika után elöállt egy félig dekódolt szó: _ A T A _ A _ _
o A szótárból kikeressük az összes olyan 9-betüs szót, amelyikben a második, negyedik, hetedik helyen A áll, a harmadikon T, stb.
o Az ilyen szavakból egyet ráillesztünk, majd megyünk tovább, hiszen felfedtünk megint egy pár új betüt.
o Ha rossz szót illesztettünk rá, egy idö után kiderül. Ekkor backtrack.
Törése 2:
o Mint a transzpozíciós esetében, betürákövetkezéssel, 256 (26) kulcshosszal
13. Elméletileg fejthetetlen titkosítási módszerek (Elméleti alapok. A Vernam módszerek ismertetése és kritikai elemzése.)
Az eredmény eloszlása is egyenletes lesz, mivel mindig véletlennyivel toljuk el a karaktereket
Ez a módszer elméletileg törhetetlen, mivel irreálisan nagy számítógép-kapacitás birtokában sem fejthetö meg
Gyakorlati titkosság: irreálisan nagy számítógép-kapacitás birtokában megfejthetö (Pl. Vigenere-módszer)
Törés: nincs módszer arra, hogy az elöállt 'tört' üzenetek sorozatából kiválasszuk azt, amelyik ténylegesen elhangzott
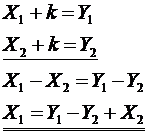 Ha a titkosító elmondja, amit egyszer már titkosítottak,
Ha a titkosító elmondja, amit egyszer már titkosítottak,Hogyan lehet rájönni, hogy ugyanaz a kulcs?
|
|
|
|
|
|
|
X1 |
|
A |
|
|
|
|
|
|
|
|
|
X2 |
|
A |
|
|
|
|
|
|
|
|
|
Y1 |
|
Q |
|
|
|
|
|
|
|
|
|
Y2 |
|
Q |
|
|
|
|
|
|
|
|
Ha több üzenetet fogunk el, az esélyünk megnö, a kétirányú kiterjesztés az eddigi érthetetlen részeket értelmezheti
Kivéve, ha az üzenetekböl egyik-másik szándékosan zagyvaság
Invariáns tulajdonság, amit megtart ez a módszer: a betük egymás alattiságát. Ha a nyílt üzenetekben egy adott pozíción ugyanaz a betü volt, akkor a kulcs ugyanannyiadik karakterét adjuk hozzá, így az eredmény is ugyanaz lesz.
X1, X2 értelmes szövegek. Ha nem ugyanaz a kulcs, egyenletes eloszlást kapunk.
Annak is van valószínüsége az adott nyelvben, hogy egy adott pozíción milyen betü van.
A két dolog összefügg: betügyakoriság, és az egymás után következöség
![]() Adott pozícióban A
betüböl P(A) darab van. Annak a valószínüsége is mérhetö,
hogy X1-ben és X2-ben ugyanazon a helyen ugyanaz a
betü van. P(A)2.
Adott pozícióban A
betüböl P(A) darab van. Annak a valószínüsége is mérhetö,
hogy X1-ben és X2-ben ugyanazon a helyen ugyanaz a
betü van. P(A)2.
Tökéletes titkosítás
Ha a nyílt és a rejtett üzenet kölcsönös információja nulla, vagyis semmilyen kapcsolat sincs a kettö között; és ez bizonyítható is. Ilyen a 'one time pad' módszer.
![]()
Meg kell adnunk, hogy a rejtett üzenet hányféle forrásból keletkezhetett, különbözö kulcsok felhasználásával. Ha k1.kn kulcsokkal megyünk végig, akkor különbözö E(x2, k2) állítja elö az y-t.
A λ szemszögéböl olyan rejtjelrendszer jó, ami az y-okra sok x-et ad meg. Ekkor a Brute Force nehezen használható.
Probléma: egy konkrét y-tól függ. Akkor jó a rejtjelrendszer, ha a legkisebb lambdája is nagy. Ez a függvény nehezen számolható. Koordinátarendszerben ábrázolva nagyon változó függvény keletkezik.
Akkor nem jó, ha például egy-egy megfeleltetés van.
Egyértelmüségi pont:
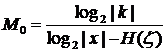 ,
,
o Ahol log2|K| a kulcshalmaz elemszáma, log2|x| a nyílt halmaz elemszáma (abc) és H(ξ) a forrásentrópia (a nyelvre jellemzö érték)
o M0 azt mondja meg, hogy az üzenet elméletileg hány karakterig fejthetetlen. De ez nem azt jelenti, hogy ennél hosszabb már megfejthetö.
o Pl. Caesar módszer esetén: 26 lehetséges eltolási érték és 2 karakter hosszú üzenet esetén nem garantált a fejthetetlenség. (H(ξ)=13)
o Amikor egy betünek pontosan egy másik felel meg, akkor 26! lehetséges kulcs van. Kiszámolva kb. 230 karakter alatt nem fejthetö.
Transzpozíciós titkosítás esetén:
|
|
N |
10 |
50 |
|
|
|
M0 |
6,4 |
70 |
|
Véletlen átkulcsolás módszere esetén: az üzenetnél hosszabb üzenet sem lenne fejthetö. (H(ξ)=1,3)
14. DES (Shannon keverö transzformációja. A DES módszer ismertetése és kritikai elemzése.)
DES (Data Encryption System, 1977, IBM)
56 bites kulcs, 256 kulcsméret
64 bites üzenet -> 64 bites üzenet
A DES gyorsan számolható, ezért célszámítógépeket készítettek hozzá. Korábban ez volt az elönye, ma ez már hátránynak tekinthetö.
Algoritmus (19 lépés):
o 1. Felcserélés (a középen kettévágott üzenet 32 bites részeinek felcserélése)
o 2. Lavina-hatás (Xleft XOR f(XRi, Ki))
o 3..17
o 18, 19 felcserélés
Az f függvény müködése
a) 32 bit kiterjesztése 48 bitre
b) 48 bit XOR kulcs
c) 8 db, egyenként 6 bites részre bontja az üzenetet, s ezeket egy S dobozba vezeti. S-böl 4 bit jön ki.
d) 8 x 4 bit = 32 bit
Az S doboz müködése szorosan összekapcsolódik a kiterjesztéssel, de pontos leírása titkos
1 millió dolláros célgéppel pár óra alatt törhetö
3DES = 112 bit
Produkciós titkosítónak az olyan titkosító eszközöket nevezzük, amelyek kettö vagy több eltérö elvü müvelet kombinálásával szolgáltatják eredményüket. Ezek az algoritmusok nagyobb biztonságot kínálnak, mint müveleteik külön-külön. Ha azonos elvüeket kötünk sorba, elöfordulhat, hogy azok egymás hatását kioltják (OTP azonos kulccsal), vagy csak feldolgozási idöt, a biztonságot nem növelik.
Egyik speciális eset a helyettesítö-keverö hálózat, mely helyettesítéseket (S-doboz) és keveréseket (P-doboz) végez egymás után.
A lavinahatás megvalósítását a kiterjesztés lépése biztosítja: ez a bemeneti 32 bitböl 48-at készít úgy, hogy 16 kiválasztott bitet lemásol és megdupláz. Ebböl következik, hogy ha a függvény bemenetén változás történik, az két helyen is kifejti hatását. A kiválasztott bitek úgy helyezkednek el, hogy egy-egy ilyen duplázott bit kettö S-doboz bemenetére megy.
Összefoglalás
Maga a szabvány a DES (Data Encryption Standard) nevet viseli; ez a betüszó terjedt el a módszer egészére vonatkozóan annak ellenére, hogy az algoritmusnak a szabványban más neve van (DEA). Az alapvetö elvárások az algoritmussal szemben a következök voltak:
Nyújtson magas szintü biztonságot
Egyszerü felépítésü, könnyen érthetö legyen
A biztonság csak a kulcstól függjön, ne az algoritmustól
Gazdaságosan alkalmazható legyen elektronikus eszközökben is (hardveres úton)
A fentiek tükrében eredetileg kitüzött 128 bites kulcs- és blokkméretet az NSA (National Security Agency) lecsökkenttette 64 bitre sokak szerint azért, hogy az így titkosított üzeneteket az USA nemzetbiztonsági hivatala még fel tudja törni, de más szervezet már ne. A végsö kulcsméret további 8 bit ellenörzési célokra történö lefoglalását követöen 56 bit lett, amellyel gyakorlatilag az eredeti kulcstér 99%-át eldobták.
Az algoritmust 1975-ben hozták nyilvánosságra, s hamarosan nagyon gyors hardveres implementációk is megjelentek, ezért széles körben elterjedt a polgári élet minden területén. Érdekes, hogy minösített adatok védelmére már akkor sem ajánlotta az amerikai kormányzat.
A DES algoritmus müködése nagy vonalakban:
Az elsö lépésben a kulcstól függetlenül a 64 bites bemenet bitjeit összekeveri
Az iterációs lépések mindegyike két darab 32 bites értékként értelmezi a bementére adott adatot, s ennek megfelelöen két darab 32 bites kimenetet ad
Az utolsó elötti lépésben a két 32 bites részt felcseréli
A maradék 16 lépés müködése egységes és mindegyik paramétere, a kulcsból származtatott érték, a körkulcs (Ki)
A DES napjainkig a kriptográfusok egyik kedvenc témája. Elvi módot ugyan nem sikerült találni a feltöréshez, azonban 1990-ben az Eli Biham és Adi Shamir által bevezetett differenciális kriptoanalízis segítségével a DES feltöréséhez szükséges 255 brute-force müveletigényét 238 müvelet körülire csökkentették [2].
Megjelenésekor a DES ereje pont abban rejlett, hogy célhardverrel gyorsan megvalósítható volt. Ma már ez hátránynak tekinthetö, hiszen elég, ha 1998-ban Michael Wiener által kifejlesztett Deep Crack DES törö célgépre gondolunk.
A mai elérhetö technológia segítségével a DES egy 1 millió dolláros célgéppel mintegy 1 óra alatt feltörhetö.
15. Nyilvános kulcsú titkosítás (Alapelv. RSA módszer. Hitelesítési lehetöségek. Nagy prímszámok.)
A nyilvános kulcsú rendszerekben minden résztvevö két kulcsot birtokol: egy nyilvános kulcsot és egy titkos kulcsot. Az üzenetet a titkos kulccsal lehet megfejteni, amennyiben a nyilvános kulccsal kódolták, és fordítva. Ennek tükrében a rejtjelezett üzenetet csak az tudja elolvasni, akinek birtokában van a titkos kulcs - vonatkozik ez a feladóra is, ha visszakapja az eredetileg általa elküldött üzenetet.
A nyilvános kulcsú titkosításokat hitelesítésre is használhatjuk, kiaknázva azon tulajdonságukat, hogy a titkosító algoritmus müködik a nyilvános kulccsal, illetve a megfejtö algoritmus is müködik a titkos kulccsal. A címzett a következöképpen tudja ellenörizni az üzenet küldöjét:
1. Küldés elött a feladó a saját titkos kulcsával kódolja az üzenetet. Ezzel olyan átalakítást végez az üzeneten, amire senki más nem képes.
2. A következö lépésben az elöbbi eredményt titkosítja a címzett nyilvános kulcsával, ezzel elérve, hogy az üzenet ne utazzon védtelenül.
3. A címzett saját kulcsával és a megfejtö algoritmussal kibontja a csomagot, feloldva ezzel az üzenet védelmét.
4. A kapott eredményt pedig a küldö nyilvános kulcsával alakíthatja olvasható, kódolatlan formára.
A fenti folyamat során a feladó biztos lehet abban, hogy az általa elküldött csomagot csak a címzett képes elolvasni, hiszen az mindig védve utazott. A címzett pedig biztos lehet abban, hogy az üzenet valóban a feladótól érkezett, hiszen a feladó titkos kulcsával kódolt üzenetet egyedül a nyilvános kulcs nyitja.
Mivel a publikus kulcsokat egyáltalán nem kell védeni, létrehozhatunk egy nyilvános, telefonkönyvhöz hasonló kulcstárat, amely a résztvevök nyilvános kulcsait tartalmazza (n darabot). Így bárki tud üzenetet küldeni a kulcstárban szereplöknek, minden elözetes egyeztetés nélkül. A kulcstárból ugyanezzel a módszerrel juthatunk hozzá a kívánt résztvevö nyilvános kulcsához: a szerver aláírja saját titkos kulcsával a "kulcsot", mi pedig a szerver nyilvános kulcsával bizonyosodunk meg az üzenet hitelességéröl.
Ezeket a lekért publikus kulcsokat a helyi gépünkön is tárolhatjuk, egyedül arra kell ügyelnünk, hogy a helyi adatok mindig szinkronban legyenek a szerveren tároltakkal [2].
A nyilvános kulcsot használó módszerek gyakran a nagy prímszámok szorzásán, s az így létrejövö még nagyobb szám prímtényezökre bontásának nehézségén alapulnak. Az RSA biztonságát is ez a probléma adja.
A kis Fermat-tétel kimondja, hogy ha egy a számot egy p prímhatványra emelünk, akkor az eredmény p-vel való osztás utáni maradékaként visszakapjuk az eredeti a számot. Ez természetesen csak akkor müködik, ha p nagyobb, mint a, különben az osztás során a-t is elosztanánk, s más maradékot kapnánk.
A fenti tétel általánosabb formáját Euler fogalmazta meg, miszerint:
![]() ,
,
ha a és n relatív prímek, azaz nincs más osztójuk, csak és kizárólag az 1. Ha az n helyére prímszámot választunk, akkor egyértelmüen adódik a
![]()
összefüggés, hiszen egy prímszámhoz minden más szám relatív prím. Prímszámot választani azért is elönyös, mivel ilyen esetben minden n-nél kisebb számra müködik a tétel.
Ahhoz azonban, hogy több felhasználó számára is lehetövé váljon a rendszer használata, n-t két prímszám szorzataként érdemes definiálni (p és q). Így az új modulus n = pq, a kitevö pedig ed = k(p-1)(q-1)+1. Ekkor azt kapjuk, hogy
![]() , ahol
, ahol
![]() .
.
Legyen a nyilvános kulcs az (e, n) számpáros, a titkos kulcs pedig a (d, n) páros. Ekkor a támadónak Ф(n) kiszámolásához n prímtényezös felbontására lenne szüksége, azaz p-re és q-ra. Mi azonban ezt a két számot úgy választjuk meg, hogy n hatalmas legyen, majd eldobjuk az elöállításhoz szükséges számokat. A tudomány mai állása szerint egy ekkora szám prímtényezös felbontása reménytelen feladat [2].
A titkosításhoz az üzenetet elöször számokká alakítjuk úgy, hogy a számok (blokkok) mindegyike kisebb legyen, mint n. Ezt például úgy tehetjük meg, hogy minden karakter helyére az ASCII kódját írjuk, majd átszámítjuk egy másik számrendszerbe. Az így nyert üzenetdarabokat a képletünkben az a helyére helyettesítjük be, majd az egyes m számokból (üzenetekböl) az
![]()
képlettel elöállítjuk a rejtjelezett M üzenetet, ami az
![]()
képlet alapján lehet megfejteni.
Az algoritmus elnevezése a tervezök nevének elsö betüit örzi: Rivest, Shamir, Adleman. Az RSA algoritmust 1977-ben szabadalmaztatták, azonban ez a védelem 2000-ben lejárt, így bárki liszenszdíj-mentesen készíthet RSA algoritmuson alapuló hardver- vagy szoftvereszközt.
A kulcsgenerálás lépései tehát a következök:
1.) Véletlenszerüen válasszunk két elég nagy, legalább 100 jegyü prímszámot. Legyen ez P és Q.
2.) Ekkor N = PQ és Ф(n) = (P-1)(Q-1)
3.) Válasszunk egy véletlen E számot úgy, hogy relatív prím legyen Ф(n)-re.
4.) Keressünk egy olyan D-t, amelyre ED = 1 mod Ф(n) teljesül.
Egy példán keresztül illusztrálva pedig:
1.) Legyen ez P = 17 és Q = 23.
2.) Ekkor N = PQ = 391 és Ф(n) = (P-1)(Q-1) = 352
3.) Legyen E = 21. Ekkor (21, 352) = 1 teljesül.
4.) Legyen D = 285, mert 285 x 21 mod 352 = 1.
5.) Az elküldendö üzenet legyen "T", amelynek az ASCII kódja 84. Ez kisebb, mint 391, ezért megfelelö.
6.) A titkosított üzenet így: 8421 mod 391 = 135. Ezt kell elküldeni.
7.) A fogadó oldalon pedig a 135285 mod 391 = 84 számítással áll elö az eredeti üzenet.
A példában használt értékek a gyakorlatban természetesen nem alkalmazhatók, mivel az N számot még fejben is gyorsan prímtényezökre lehet bontani. Ezután pedig elöállítható Ф(n), majd inverzszámítással D is. Ha azonban két többszáz-jegyü prímszámot választunk, akkor az elöálló N prímtényezös felbontása a mai eszközökkel lehetetlen feladat [2].
Az RSA a DES-hez hasonló blokkos titkosító algoritmus, a blokkok méretét n határozza meg. Az algoritmusban E és D szerepe felcserélhetö, ezért az RSA alkalmas digitális aláírásra is. A gyakorlati alkalmazások során jelenleg a 2048-4096 bites modulosokat tekintjük biztonságosnak. Az RSA kulcsainak hosszát mindig a modulus n hossza határozza meg, hiszen n adja meg a feltörés bonyolultságát. A faktorizáció területén elért újabb eredmények (elliptikus görbe faktorizáció) miatt ajánlott közel azonos méretü prímszámokat felhasználni a kulcsok generálásához: például egy 1024 bites modulust célszerü két 512 bites prím alapján kiszámolni. Azonban vigyázni kell arra is, hogy a két szám ne kerüljön túl közel egymáshoz [2].
Az RSA algoritmus elleni támadások hatékonyságát sokak szerint növelheti az, ha a kulcs speciális tulajdonságokkal rendelkezik. Ilyen feltétel lehet, hogy a 23. bit a kulcsban "0", vagy az utolsó 5 bit "1' értékü legyen. Ezeket a kulcsokat gyenge kulcsoknak is nevezik (weak key). A támadó ekkor viszont egy feltételezésen alapuló megoldással próbálkozik, amely könnyen kudarcba fulladhat.
Számos vizsgálat eredményeképpen a prímeknek (P és Q) a következö tulajdonságokkal kell rendelkezniük akkor, ha erösek akarnak lenni (strong key) [4]:
1.) A választott prím (R) nagy, legalább 400-500 bit hosszú
2.) R - 1 legnagyobb prímosztója (R-) nagy
3.) R- - 1 legnagyobb prímosztója (R- -) nagy
4.) R + 1 legnagyobb prímosztója nagy
A fö érv az erös prímek használatára Pollard faktorizáló algoritmusa volt, ezért az 1970-es évektöl jó darabig a gyenge prímekböl elöállított RSA kulcsokat gyenge kulcsoknak tekintették, használatukat nem javasolták. 1985-ben azonban Lenstra kidolgozott egy olyan, elliptikus görbén alakuló eljárást, amely erös prímek használata esetén is ugyanolyan hatékony, egyedül a prímszámok közel egyforma hosszúsága okoz neki problémát. Rivest és Silverman mindezt egy 1998-ban publikált közös tanulmányukban foglalták össze [4]. Egyúttal megmutatták, hogy az erös prímek használata felesleges, mert alkalmazásuk véd ugyan bizonyos faktorizálási módszerek és az iteratív támadás ellen, de nem véd azok általánosítása, Lenstra módszere ellen. Használatuk tehát nem baj, de nem is szükséges [2].
Az RSA feltöréséhez nem érdemes a brute-force módszerrel nekifogni, mivel már az elavultnak tekinthetö 512 bites kulcsméret is kellö védelmet nyújt ellene. Ugyanezt a számot prímtényezökre bontani azonban lényegesen könnyebb - de szintén nagyon eröforrás-igényes feladat. Az idök folyamán az egyes új módszerek és egyre gyorsuló számítógépek jelentös haladást tettek lehetövé a faktorizálás terén. Érdekes, hogy a feltört RSA kulcsok hossza és az eltelt évek között nagyjából lineáris kapcsolat van, ami valószínüleg annak köszönhetö, hogy a számítási teljesítmény és az egyre nagyobb számok faktorizálásának eröforrás-igénye egyaránt exponenciálisan növekszik [2].
Az RSA Laboratories által meghirdetett RSA Factoring Challenge keretében 2005. május 10-én vált nyilvánossá a legutóbbi, 200 digit hosszú szám sikeres faktorizálása [5]. Íme a versengés tárgya, a 200 digit hosszú RSA kulcs:
2799783391 1221327870 8294676387 2260162107 0446786955 4285375600 0992932612 8400107609 3456710529 5536085606 1822351910 9513657886 3710595448 2006576775 0985805576 1357909873 4950144178 8631789462 9518723786 9221823983
A fenti szám lényegesen kisebb a legnagyobb ismert prímszámtól, amely 9 152 052 digit hosszú, s a neve Mersenne-prím (M43) [1]. Ebböl is látszik, hogy egy számról lényegesen könnyebb eldönteni, hogy prím-e, mint faktorizálni. [5]
Bruce Schneier az egyik Cryptogram hírlevelében arról ír, hogy az 1024 bites RSA kulcsok egy 1 milliárd dolláros Bernstein-féle architektúrán alapuló célgéppel már néhány perc alatt faktorizálhatók. Ez nem is tünik olyan horribilis összegnek annak fényében, hogy az USA által rendszeresen fellött Sigint müholdak ára a 2 milliárd dollárhoz közelít. Ha Bernstein gépét megépítik, az összes népszerü protokoll, amely ma leginkább 1024 bites RSA kulcsokat használ (HTTPS, SSH, IPsec, PGP), mind kompromittálódik.
A legtöbb neves kriptográfus szerint a fentiek miatt érdemes a rendszereinket átállítani a 2048 bites kulcsok használatára, hiszen nem tudhatjuk, hogy az NSA megépíttette-e már a Bernstein-féle gépet. A digitális szatellit-adásokat nem véletlenül védik már 4096 bites RSA kulcsok Európában. [6]
A nyilvános kulcsú algoritmusok gyakorlati alkalmazása során nem az egész üzenetet kódolják például az RSA-val, mert nagyon lassú lenne. A hagyományos szimmetrikus kulcsú algoritmusok hardvermegoldásban átlagosan ezerszer gyorsabbak, de szoftveres megoldás esetén is legalább százszor [7]. Ezért az aszimmetrikus titkosítások nem alkalmasak hosszú üzenetek titkosítására. A szokásos eljárás az, hogy az üzenetet egy gyorsabb, titkos kulcsú algoritmussal, az ehhez használt kulcsot pedig nyilvános kulcsú módszerrel titkosítják, és a kettöt együtt küldik el. Ez az egyszer használt kulcs a viszonykulcs (session key). Így dolgozik a PGP is: az RSA segítségével titkosítja a szimmetrikus kulcsot, majd a tömörített üzenet tényleges kódolása az IDEA/CAST algoritmussal történik. A tömörítés nemcsak az átviteli idöt csökkenti, de lényegesen megnehezíti a mintakeresést, növeli az entrópiát és elrejti a nyílt szöveg jellemzö tulajdonságait.
A fenti borítékolásnak (enveloping) is nevezett módszernek azonban van egy igen nagy hátránya: a nyilvános kulcs hosszából származó elöny, ami eddig a brute-force alkalmazását megakadályozta, elveszik. A támadó egyszerüen úgy kezeli a titkosított üzenetet, mintha az egész szimmetrikus kulcsú algoritmussal lenne kódolva, hiszen itt most a nyilvános kulcsú algoritmus csak a kulcscserét segíti [2].
Mindezek fényében a hibrid kriptorendszerek biztonságát az alkalmazott szimmetrikus kulcsú algoritmus, és az aszimmetrikus kulcsú algoritmus együttesen határozzák meg.
Az RSA algoritmus alapját a hatalmas prímszámok adják, így nyilvánvaló a szükséglet ilyen prímek elöállítására vonatkozóan. Azonban jelenleg nem áll rendelkezésünkre olyan módszer, amely közvetlen módon lehetne meghatározni egy prímszámot, ezért az egyetlen esélyünk, hogy véletlenszerüen generálunk egy nagy számot, majd megnézzük, hogy prím-e. Ha viszont egy tetszöleges számról kell eldöntenünk, hogy prím-e, akkor egyetlen teljes biztonságos jelentö módszer adódik: végig kell néznünk az 1 és a szám négyzetgyöke közötti egész számok mindegyikét, hogy nem-e osztója a számunknak. Ezt a sorozatos osztást természetesen nem tudjuk elvégezni, még az erasztothenészi szita segítségével sem, hiszen pontosan ennek megakadályozása a célja a hatalmas prímek alkalmazásának.
Az egyetlen megoldásként a prímteszt algoritmusok kínálkoznak, amelyek tetszöleges biztonságú becslést képesek szolgáltatni arra vonatkozóan, hogy a vizsgált szám prím-e. Ilyen teszt a Fermat-teszt és a Solovay-Strassen-teszt, de jelenleg a legbiztosabb a Miller-Rabin-teszt. Ha ezen a teszten a vizsgált szám százszor átmegy, akkor a szám már kellöen összetett, ha nem is biztosan prím [2].
Bármelyik tesztet választjuk is, mindenképpen hatalmas számokon kell aritmetikai müveleteket elvégeznünk, ami természetesen a jelenleg elterjedt 32 bites, általános célú processzorokkal nem oldható meg adattípus-szinten. Így, ha ezen algoritmusok megvalósítására adjuk a fejünket, kénytelenek vagyunk egy ALU-t (Arithmetical Logical Unit) készíteni az általunk alkalmazott programozási nyelven, amely egy karaktersorozatot számként értelmezve blokkosan képes a müveletek elvégzésére. Olyan ez, mint az általános iskolai matematika: a nagy számok összeadásához kisebb számokra kell bontanunk azokat, helyértékenként összeadnunk, majd a maradékot (átvitelt) kezelnünk.
Összefoglalás
Nyilvános kulcsú titkosítások
Alapötlet: használjunk két kulcsot. Az egyik a nyilvános (KN), a másik a titkos kulcs (KT).
Létrehozunk egy nyilvános kulcstárat, ami a nyilvános kulcsokat és tulajdonosaikat tartalmazza: [A, KN] [B, KN]. Ez csak olvasható lehet; illetve hatékonyan védeni kell.
Módszer: a megfejtéshez és a titkosításhoz különbözö kulcsra van szükség (Encryption, Decryption)
Probléma: B nem tudja eldönteni, hogy az üzenetet kitöl érkezett, mert bárki kikeresheti a nyilvános kulcsot a kulcstárból, és ezzel küldhet üzenetet B-nek.
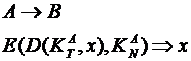 Digitális aláírás: a titkos kulcsban
elhelyezünk egy hitelesítésre alkalmas lenyomatot.
A hitelesség igazolása: a titkos kulcsot csak A tudja, ezért biztos, hogy
az üzenet töle érkezett. Ha az X elöáll a képlettel, akkor az üzenet A-tól
jött (kivéve, ha ellopták a titkos kulcsát a gépéröl). A nyilvános
kulcsokat ki kell cserélni, a titkos kulcs viszont a gépen maradhat.
Digitális aláírás: a titkos kulcsban
elhelyezünk egy hitelesítésre alkalmas lenyomatot.
A hitelesség igazolása: a titkos kulcsot csak A tudja, ezért biztos, hogy
az üzenet töle érkezett. Ha az X elöáll a képlettel, akkor az üzenet A-tól
jött (kivéve, ha ellopták a titkos kulcsát a gépéröl). A nyilvános
kulcsokat ki kell cserélni, a titkos kulcs viszont a gépen maradhat.
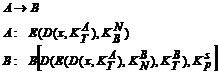
Rivest-Shamir-Adleman (RSA) titkosítás
Lépései:
1. Kulcsválasztás
a. Véletlenszerüen választunk P1, P2 prímszámokat, amelyek elég nagyok (~100+ jegyü)
b. M = P1 * P2 és O(m)=(P1-1)(P2-1). Válasszunk egy véletlen e számot, ami relatív prím a [(P1-1), (P2-1)] pároshoz.
c. e * d = 1 mod O(m), ahol 1 ≤ d ≤ O(m)
2. Központi nyilvántartás
a. Betesszük KN(m,e)-t a nyilvános kulcstárba
b. Az összes többit is: d, m, P1, P2, O(m)
3. Rejtjelezö algoritmus
a. A -> B(eB, mB)
b. Elökódolja az üzenetet, Pl. ASCII kódok segítségével betükböl számokat csinál, ezeket pedig átszámítja egy másik számrendszerbe
c. A rejtjelezést az elökódolt számokon végzi el
d. ![]() Kiszámolja a
számokat, és valamilyen módszerrel egymás mellé írva kapja meg az üzenetet.
Kiszámolja a
számokat, és valamilyen módszerrel egymás mellé írva kapja meg az üzenetet.
4. Dekódolás
a. B kap egy rejtjelezett üzenetet, amely 0 . mB-1 számok sorozata (y1 . y2)
b. Ezen számok sorozatán történik a dekódolás
c. 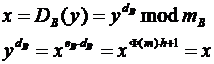
d. (x1 . xn) az elöre megállapított módszerrel visszaalakítjuk, betük sorozatává
Törése:
A titkosság azon alapul, hogy m és e birtokában a támadó nem tudja kiszámolni O(m)-et, és ebböl következöen dB-t sem.
Pl. ha m=15, akkor 15 = 3 x 5, a törés kész
Töréséhez a kétszáz számjegyü szám prímtényezös felbontását kéne meghatározni. (prímfaktorizáció) Gyakorlati titkosságot valósít meg
Többszáz jegyü prímszám elöállítása
Erasztothenészi szita: sorban felírjuk a számokat egymás után, majd a prímek többszöröseit kihúzzuk a listából.
Hagyományos módszer: ![]() -ig vizsgáljuk, hogy n osztható-e prímszámokkal. Amint
találunk egy prím osztót, megállunk: a szám nem prím.
-ig vizsgáljuk, hogy n osztható-e prímszámokkal. Amint
találunk egy prím osztót, megállunk: a szám nem prím.
A módszer nem igényli a valódi prímszámok használatát, de ettöl csak biztonságosabb. Elég, ha a használt számok nagy valószínüséggel prímek.
Miért elég ![]() -ig vizsgálni?
-ig vizsgálni?
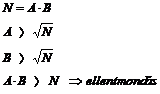
A Fermat-tétel
Valószínüségi prímtesztek
 - Probléma: vannak olyan pszeudoprímek,
amelyek teljesítik a próbát, mégsem prímek.
- Probléma: vannak olyan pszeudoprímek,
amelyek teljesítik a próbát, mégsem prímek.
- A b szám generálása:
válasszunk véletlenszerüen egy páratlan számot, amely 100 jegyü!
a) végezzük el rajta a Fermat-próbát!
b) két eredményünk lehet: kiállja vagy nem a próbát. Ha nem, akkor pl. hozzáadunk 2-t.
Megjegyzések:
Meddig lehet hozzáadni sorozatosan 2-t? Lehet egy olyan hézag, ahol jó sokáig nem találunk számot. Tetszölegesen nagy hézag elképzelhetö a számok között.
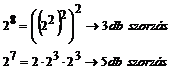 Képlet: kb. (N / lnN)
számú prím van n-ig. Ha
Képlet: kb. (N / lnN)
számú prím van n-ig. Ha ![]() , akkor nagy valószínüséggel lesz prím a hézagban. (Kb.
100-200 szám átlagosan) alatt fel kell bukkannia egy prímnek a hézagban. Ha 140
próbálkozás után nincs prím, válasszunk egy teljesen másik számot.
, akkor nagy valószínüséggel lesz prím a hézagban. (Kb.
100-200 szám átlagosan) alatt fel kell bukkannia egy prímnek a hézagban. Ha 140
próbálkozás után nincs prím, válasszunk egy teljesen másik számot.
Nem igényel nagy számítási teljesítményt
Hatványozás: 2100 = 99db szorzás (n-1)
Hatékonyan: szorzásokra és négyzetre emelésekre vezetjük vissza a hatványozást.
Nagy számokkal való munka:
a) Akkora méretekre bontjuk a számunkat, amelyekkel az aritmetikai egységünk még tud dolgozni, majd az átviteleket kezeljük (ALU)
16. Adatbázis szerverek szerveroldali programozása (Tárolt eljárások, triggerek használata. Adatok feldolgozása kurzorok segítségével.)
Tárolt eljárások létrehozása
Általában:
CREATE PROCEDURE <eljárásnév> [@param_név típus]
[WITH ]
AS
Példa:
CREATE PROCEDURE Vkl (@vk VARCHAR(50))
AS
SELECT nev
FROM Hallgato
WHERE nev LIKE '/' + @vk
Futtatás:
EXEC Vkl(30)
Függvények
Általában:
CREATE FUNCTION(.) RETURNS típus //ilyen típusú a visszatérési érték
BEGIN
RETURN ertek
END
Kurzorok
Általában:
DECLARE nev [INSENSITIVE] [SCROLL] CURSOR
FOR lekerdezes
[FOR READ ONLY] [FOR UPDATE OF mezö1, mezö2, .]
INSENSITIVE: érzéketlen arra, ha megváltoznak az adatok, miközben müködik
SCROLL: engedélyezi az elöre-hátra történö lépkedést
Megnyitás:
OPEN nev
Adatok beolvasása:
FETCH [NEXT | PRIOR | FIRST | LAST | RELATIVE n | ABSOLUTE n]
FROM nev
INTO változó1, változó2, .
@@FETCH_STATUS
Ha 0 sikeres
Ha -1 túlszaladás
Ha -2 hiba (törölték)
Kurzor lezárása:
CLOSE nev
Kurzor felszabadítása:
DEALLOCATE nev
Teljes példa:
DECLARE @alma VARCHAR(50)
FETCH NEXT FROM hkurzor INTO @alma
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT @alma
UPDATE Hallgato
SET nev='1' + @alma
WHERE nev = @alma //vagy WHERE CURRENT OF hkurzor
FETCH NEXT FROM hkurzor
INTO @alma
END
CLOSE hkurzor
DEALLOCATE hkurzor
Példa:
IF @alma LIKE '%Béla'
DELETE FROM Hallgato
WHERE CURRENT OF hkurzor
Triggerek
|
Trigger |
Megszorítás |
|
Meghatározott események bekövetkezése esetén |
Mindig él |
|
Tetszöleges müvelet végrehajtható |
Visszautasítja a tranzakciót, ha megsérti a feltételt |
Szintaxis
CREATE TRIGGER Név ON [táblanév | nézetnév]
[WITH ENCRYPTION]
[FOR ALTER | INSTEAD] [INSERT, UPDATE]
AS
[IF UPDATE(mezönév) AND | OR UPDATE(mezö)]
-- sql parancsok sorozata
-- a deleted és az inserted táblák tartalmazzák a törölt / új adatokat
Példa:
ha a 'Zoli' nevü hallgató '5'-öst kap, akkor ROLLBACK
Hallgato(nev, szul, anyja)
Jegyek(nev, jegy)
a.)
CREATE TRIGGER Szivat ON Jegyek
FOR INSERT, UPDATE
AS
IF EXITS ( SELECT * FROM inserted
WHERE nev='Zoli' AND jegy=5)
ROLLBACK
--az egész tranzakciót visszavonja, bármi is volt még benne
b.)
CREATE TRIGGER Szivat2 ON Jegyek
FOR INSERT
AS
UPDATE Jegyek SET jegy=1
WHERE nev='Zoli' AND jegy=1
c.)
CREATE TRIGGER Szivat3 ON Jegyek
INSTEAD OF INSERT
AS
INSERT INTO Jegyek
SELECT nev, jegy FROM inserted
WHERE NOT (nev='Zoli' AND jegy='5')
d.)
CREATE TRIGGER helytakarekos ON Jegyek
FOR INSERT, UPDATE
AS
DECLARE @nev CHAR(50), @ee INT
DECLARE a CURSOR FOR
SELECT nev FROM inserted
WHERE jegy=1
OPEN a
FETCH a INTO @nev
WHILE @@FETCH_STATUS=0
SET @ee = ( SELECT COUNT(*) FROM jegyek
WHERE nev=@nev AND jegy=1)
IF (@ee > 3) OR (@ee=2 AND @nev='Zoli')
INSERT INTO Torlendo (nev, idopont, egyesek_szama)
VALUES (@nev, GETDATE(), @ee)
FETCH a INTO @nev
END
CLOSE
DEALLOCATE a
17. SQL optimalizálás (Költségalapú és szabályalapú optimalizáció müködésének bemutatása, elemzése.)
Lekérdezés-optimalizálók
szabályalapú: a lekérdezés formája alapján dönti el, hogyan futtatja le, az adatok figyelembe vétele nélkül
költségalapú: az adatbázisra vonatkozó statisztikák szerint próbál optimalizálni. A plusz információk miatt hatékonyabb. Gyakran jobban optimalizál, mint az ember. Eszközei:
1. a táblák összekapcsolásának sorrendje
2. használjon-e indexeket, hasítófüggvényeket
3. mely táblákat töltse be a memóriába
A 1
millió sor B 5
sor A.x
= B.x szabályalapú: a megadott sorrendben végzi el az összehasonlítást. A elemein megy
végig (lassú) költségalapú: felismeri, hogy B kisebb. B elemein megy végig (gyors)
Optimalizálási tippek
1. A konstansokat elöre számítsuk ki
-- nem használ indexeket, mert bonyolult matematikai számításoknak hiszi az alábbiakat
SELECT .
WHERE a > sin(90) * 5 / 2
2. A logikai kifejezéseket egyszerüsítsük a DeMorgan azonosságoknak megfelelöen
NOT (A=1 AND B=2)
helyett
A <> 1 OR B <> 2
3. Logikai kifejezések sorrendje az AND operátor használata során
-- célszerü elöre írni azt a kifejezést, amely nagyobb valószínüséggel hamis, így nem kell megvizsgálni a második kifejezést, ha az elsö hamis. (a leginkább megszorító feltétel legyen az elsö)
SELECT .
WHERE atlag = 5 AND nev = 'Benjamin'
4. Logikai kifejezések sorrendje az OR operátor használata során
-- célszerü elöre írni azt a kifejezést, amelyik a legnagyobb valószínüséggel igaz, a többit utána pedig csökkenö sorrendben. Ugyanez igaz az IN kapcsolatra is: IN (5,4,3,2,1)
A or B or C
5. Logikai kifejezések kiértékelési sorrendje
-- a leggyorsabban kifejthetö legyen elöl, a leglassabb lekérdezés pedig leghátul
SELECT nev FROM Hallgatok
WHERE ( SELECT AVG(jegy)
FROM Jegyek
WHERE hnev = nev) = 5
AND
Nev LIKE '%Benjamin'
5. A BETWEEN.IN operátor
--Sebesség szerint növekvö sorrendben:
WHERE jegy >= 4 AND jegy <= 5
IN (4,5)
jegy BETWEEN 4 AND 5
Adatok beolvasásának módja a táblákból
1. Folytonos olvasás az adatok (rekordok) fizikai sorrendjében (blokkokat olvas be)
akkor hatékony, ha a sok egymás mellett lévö adatot kell beolvasnunk
2. Indexelt beolvasás
nem blokkokat, hanem egyetlen rekordot olvas be
akkor hatékony, ha össze-vissza lévö elemeket kell beolvasni
füzött index: ha az indexek szerint fizikailag rendezett a fájl
3. Hasító függvények használata
Egyedi indexek, pl. növekményes index (auto_increment)
Tökéletes hasítófüggvény: egyenletes leképezés, kevés rés
Egyéb hasítófüggvény: pl. csak körülbelül határozza meg a keresett elem helyét
4. Bitmap indexek használata
BITMAP
INDEX Sanyi-e vagy? 1-esed-e van? 5-ösöd-e van? 0 1 0 0 0 0 1 0 1 0 0 0 0 0 0 1 0 1 Példa: WHERE nev='Sanyi' AND jegy=5 AND kapcsolatot vizsgálunk a
sorokra a következö bitmintával: 1 0 1 Ahol az eredmény igaz, ott egy
keresett elem található

Indexek használata
WHERE T1.a = T2.b
1. egyik táblán sincs index
2. csak A-n van index
3. csak B-n van index
4. mindkét táblán van index
5. A és B azonos indexben szerepel
Az indexhasználat kikényszerítése
1. NULL értékek ne legyenek a lekérdezés eredményében (és a táblákban is)
-- nem használ indexeket
WHERE nev IS NOT NULL
-- használ indexeket
WHERE nev > 'AA'
2. A nemegyenlöség vizsgálata
--sorról sorra végigmegy, mert a nemJózsi sürübben fordul elö
WHERE nev <> 'Józsi'
-- használ indexeket
WHERE (nev < 'Józsi') OR (nev > 'Józsi')
3. Összesítö függvények
a.)
--nem használ indexet
SELECT COUNT(*)
--ezzel az egy mezövel dolgozik, de ha van index, akkor azzal
SELECT COUNT(neptunkod)
b.)
--nem használ indexeket, mert túl bonyolultnak ítéli a lekérdezést
SELECT MIN(adat), MAX(adat)
--használ indexeket
SELECT MIN(adat)
SELECT MAX(adat)
c.)
--HAVING helyett WHERE
SELECT nev, AVG(szam) FROM Sz
GROUP BY nev
HAVING nev LIKE '%Béla'
SELECT nev, AVG(szam) FROM Sz
WHERE nev='%Béla'
(GROUP BY nev) -- kötelezö, de nincs plusz hatása
d.) Urban Legend
-- Tévhit: A SELECT COUNT(*) megoldásnál gyorsabb a SELECT SUM(1)
4. LIKE vs. INDEX
-- nem használ indexeket
SELECT nev FROM Oktato
WHERE szoba LIKE '3%'
--használ indexeket, ha a szobaszámok háromjegyüek
WHERE szoba >= '300' OR szoba <= '399'
5. Kifejezésekben ne használjunk indexelt mezöt
-- a hatarido indexelt mezö, ne legyen azon az oldalon müvelet
WHERE hatarido + 5 < GETDATE
helyett
WHERE hatarido < GETDATE - 5
6. Indexválasztás
--alaphelyzet
SELECT * FROM T1, T2
WHERE T1.x = T2.x
--kikényszeríti az elsö index használatát
SELECT * FROM T1, T2
WHERE T1.x > 0 AND T1.x = T2.x
Felesleges indexek elhagyása - az index használat elkerülése
Ne használjunk feleslegesen indexeket, mert:
az adatok módosítása lassabb lesz, mert az indexeket is módosítani kell
ha mindkét mezön van index, kiveszi a barnákat, majd az 5-ösöket, s ezeknek veszi a metszetét. Lassabb, mintha csak az egyiken lenne index.
WHERE hajszin = 'barna' AND atlag = 5
a barnára ne használjon indexet (a matematikai müvelet miatt):
WHERE hajszin+'' = 'barna'
Tábla-összekapcsolások, allekérdezések optimalizálása
1. Összekapcsolási feltétel megadása
a. tranzitivitás
WHERE A.x = B.x AND A.x = y
b. tranzitivitás
WHERE A.x = y AND B.x = y
Lépésszámok alakulása, ha A: 100-ból 10db x, és ha B:100-ból 5db x:
összekapcsolás + szürés: 100 x 100 = 10.000 sor
szürés + összekapcsolás: 10 x 100 = 1.000 sor
csak szürés: 10 x 5 = 50 sor
2. Plusz információk felhasználása (A-ban kevesebb adat van)
a.
WHERE A.x = B.y AND B.y = C.z
b.
WHERE A.x = B.y AND A.x = C.z
c. ha nem tudjuk, hogy melyikben van kevesebb adat
WHERE A.x = B.y AND A.x = C.z AND B.y = C.z
3. Tábla-összekapcsolás vagy allekérdezés?
a.
SELECT nev, anyja FROM Hallgato
WHERE nev IN (SELECT nev FROM Jegyek WHERE atlag=1)
b. hátránya: rendezi a két táblát
SELECT nev, anyja FROM Hallgato, Jegyek
WHERE Hallgato.nev = Jegyek.nev AND atlag=1
c.
SELECT nev, anyja FROM Hallgato
WHERE EXISTS ( SELECT nev FROM Jegyek
WHERE Hallgato.nev = Jegyek.nev AND atlag=1)
4. Rendezések elkerülése
Összekapcsolás
SELECT DISTINCT: ne használjuk
UNION, INTERSECT, EXACT
a. Mely tankörökben van Béla nevü hallgató?
SELECT DISTINCT tankor FROM Tankor
JOIN Hallgato ON (Tankor.szam = Hallgato.szam)
WHERE nev LIKE '%Béla'
b. Gyorsabb megoldás (egy rendezést megúszunk)
SELECT tankor FROM Tankor
WHERE EXISTS ( SELECT * FROM Hallgato
WHERE Tankor.szam = Hallgato.szam AND nev LIKE '%Béla')
18. Adatbázisok szinkronizációja (Adatbázisok összekapcsolásának módjai. Szerepek, feladatok. Szinkronizációs eljárások.)
Elosztott adatbázisok kezelése
Az elosztott adatbázisok több gépen helyezkednek el.
Oka:
teljesítménynövelés
egyszerübb backup (másik szerver beállítása a döglött helyett)
Formái:
azonnali szinkronizáció (online, valósidejü) [ritka]
laza integráció / késleltetett szinkronizáció (kellöen valósidejü)
o adott idöközönként történik a szinkronizáció
o hibatürö: ha a távoli gép túlterhelt, a szinkronizációt el lehet halasztani
o jól illeszkedik a lassú kapcsolatokhoz
o a távoli gépen nem idöszerü adatok is megjelenhetnek (még nem volt frissítés)
Megvalósítás:
1. Adattöbbszörözés
Müködése: Az összes adatbázis
ugyanazokat az adatokat tartalmazza Az adatlekérés attól a
szervertöl történik, amelyik éppen szabad
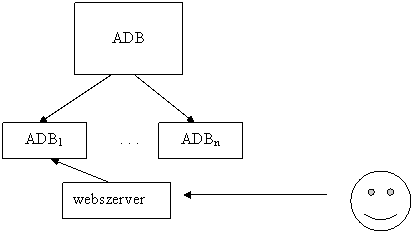
2. Adatok megosztása
Müködése: Az egyes helyeken
különbözö adatokra van szükség A központi szerveren
intelligens ügynök müködik Ha az alárendelt
adatbázisokban változás történik, akkor bizonyos idöközönként
megtörténik a szinkronizáció (éjszaka) Akkor elönyös, ha nincs
mindig szükség a legfrissebb adatokra a központban Hibatürö, elosztott
rendszer
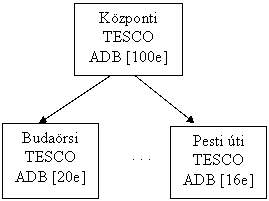
Komponensei:
1. Információkiadás (publisher)
Tárgya:
a. teljes adatbázis
b. teljes tábla
c. vertikális és horizontális partíciók (sorok, oszlopok, mezök)
d. nézettábla
jellemzöi:
a. bizonyos idöközönként vagy konkrét idöpontban történik
b. például minden éjszaka, vagy szerverterheléstöl függöen
2. Feliratkozó-kezelés (subscriber)
a. Jogosultságok
b. Háttérbeli folyamatok
naplózást figyeli process
adatterjesztést végzö process
3. Terjesztés (distributor)
a. helyi vagy távoli (topológia)
b. konfliktuskezelö (egy idöben egy helyen egy adat módosulhat)
c. csak adatokat vagy a séma változásait is érinti?
Lehetséges topológiák:
1. Központi információkiadó
kiegészíthetö kétirányú kapcsolattal
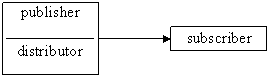
2. Központi elöfizetö
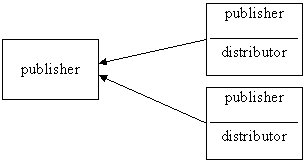
3. Központi információ-kiadó távoli adatterjesztéssel (adattárház)
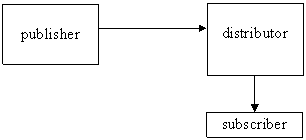
4. Információ-kiadó elöfizetö (elosztott adattárház)
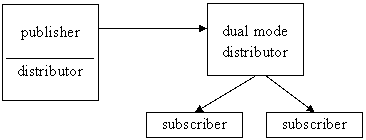
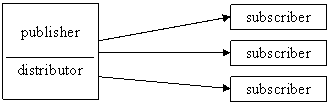
5. Egyesítö többszörözés
a módosításokat felküldik az elöfizetök a szervernek
a szerver pedig leküldi azokat a többi elöfizetönek
Találat: 537